 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVector Quantized Feature Fields for Fast 3D Semantic Lifting
Paper and Code
Mar 09, 2025
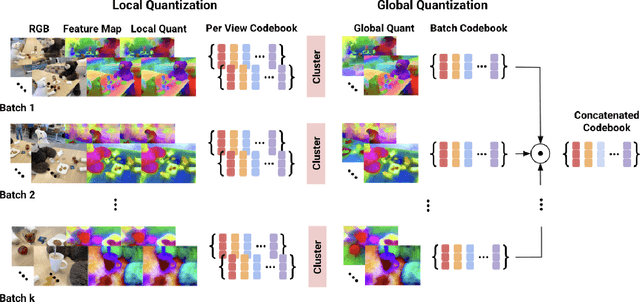


We generalize lifting to semantic lifting by incorporating per-view masks that indicate relevant pixels for lifting tasks. These masks are determined by querying corresponding multiscale pixel-aligned feature maps, which are derived from scene representations such as distilled feature fields and feature point clouds. However, storing per-view feature maps rendered from distilled feature fields is impractical, and feature point clouds are expensive to store and query. To enable lightweight on-demand retrieval of pixel-aligned relevance masks, we introduce the Vector-Quantized Feature Field. We demonstrate the effectiveness of the Vector-Quantized Feature Field on complex indoor and outdoor scenes. Semantic lifting, when paired with a Vector-Quantized Feature Field, can unlock a myriad of applications in scene representation and embodied intelligence. Specifically, we showcase how our method enables text-driven localized scene editing and significantly improves the efficiency of embodied question answering.