 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVector Quantized Feature Fields for Fast 3D Semantic Lifting
Mar 09, 2025
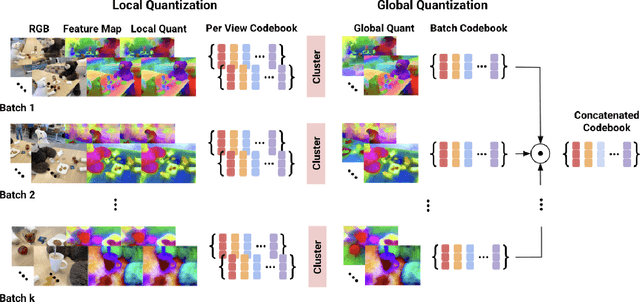


We generalize lifting to semantic lifting by incorporating per-view masks that indicate relevant pixels for lifting tasks. These masks are determined by querying corresponding multiscale pixel-aligned feature maps, which are derived from scene representations such as distilled feature fields and feature point clouds. However, storing per-view feature maps rendered from distilled feature fields is impractical, and feature point clouds are expensive to store and query. To enable lightweight on-demand retrieval of pixel-aligned relevance masks, we introduce the Vector-Quantized Feature Field. We demonstrate the effectiveness of the Vector-Quantized Feature Field on complex indoor and outdoor scenes. Semantic lifting, when paired with a Vector-Quantized Feature Field, can unlock a myriad of applications in scene representation and embodied intelligence. Specifically, we showcase how our method enables text-driven localized scene editing and significantly improves the efficiency of embodied question answering.
Segment Any Mesh: Zero-shot Mesh Part Segmentation via Lifting Segment Anything 2 to 3D
Aug 24, 2024We propose Segment Any Mesh (SAMesh), a novel zero-shot method for mesh part segmentation that overcomes the limitations of shape analysis-based, learning-based, and current zero-shot approaches. SAMesh operates in two phases: multimodal rendering and 2D-to-3D lifting. In the first phase, multiview renders of the mesh are individually processed through Segment Anything 2 (SAM2) to generate 2D masks. These masks are then lifted into a mesh part segmentation by associating masks that refer to the same mesh part across the multiview renders. We find that applying SAM2 to multimodal feature renders of normals and shape diameter scalars achieves better results than using only untextured renders of meshes. By building our method on top of SAM2, we seamlessly inherit any future improvements made to 2D segmentation. We compare our method with a robust, well-evaluated shape analysis method, Shape Diameter Function (ShapeDiam), and show our method is comparable to or exceeds its performance. Since current benchmarks contain limited object diversity, we also curate and release a dataset of generated meshes and use it to demonstrate our method's improved generalization over ShapeDiam via human evaluation. We release the code and dataset at https://github.com/gtangg12/samesh
Efficient 3D Instance Mapping and Localization with Neural Fields
Apr 01, 2024
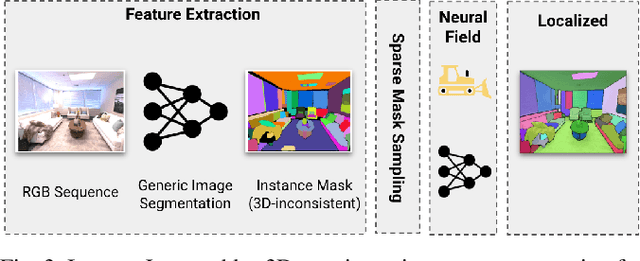


We tackle the problem of learning an implicit scene representation for 3D instance segmentation from a sequence of posed RGB images. Towards this, we introduce 3DIML, a novel framework that efficiently learns a label field that may be rendered from novel viewpoints to produce view-consistent instance segmentation masks. 3DIML significantly improves upon training and inference runtimes of existing implicit scene representation based methods. Opposed to prior art that optimizes a neural field in a self-supervised manner, requiring complicated training procedures and loss function design, 3DIML leverages a two-phase process. The first phase, InstanceMap, takes as input 2D segmentation masks of the image sequence generated by a frontend instance segmentation model, and associates corresponding masks across images to 3D labels. These almost view-consistent pseudolabel masks are then used in the second phase, InstanceLift, to supervise the training of a neural label field, which interpolates regions missed by InstanceMap and resolves ambiguities. Additionally, we introduce InstanceLoc, which enables near realtime localization of instance masks given a trained label field and an off-the-shelf image segmentation model by fusing outputs from both. We evaluate 3DIML on sequences from the Replica and ScanNet datasets and demonstrate 3DIML's effectiveness under mild assumptions for the image sequences. We achieve a large practical speedup over existing implicit scene representation methods with comparable quality, showcasing its potential to facilitate faster and more effective 3D scene understanding.
HeartFit: An Accurate Platform for Heart Murmur Diagnosis Utilizing Deep Learning
Jul 24, 2019Cardiovascular disease (CD) is the number one leading cause of death worldwide, accounting for more than 17 million deaths in 2015. Critical indicators of CD include heart murmurs, intense sounds emitted by the heart during periods of irregular blood flow. Current diagnosis of heart murmurs relies on echocardiography (ECHO), which costs thousands of dollars and medical professionals to analyze the results, making it very unsuitable for areas with inadequate medical facilities. Thus, there is a need for an accessible alternative. Based on a simple interface and deep learning, HeartFit allows users to administer diagnoses themselves. An inexpensive, custom designed stethoscope in conjunction with a mobile application allows users to record and upload audio of their heart to a database. Using a deep learning network architecture, the database classifies the audio and returns the diagnosis to the user. The model consists of a deep recurrent convolutional neural network trained on 300 prelabeled heartbeat audio samples. After the model was validated on a previously unseen set of 100 heartbeat audio samples, it achieved a f beta score of 0.9545 and an accuracy of 95.5 percent. This value exceeds that of clinical examination accuracy, which is around 83 percent to 91 percent and costs orders of magnitude less than ECHO, demonstrating the effectiveness of the HeartFit platform. Through the platform, users can obtain immediate, accurate diagnosis of heart murmurs without any professional medical assistance, revolutionizing how we combat CD.