 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePriorRG: Prior-Guided Contrastive Pre-training and Coarse-to-Fine Decoding for Chest X-ray Report Generation
Aug 07, 2025



Chest X-ray report generation aims to reduce radiologists' workload by automatically producing high-quality preliminary reports. A critical yet underexplored aspect of this task is the effective use of patient-specific prior knowledge -- including clinical context (e.g., symptoms, medical history) and the most recent prior image -- which radiologists routinely rely on for diagnostic reasoning. Most existing methods generate reports from single images, neglecting this essential prior information and thus failing to capture diagnostic intent or disease progression. To bridge this gap, we propose PriorRG, a novel chest X-ray report generation framework that emulates real-world clinical workflows via a two-stage training pipeline. In Stage 1, we introduce a prior-guided contrastive pre-training scheme that leverages clinical context to guide spatiotemporal feature extraction, allowing the model to align more closely with the intrinsic spatiotemporal semantics in radiology reports. In Stage 2, we present a prior-aware coarse-to-fine decoding for report generation that progressively integrates patient-specific prior knowledge with the vision encoder's hidden states. This decoding allows the model to align with diagnostic focus and track disease progression, thereby enhancing the clinical accuracy and fluency of the generated reports. Extensive experiments on MIMIC-CXR and MIMIC-ABN datasets demonstrate that PriorRG outperforms state-of-the-art methods, achieving a 3.6% BLEU-4 and 3.8% F1 score improvement on MIMIC-CXR, and a 5.9% BLEU-1 gain on MIMIC-ABN. Code and checkpoints will be released upon acceptance.
Abn-BLIP: Abnormality-aligned Bootstrapping Language-Image Pre-training for Pulmonary Embolism Diagnosis and Report Generation from CTPA
Mar 03, 2025Medical imaging plays a pivotal role in modern healthcare, with computed tomography pulmonary angiography (CTPA) being a critical tool for diagnosing pulmonary embolism and other thoracic conditions. However, the complexity of interpreting CTPA scans and generating accurate radiology reports remains a significant challenge. This paper introduces Abn-BLIP (Abnormality-aligned Bootstrapping Language-Image Pretraining), an advanced diagnosis model designed to align abnormal findings to generate the accuracy and comprehensiveness of radiology reports. By leveraging learnable queries and cross-modal attention mechanisms, our model demonstrates superior performance in detecting abnormalities, reducing missed findings, and generating structured reports compared to existing methods. Our experiments show that Abn-BLIP outperforms state-of-the-art medical vision-language models and 3D report generation methods in both accuracy and clinical relevance. These results highlight the potential of integrating multimodal learning strategies for improving radiology reporting. The source code is available at https://github.com/zzs95/abn-blip.
Enhanced Contrastive Learning with Multi-view Longitudinal Data for Chest X-ray Report Generation
Feb 27, 2025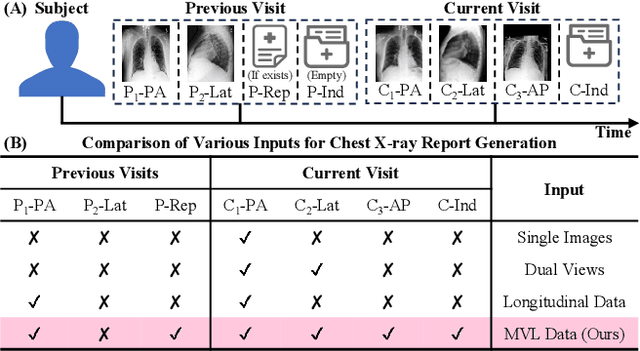

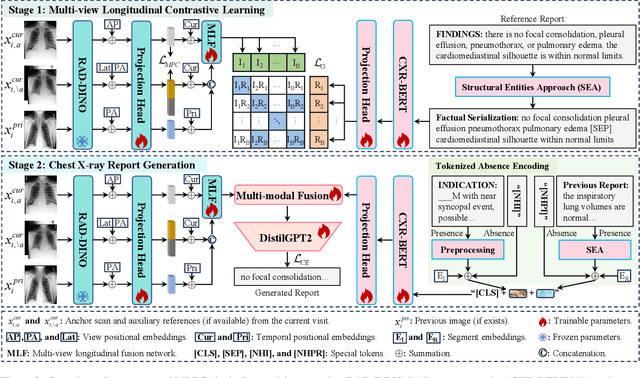
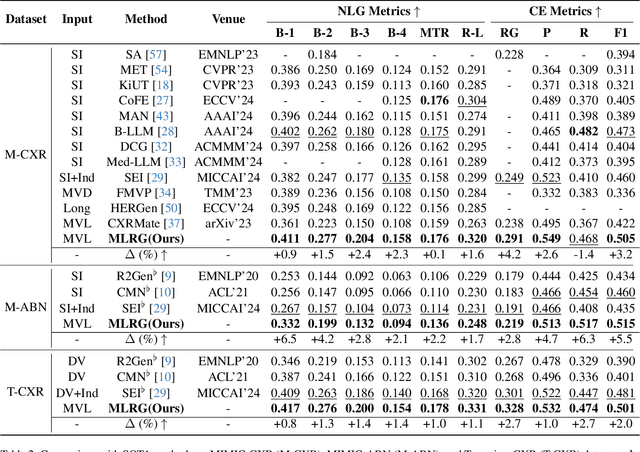
Automated radiology report generation offers an effective solution to alleviate radiologists' workload. However, most existing methods focus primarily on single or fixed-view images to model current disease conditions, which limits diagnostic accuracy and overlooks disease progression. Although some approaches utilize longitudinal data to track disease progression, they still rely on single images to analyze current visits. To address these issues, we propose enhanced contrastive learning with Multi-view Longitudinal data to facilitate chest X-ray Report Generation, named MLRG. Specifically, we introduce a multi-view longitudinal contrastive learning method that integrates spatial information from current multi-view images and temporal information from longitudinal data. This method also utilizes the inherent spatiotemporal information of radiology reports to supervise the pre-training of visual and textual representations. Subsequently, we present a tokenized absence encoding technique to flexibly handle missing patient-specific prior knowledge, allowing the model to produce more accurate radiology reports based on available prior knowledge. Extensive experiments on MIMIC-CXR, MIMIC-ABN, and Two-view CXR datasets demonstrate that our MLRG outperforms recent state-of-the-art methods, achieving a 2.3% BLEU-4 improvement on MIMIC-CXR, a 5.5% F1 score improvement on MIMIC-ABN, and a 2.7% F1 RadGraph improvement on Two-view CXR.
MCL: Multi-view Enhanced Contrastive Learning for Chest X-ray Report Generation
Nov 15, 2024



Radiology reports are crucial for planning treatment strategies and enhancing doctor-patient communication, yet manually writing these reports is burdensome for radiologists. While automatic report generation offers a solution, existing methods often rely on single-view radiographs, limiting diagnostic accuracy. To address this problem, we propose MCL, a Multi-view enhanced Contrastive Learning method for chest X-ray report generation. Specifically, we first introduce multi-view enhanced contrastive learning for visual representation by maximizing agreements between multi-view radiographs and their corresponding report. Subsequently, to fully exploit patient-specific indications (e.g., patient's symptoms) for report generation, we add a transitional ``bridge" for missing indications to reduce embedding space discrepancies caused by their presence or absence. Additionally, we construct Multi-view CXR and Two-view CXR datasets from public sources to support research on multi-view report generation. Our proposed MCL surpasses recent state-of-the-art methods across multiple datasets, achieving a 5.0% F1 RadGraph improvement on MIMIC-CXR, a 7.3% BLEU-1 improvement on MIMIC-ABN, a 3.1% BLEU-4 improvement on Multi-view CXR, and an 8.2% F1 CheXbert improvement on Two-view CXR.
Structural Entities Extraction and Patient Indications Incorporation for Chest X-ray Report Generation
May 23, 2024



The automated generation of imaging reports proves invaluable in alleviating the workload of radiologists. A clinically applicable reports generation algorithm should demonstrate its effectiveness in producing reports that accurately describe radiology findings and attend to patient-specific indications. In this paper, we introduce a novel method, \textbf{S}tructural \textbf{E}ntities extraction and patient indications \textbf{I}ncorporation (SEI) for chest X-ray report generation. Specifically, we employ a structural entities extraction (SEE) approach to eliminate presentation-style vocabulary in reports and improve the quality of factual entity sequences. This reduces the noise in the following cross-modal alignment module by aligning X-ray images with factual entity sequences in reports, thereby enhancing the precision of cross-modal alignment and further aiding the model in gradient-free retrieval of similar historical cases. Subsequently, we propose a cross-modal fusion network to integrate information from X-ray images, similar historical cases, and patient-specific indications. This process allows the text decoder to attend to discriminative features of X-ray images, assimilate historical diagnostic information from similar cases, and understand the examination intention of patients. This, in turn, assists in triggering the text decoder to produce high-quality reports. Experiments conducted on MIMIC-CXR validate the superiority of SEI over state-of-the-art approaches on both natural language generation and clinical efficacy metrics.
Multi-scale Information Sharing and Selection Network with Boundary Attention for Polyp Segmentation
May 18, 2024Polyp segmentation for colonoscopy images is of vital importance in clinical practice. It can provide valuable information for colorectal cancer diagnosis and surgery. While existing methods have achieved relatively good performance, polyp segmentation still faces the following challenges: (1) Varying lighting conditions in colonoscopy and differences in polyp locations, sizes, and morphologies. (2) The indistinct boundary between polyps and surrounding tissue. To address these challenges, we propose a Multi-scale information sharing and selection network (MISNet) for polyp segmentation task. We design a Selectively Shared Fusion Module (SSFM) to enforce information sharing and active selection between low-level and high-level features, thereby enhancing model's ability to capture comprehensive information. We then design a Parallel Attention Module (PAM) to enhance model's attention to boundaries, and a Balancing Weight Module (BWM) to facilitate the continuous refinement of boundary segmentation in the bottom-up process. Experiments on five polyp segmentation datasets demonstrate that MISNet successfully improved the accuracy and clarity of segmentation result, outperforming state-of-the-art methods.
Factual Serialization Enhancement: A Key Innovation for Chest X-ray Report Generation
May 15, 2024The automation of writing imaging reports is a valuable tool for alleviating the workload of radiologists. Crucial steps in this process involve the cross-modal alignment between medical images and reports, as well as the retrieval of similar historical cases. However, the presence of presentation-style vocabulary (e.g., sentence structure and grammar) in reports poses challenges for cross-modal alignment. Additionally, existing methods for similar historical cases retrieval face suboptimal performance owing to the modal gap issue. In response, this paper introduces a novel method, named Factual Serialization Enhancement (FSE), for chest X-ray report generation. FSE begins with the structural entities approach to eliminate presentation-style vocabulary in reports, providing specific input for our model. Then, uni-modal features are learned through cross-modal alignment between images and factual serialization in reports. Subsequently, we present a novel approach to retrieve similar historical cases from the training set, leveraging aligned image features. These features implicitly preserve semantic similarity with their corresponding reference reports, enabling us to calculate similarity solely among aligned features. This effectively eliminates the modal gap issue for knowledge retrieval without the requirement for disease labels. Finally, the cross-modal fusion network is employed to query valuable information from these cases, enriching image features and aiding the text decoder in generating high-quality reports. Experiments on MIMIC-CXR and IU X-ray datasets from both specific and general scenarios demonstrate the superiority of FSE over state-of-the-art approaches in both natural language generation and clinical efficacy metrics.
Region-specific Risk Quantification for Interpretable Prognosis of COVID-19
May 05, 2024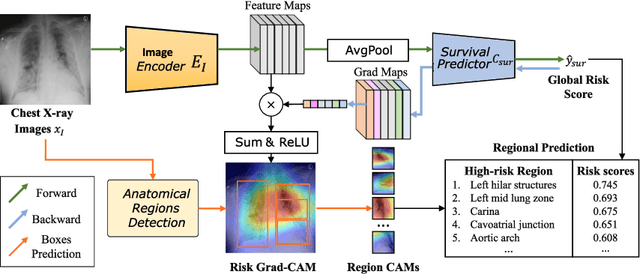
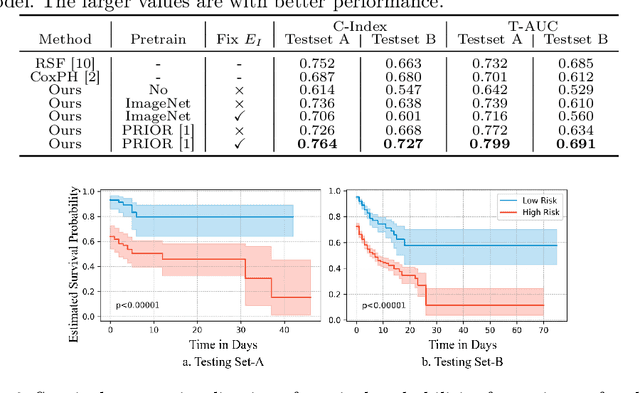

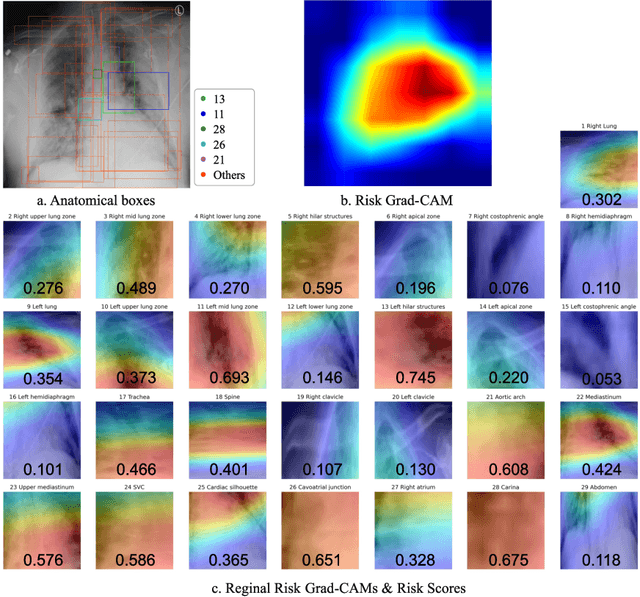
The COVID-19 pandemic has strained global public health, necessitating accurate diagnosis and intervention to control disease spread and reduce mortality rates. This paper introduces an interpretable deep survival prediction model designed specifically for improved understanding and trust in COVID-19 prognosis using chest X-ray (CXR) images. By integrating a large-scale pretrained image encoder, Risk-specific Grad-CAM, and anatomical region detection techniques, our approach produces regional interpretable outcomes that effectively capture essential disease features while focusing on rare but critical abnormal regions. Our model's predictive results provide enhanced clarity and transparency through risk area localization, enabling clinicians to make informed decisions regarding COVID-19 diagnosis with better understanding of prognostic insights. We evaluate the proposed method on a multi-center survival dataset and demonstrate its effectiveness via quantitative and qualitative assessments, achieving superior C-indexes (0.764 and 0.727) and time-dependent AUCs (0.799 and 0.691). These results suggest that our explainable deep survival prediction model surpasses traditional survival analysis methods in risk prediction, improving interpretability for clinical decision making and enhancing AI system trustworthiness.
Drafting and Revision: Laplacian Pyramid Network for Fast High-Quality Artistic Style Transfer
Apr 18, 2021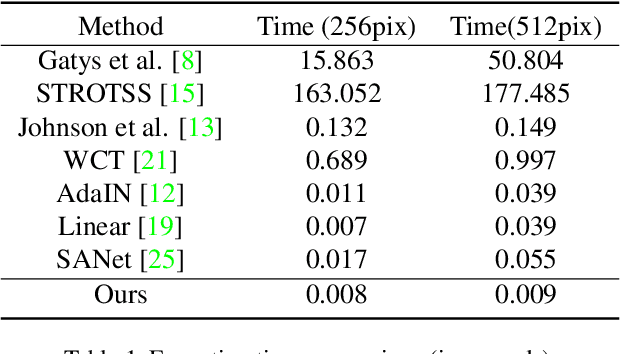
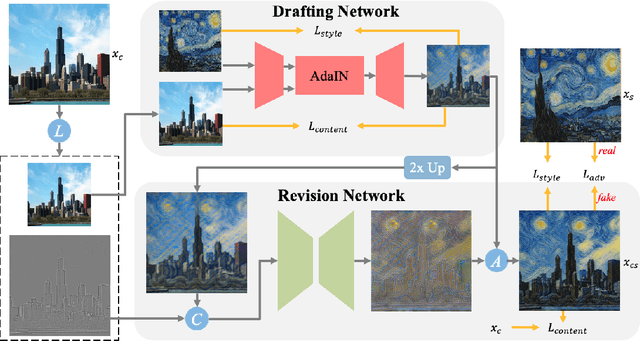

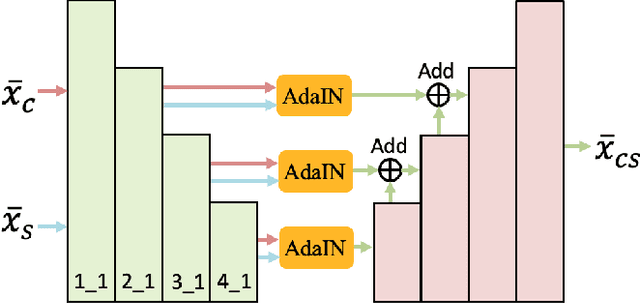
Artistic style transfer aims at migrating the style from an example image to a content image. Currently, optimization-based methods have achieved great stylization quality, but expensive time cost restricts their practical applications. Meanwhile, feed-forward methods still fail to synthesize complex style, especially when holistic global and local patterns exist. Inspired by the common painting process of drawing a draft and revising the details, we introduce a novel feed-forward method named Laplacian Pyramid Network (LapStyle). LapStyle first transfers global style patterns in low-resolution via a Drafting Network. It then revises the local details in high-resolution via a Revision Network, which hallucinates a residual image according to the draft and the image textures extracted by Laplacian filtering. Higher resolution details can be easily generated by stacking Revision Networks with multiple Laplacian pyramid levels. The final stylized image is obtained by aggregating outputs of all pyramid levels. %We also introduce a patch discriminator to better learn local patterns adversarially. Experiments demonstrate that our method can synthesize high quality stylized images in real time, where holistic style patterns are properly transferred.