 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient 3D Instance Mapping and Localization with Neural Fields
Paper and Code

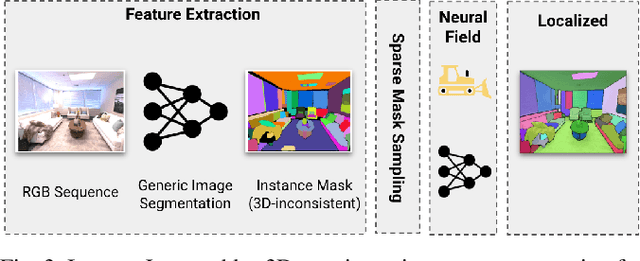


We tackle the problem of learning an implicit scene representation for 3D instance segmentation from a sequence of posed RGB images. Towards this, we introduce 3DIML, a novel framework that efficiently learns a label field that may be rendered from novel viewpoints to produce view-consistent instance segmentation masks. 3DIML significantly improves upon training and inference runtimes of existing implicit scene representation based methods. Opposed to prior art that optimizes a neural field in a self-supervised manner, requiring complicated training procedures and loss function design, 3DIML leverages a two-phase process. The first phase, InstanceMap, takes as input 2D segmentation masks of the image sequence generated by a frontend instance segmentation model, and associates corresponding masks across images to 3D labels. These almost view-consistent pseudolabel masks are then used in the second phase, InstanceLift, to supervise the training of a neural label field, which interpolates regions missed by InstanceMap and resolves ambiguities. Additionally, we introduce InstanceLoc, which enables near realtime localization of instance masks given a trained label field and an off-the-shelf image segmentation model by fusing outputs from both. We evaluate 3DIML on sequences from the Replica and ScanNet datasets and demonstrate 3DIML's effectiveness under mild assumptions for the image sequences. We achieve a large practical speedup over existing implicit scene representation methods with comparable quality, showcasing its potential to facilitate faster and more effective 3D scene understanding.