 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Shielded Image Compression: Defending Against Exploitation from Vision-Language Pretrained Models
Jun 18, 2025The improved semantic understanding of vision-language pretrained (VLP) models has made it increasingly difficult to protect publicly posted images from being exploited by search engines and other similar tools. In this context, this paper seeks to protect users' privacy by implementing defenses at the image compression stage to prevent exploitation. Specifically, we propose a flexible coding method, termed Privacy-Shielded Image Compression (PSIC), that can produce bitstreams with multiple decoding options. By default, the bitstream is decoded to preserve satisfactory perceptual quality while preventing interpretation by VLP models. Our method also retains the original image compression functionality. With a customizable input condition, the proposed scheme can reconstruct the image that preserves its full semantic information. A Conditional Latent Trigger Generation (CLTG) module is proposed to produce bias information based on customizable conditions to guide the decoding process into different reconstructed versions, and an Uncertainty-Aware Encryption-Oriented (UAEO) optimization function is designed to leverage the soft labels inferred from the target VLP model's uncertainty on the training data. This paper further incorporates an adaptive multi-objective optimization strategy to obtain improved encrypting performance and perceptual quality simultaneously within a unified training process. The proposed scheme is plug-and-play and can be seamlessly integrated into most existing Learned Image Compression (LIC) models. Extensive experiments across multiple downstream tasks have demonstrated the effectiveness of our design.
Fast Omni-Directional Image Super-Resolution: Adapting the Implicit Image Function with Pixel and Semantic-Wise Spherical Geometric Priors
Feb 09, 2025



In the context of Omni-Directional Image (ODI) Super-Resolution (SR), the unique challenge arises from the non-uniform oversampling characteristics caused by EquiRectangular Projection (ERP). Considerable efforts in designing complex spherical convolutions or polyhedron reprojection offer significant performance improvements but at the expense of cumbersome processing procedures and slower inference speeds. Under these circumstances, this paper proposes a new ODI-SR model characterized by its capacity to perform Fast and Arbitrary-scale ODI-SR processes, denoted as FAOR. The key innovation lies in adapting the implicit image function from the planar image domain to the ERP image domain by incorporating spherical geometric priors at both the latent representation and image reconstruction stages, in a low-overhead manner. Specifically, at the latent representation stage, we adopt a pair of pixel-wise and semantic-wise sphere-to-planar distortion maps to perform affine transformations on the latent representation, thereby incorporating it with spherical properties. Moreover, during the image reconstruction stage, we introduce a geodesic-based resampling strategy, aligning the implicit image function with spherical geometrics without introducing additional parameters. As a result, the proposed FAOR outperforms the state-of-the-art ODI-SR models with a much faster inference speed. Extensive experimental results and ablation studies have demonstrated the effectiveness of our design.
Unified Coding for Both Human Perception and Generalized Machine Analytics with CLIP Supervision
Jan 08, 2025



The image compression model has long struggled with adaptability and generalization, as the decoded bitstream typically serves only human or machine needs and fails to preserve information for unseen visual tasks. Therefore, this paper innovatively introduces supervision obtained from multimodal pre-training models and incorporates adaptive multi-objective optimization tailored to support both human visual perception and machine vision simultaneously with a single bitstream, denoted as Unified and Generalized Image Coding for Machine (UG-ICM). Specifically, to get rid of the reliance between compression models with downstream task supervision, we introduce Contrastive Language-Image Pre-training (CLIP) models into the training constraint for improved generalization. Global-to-instance-wise CLIP supervision is applied to help obtain hierarchical semantics that make models more generalizable for the tasks relying on the information of different granularity. Furthermore, for supporting both human and machine visions with only a unifying bitstream, we incorporate a conditional decoding strategy that takes as conditions human or machine preferences, enabling the bitstream to be decoded into different versions for corresponding preferences. As such, our proposed UG-ICM is fully trained in a self-supervised manner, i.e., without awareness of any specific downstream models and tasks. The extensive experiments have shown that the proposed UG-ICM is capable of achieving remarkable improvements in various unseen machine analytics tasks, while simultaneously providing perceptually satisfying images.
Sliced Maximal Information Coefficient: A Training-Free Approach for Image Quality Assessment Enhancement
Aug 19, 2024
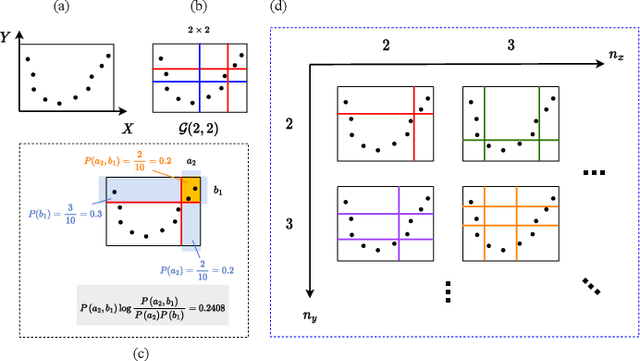
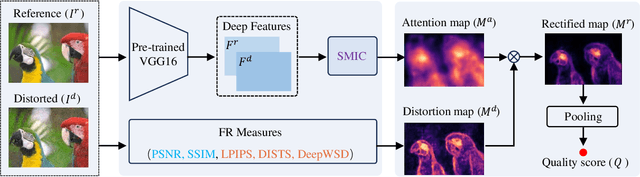
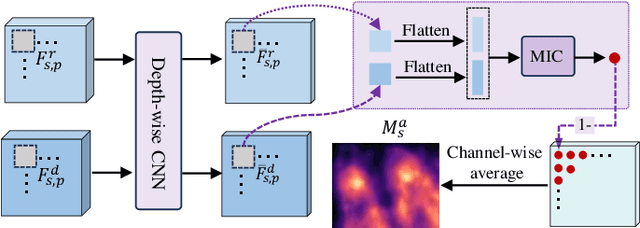
Full-reference image quality assessment (FR-IQA) models generally operate by measuring the visual differences between a degraded image and its reference. However, existing FR-IQA models including both the classical ones (eg, PSNR and SSIM) and deep-learning based measures (eg, LPIPS and DISTS) still exhibit limitations in capturing the full perception characteristics of the human visual system (HVS). In this paper, instead of designing a new FR-IQA measure, we aim to explore a generalized human visual attention estimation strategy to mimic the process of human quality rating and enhance existing IQA models. In particular, we model human attention generation by measuring the statistical dependency between the degraded image and the reference image. The dependency is captured in a training-free manner by our proposed sliced maximal information coefficient and exhibits surprising generalization in different IQA measures. Experimental results verify the performance of existing IQA models can be consistently improved when our attention module is incorporated. The source code is available at https://github.com/KANGX99/SMIC.
Semi-automatic Data Annotation System for Multi-Target Multi-Camera Vehicle Tracking
Sep 20, 2022
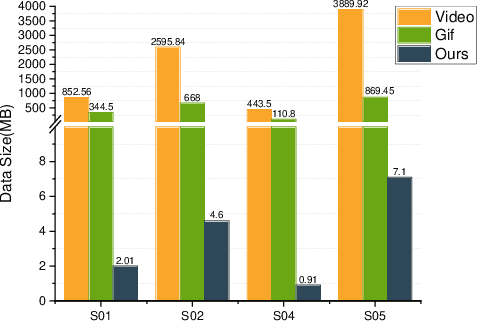
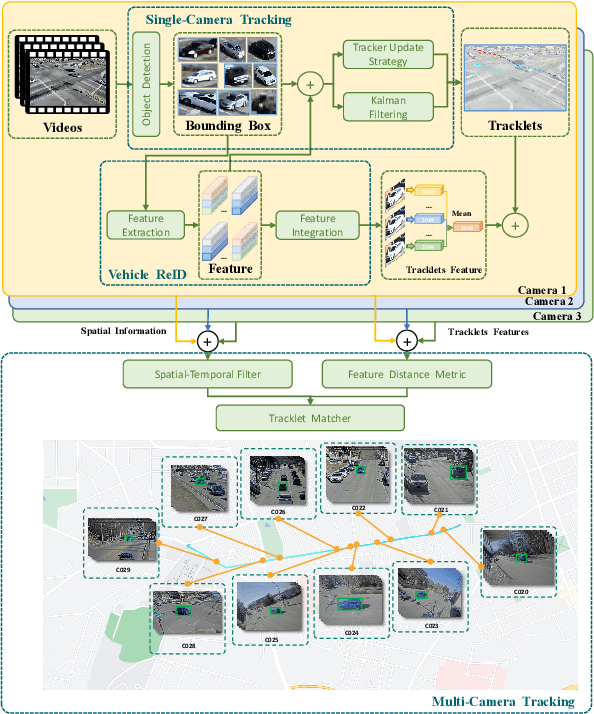
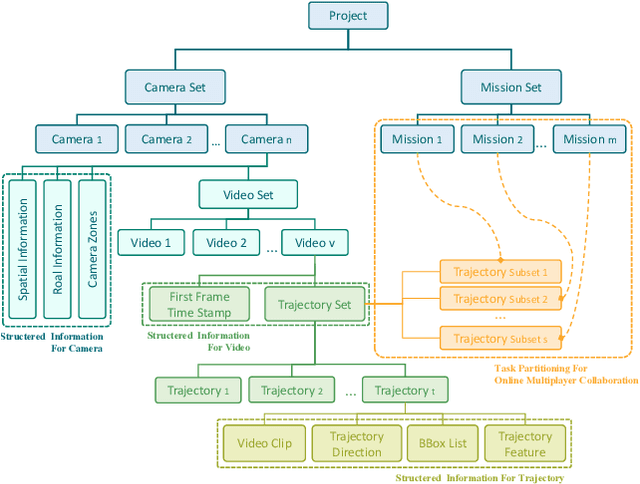
Multi-target multi-camera tracking (MTMCT) plays an important role in intelligent video analysis, surveillance video retrieval, and other application scenarios. Nowadays, the deep-learning-based MTMCT has been the mainstream and has achieved fascinating improvements regarding tracking accuracy and efficiency. However, according to our investigation, the lacking of datasets focusing on real-world application scenarios limits the further improvements for current learning-based MTMCT models. Specifically, the learning-based MTMCT models training by common datasets usually cannot achieve satisfactory results in real-world application scenarios. Motivated by this, this paper presents a semi-automatic data annotation system to facilitate the real-world MTMCT dataset establishment. The proposed system first employs a deep-learning-based single-camera trajectory generation method to automatically extract trajectories from surveillance videos. Subsequently, the system provides a recommendation list in the following manual cross-camera trajectory matching process. The recommendation list is generated based on side information, including camera location, timestamp relation, and background scene. In the experimental stage, extensive results further demonstrate the efficiency of the proposed system.