 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld Tracing: Generative Pixel-Aligned Geometry Beyond the Visible
Jun 11, 2026Image-to-3D methods often trade off faithfulness and completeness: depth estimators are anchored to input pixels but stop at the visible surface, while image-to-3D models generate complete shapes that are often misaligned with the input. We introduce World Tracing, a generative pixel-aligned geometry representation that predicts 3D points aligned with observed pixels while completing geometry beyond the visible surface. For each input pixel, World Tracing predicts an ordered stack of camera-space 3D points, where the first layer represents the visible surface and subsequent layers represent front-to-back intersections with occluded surfaces. We instantiate this representation with a world-tracing diffusion transformer, WT-DiT, which treats multiple geometry layers as separate denoising tokens coupled through factorized and global attention. WT-DiT is trained with pixel-space flow matching and a mixed noise schedule that balances visible-surface reconstruction with occluded-geometry generation. World Tracing achieves strong performance on visible-surface reconstruction and complete geometry generation across object, scene, and dynamic benchmarks, outperforming both depth predictors and image-to-3D generators. It also preserves 2D-to-3D correspondence, enabling text-driven 3D scene editing, geometry-conditioned novel-view video synthesis, and training-free integration with textured-mesh generators.
Orient Anything
Oct 02, 2024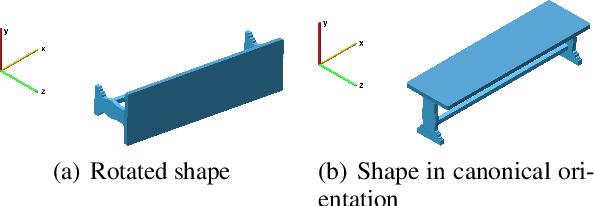
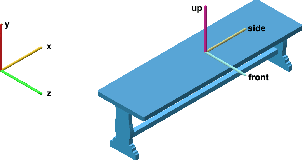
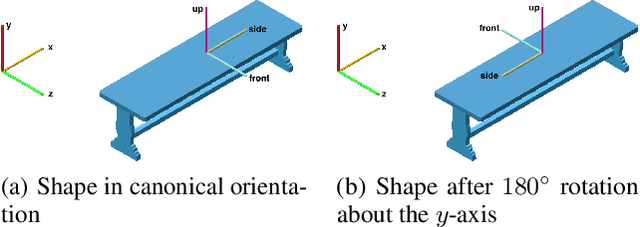
Orientation estimation is a fundamental task in 3D shape analysis which consists of estimating a shape's orientation axes: its side-, up-, and front-axes. Using this data, one can rotate a shape into canonical orientation, where its orientation axes are aligned with the coordinate axes. Developing an orientation algorithm that reliably estimates complete orientations of general shapes remains an open problem. We introduce a two-stage orientation pipeline that achieves state of the art performance on up-axis estimation and further demonstrate its efficacy on full-orientation estimation, where one seeks all three orientation axes. Unlike previous work, we train and evaluate our method on all of Shapenet rather than a subset of classes. We motivate our engineering contributions by theory describing fundamental obstacles to orientation estimation for rotationally-symmetric shapes, and show how our method avoids these obstacles.
Segment Any Mesh: Zero-shot Mesh Part Segmentation via Lifting Segment Anything 2 to 3D
Aug 24, 2024We propose Segment Any Mesh (SAMesh), a novel zero-shot method for mesh part segmentation that overcomes the limitations of shape analysis-based, learning-based, and current zero-shot approaches. SAMesh operates in two phases: multimodal rendering and 2D-to-3D lifting. In the first phase, multiview renders of the mesh are individually processed through Segment Anything 2 (SAM2) to generate 2D masks. These masks are then lifted into a mesh part segmentation by associating masks that refer to the same mesh part across the multiview renders. We find that applying SAM2 to multimodal feature renders of normals and shape diameter scalars achieves better results than using only untextured renders of meshes. By building our method on top of SAM2, we seamlessly inherit any future improvements made to 2D segmentation. We compare our method with a robust, well-evaluated shape analysis method, Shape Diameter Function (ShapeDiam), and show our method is comparable to or exceeds its performance. Since current benchmarks contain limited object diversity, we also curate and release a dataset of generated meshes and use it to demonstrate our method's improved generalization over ShapeDiam via human evaluation. We release the code and dataset at https://github.com/gtangg12/samesh
Decomposed Prompting to Answer Questions on a Course Discussion Board
Jul 30, 2024We propose and evaluate a question-answering system that uses decomposed prompting to classify and answer student questions on a course discussion board. Our system uses a large language model (LLM) to classify questions into one of four types: conceptual, homework, logistics, and not answerable. This enables us to employ a different strategy for answering questions that fall under different types. Using a variant of GPT-3, we achieve $81\%$ classification accuracy. We discuss our system's performance on answering conceptual questions from a machine learning course and various failure modes.
* 6 pages. Published at International Conference on Artificial Intelligence in Education 2023. Code repository: https://github.com/brandonjaipersaud/piazza-qabot-gpt
Multi-modality Regional Alignment Network for Covid X-Ray Survival Prediction and Report Generation
May 23, 2024In response to the worldwide COVID-19 pandemic, advanced automated technologies have emerged as valuable tools to aid healthcare professionals in managing an increased workload by improving radiology report generation and prognostic analysis. This study proposes Multi-modality Regional Alignment Network (MRANet), an explainable model for radiology report generation and survival prediction that focuses on high-risk regions. By learning spatial correlation in the detector, MRANet visually grounds region-specific descriptions, providing robust anatomical regions with a completion strategy. The visual features of each region are embedded using a novel survival attention mechanism, offering spatially and risk-aware features for sentence encoding while maintaining global coherence across tasks. A cross LLMs alignment is employed to enhance the image-to-text transfer process, resulting in sentences rich with clinical detail and improved explainability for radiologist. Multi-center experiments validate both MRANet's overall performance and each module's composition within the model, encouraging further advancements in radiology report generation research emphasizing clinical interpretation and trustworthiness in AI models applied to medical studies. The code is available at https://github.com/zzs95/MRANet.
Region-specific Risk Quantification for Interpretable Prognosis of COVID-19
May 05, 2024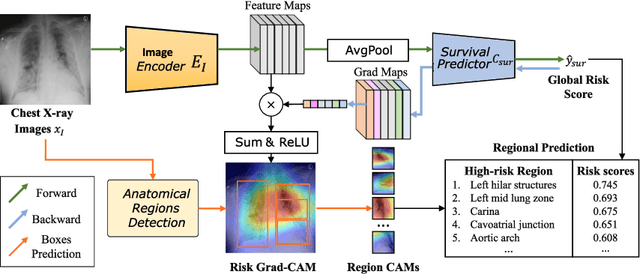
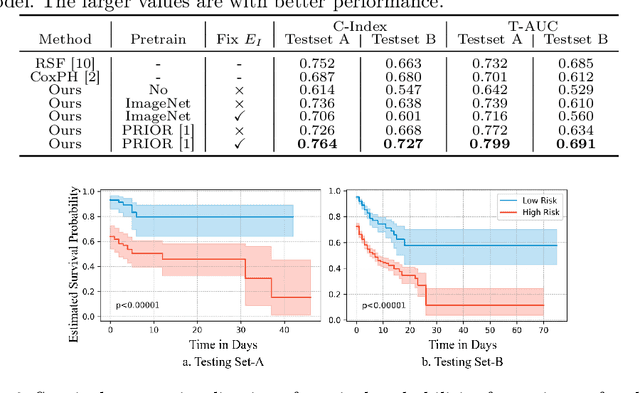

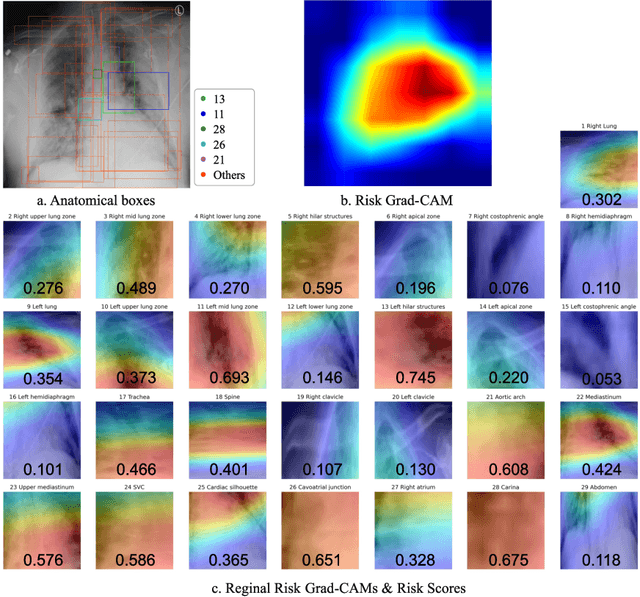
The COVID-19 pandemic has strained global public health, necessitating accurate diagnosis and intervention to control disease spread and reduce mortality rates. This paper introduces an interpretable deep survival prediction model designed specifically for improved understanding and trust in COVID-19 prognosis using chest X-ray (CXR) images. By integrating a large-scale pretrained image encoder, Risk-specific Grad-CAM, and anatomical region detection techniques, our approach produces regional interpretable outcomes that effectively capture essential disease features while focusing on rare but critical abnormal regions. Our model's predictive results provide enhanced clarity and transparency through risk area localization, enabling clinicians to make informed decisions regarding COVID-19 diagnosis with better understanding of prognostic insights. We evaluate the proposed method on a multi-center survival dataset and demonstrate its effectiveness via quantitative and qualitative assessments, achieving superior C-indexes (0.764 and 0.727) and time-dependent AUCs (0.799 and 0.691). These results suggest that our explainable deep survival prediction model surpasses traditional survival analysis methods in risk prediction, improving interpretability for clinical decision making and enhancing AI system trustworthiness.
Wassersplines for Stylized Neural Animation
Jan 28, 2022
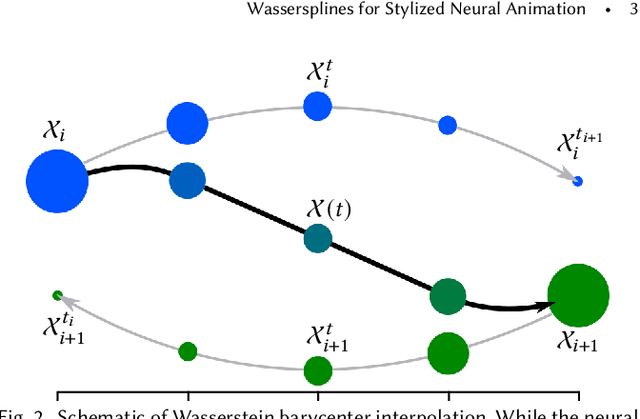
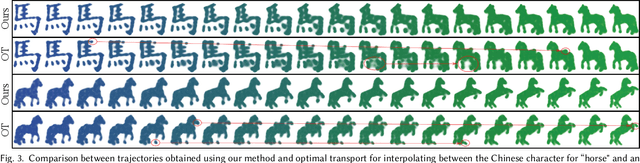
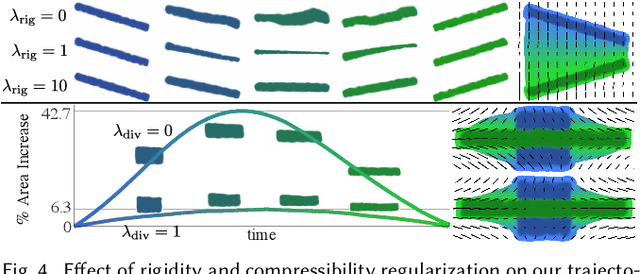
Much of computer-generated animation is created by manipulating meshes with rigs. While this approach works well for animating articulated objects like animals, it has limited flexibility for animating less structured creatures such as the Drunn in "Raya and the Last Dragon." We introduce Wassersplines, a novel trajectory inference method for animating unstructured densities based on recent advances in continuous normalizing flows and optimal transport. The key idea is to train a neurally-parameterized velocity field that represents the motion between keyframes. Trajectories are then computed by pushing keyframes through the velocity field. We solve an additional Wasserstein barycenter interpolation problem to guarantee strict adherence to keyframes. Our tool can stylize trajectories through a variety of PDE-based regularizers to create different visual effects. We demonstrate our tool on various keyframe interpolation problems to produce temporally-coherent animations without meshing or rigging.