 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge4DSTR: Advancing Generative 4D Gaussians with Spatial-Temporal Rectification for High-Quality and Consistent 4D Generation
Nov 10, 2025Remarkable advances in recent 2D image and 3D shape generation have induced a significant focus on dynamic 4D content generation. However, previous 4D generation methods commonly struggle to maintain spatial-temporal consistency and adapt poorly to rapid temporal variations, due to the lack of effective spatial-temporal modeling. To address these problems, we propose a novel 4D generation network called 4DSTR, which modulates generative 4D Gaussian Splatting with spatial-temporal rectification. Specifically, temporal correlation across generated 4D sequences is designed to rectify deformable scales and rotations and guarantee temporal consistency. Furthermore, an adaptive spatial densification and pruning strategy is proposed to address significant temporal variations by dynamically adding or deleting Gaussian points with the awareness of their pre-frame movements. Extensive experiments demonstrate that our 4DSTR achieves state-of-the-art performance in video-to-4D generation, excelling in reconstruction quality, spatial-temporal consistency, and adaptation to rapid temporal movements.
Robust State Estimation for Legged Robots with Dual Beta Kalman Filter
Nov 18, 2024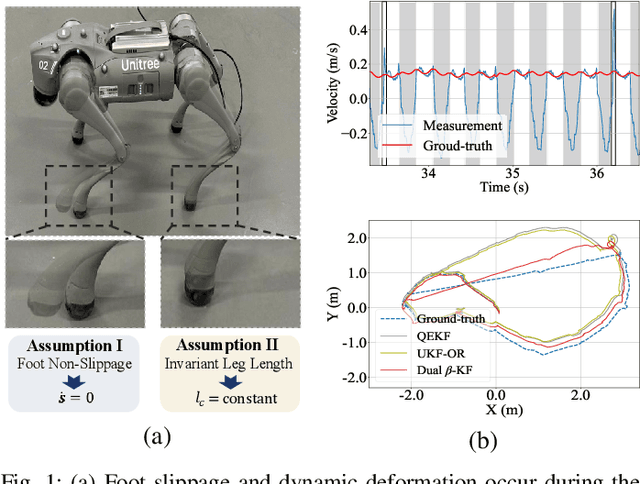
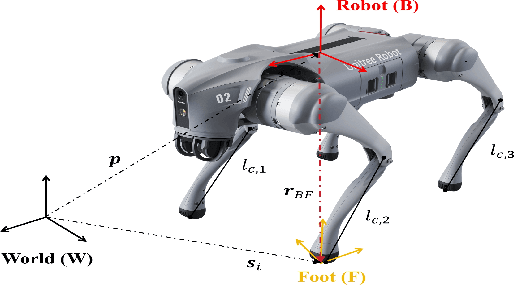
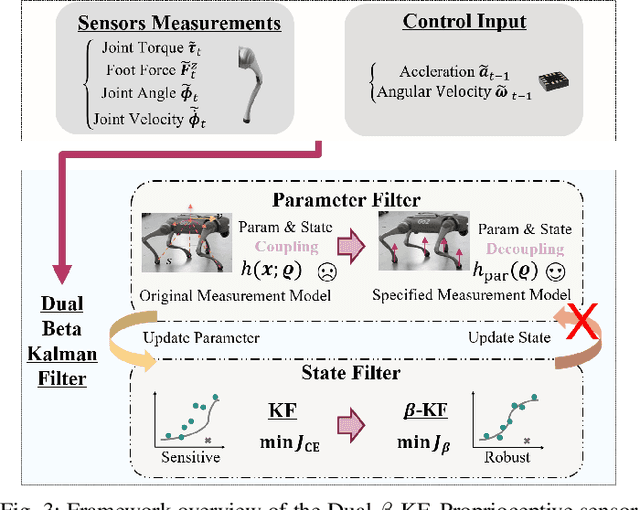

Existing state estimation algorithms for legged robots that rely on proprioceptive sensors often overlook foot slippage and leg deformation in the physical world, leading to large estimation errors. To address this limitation, we propose a comprehensive measurement model that accounts for both foot slippage and variable leg length by analyzing the relative motion between foot contact points and the robot's body center. We show that leg length is an observable quantity, meaning that its value can be explicitly inferred by designing an auxiliary filter. To this end, we introduce a dual estimation framework that iteratively employs a parameter filter to estimate the leg length parameters and a state filter to estimate the robot's state. To prevent error accumulation in this iterative framework, we construct a partial measurement model for the parameter filter using the leg static equation. This approach ensures that leg length estimation relies solely on joint torques and foot contact forces, avoiding the influence of state estimation errors on the parameter estimation. Unlike leg length which can be directly estimated, foot slippage cannot be measured directly with the current sensor configuration. However, since foot slippage occurs at a low frequency, it can be treated as outliers in the measurement data. To mitigate the impact of these outliers, we propose the beta Kalman filter (beta KF), which redefines the estimation loss in canonical Kalman filtering using beta divergence. This divergence can assign low weights to outliers in an adaptive manner, thereby enhancing the robustness of the estimation algorithm. These techniques together form the dual beta-Kalman filter (Dual beta KF), a novel algorithm for robust state estimation in legged robots. Experimental results on the Unitree GO2 robot demonstrate that the Dual beta KF significantly outperforms state-of-the-art methods.
LAformer: Trajectory Prediction for Autonomous Driving with Lane-Aware Scene Constraints
Feb 27, 2023Trajectory prediction for autonomous driving must continuously reason the motion stochasticity of road agents and comply with scene constraints. Existing methods typically rely on one-stage trajectory prediction models, which condition future trajectories on observed trajectories combined with fused scene information. However, they often struggle with complex scene constraints, such as those encountered at intersections. To this end, we present a novel method, called LAformer. It uses a temporally dense lane-aware estimation module to select only the top highly potential lane segments in an HD map, which effectively and continuously aligns motion dynamics with scene information, reducing the representation requirements for the subsequent attention-based decoder by filtering out irrelevant lane segments. Additionally, unlike one-stage prediction models, LAformer utilizes predictions from the first stage as anchor trajectories and adds a second-stage motion refinement module to further explore temporal consistency across the complete time horizon. Extensive experiments on Argoverse 1 and nuScenes demonstrate that LAformer achieves excellent performance for multimodal trajectory prediction.