 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Omni-Directional Image Super-Resolution: Adapting the Implicit Image Function with Pixel and Semantic-Wise Spherical Geometric Priors
Feb 09, 2025



In the context of Omni-Directional Image (ODI) Super-Resolution (SR), the unique challenge arises from the non-uniform oversampling characteristics caused by EquiRectangular Projection (ERP). Considerable efforts in designing complex spherical convolutions or polyhedron reprojection offer significant performance improvements but at the expense of cumbersome processing procedures and slower inference speeds. Under these circumstances, this paper proposes a new ODI-SR model characterized by its capacity to perform Fast and Arbitrary-scale ODI-SR processes, denoted as FAOR. The key innovation lies in adapting the implicit image function from the planar image domain to the ERP image domain by incorporating spherical geometric priors at both the latent representation and image reconstruction stages, in a low-overhead manner. Specifically, at the latent representation stage, we adopt a pair of pixel-wise and semantic-wise sphere-to-planar distortion maps to perform affine transformations on the latent representation, thereby incorporating it with spherical properties. Moreover, during the image reconstruction stage, we introduce a geodesic-based resampling strategy, aligning the implicit image function with spherical geometrics without introducing additional parameters. As a result, the proposed FAOR outperforms the state-of-the-art ODI-SR models with a much faster inference speed. Extensive experimental results and ablation studies have demonstrated the effectiveness of our design.
Semi-automatic Data Annotation System for Multi-Target Multi-Camera Vehicle Tracking
Sep 20, 2022
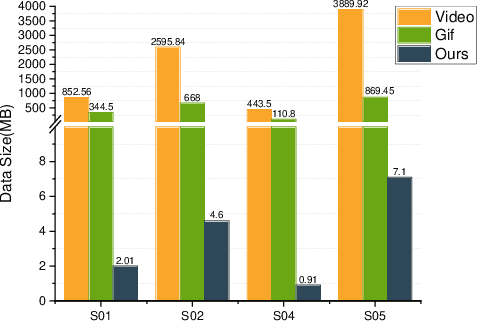
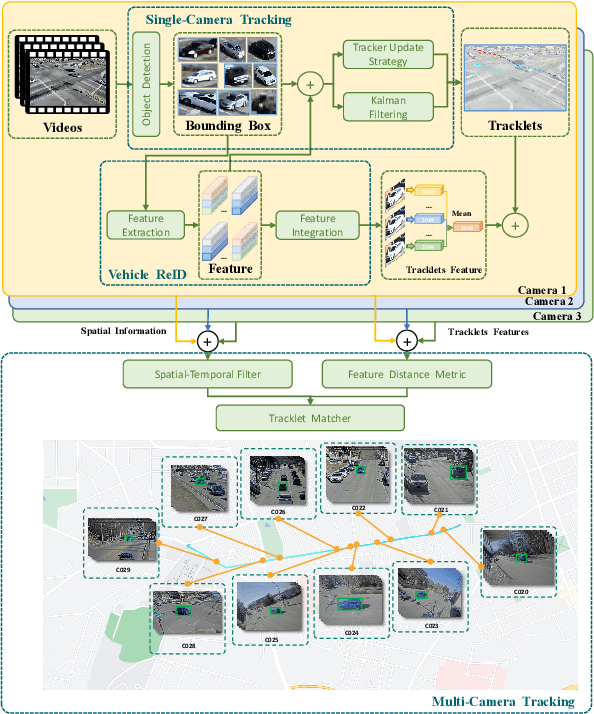
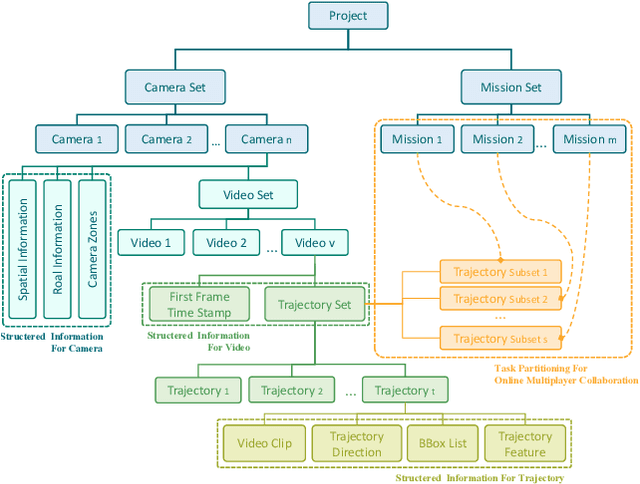
Multi-target multi-camera tracking (MTMCT) plays an important role in intelligent video analysis, surveillance video retrieval, and other application scenarios. Nowadays, the deep-learning-based MTMCT has been the mainstream and has achieved fascinating improvements regarding tracking accuracy and efficiency. However, according to our investigation, the lacking of datasets focusing on real-world application scenarios limits the further improvements for current learning-based MTMCT models. Specifically, the learning-based MTMCT models training by common datasets usually cannot achieve satisfactory results in real-world application scenarios. Motivated by this, this paper presents a semi-automatic data annotation system to facilitate the real-world MTMCT dataset establishment. The proposed system first employs a deep-learning-based single-camera trajectory generation method to automatically extract trajectories from surveillance videos. Subsequently, the system provides a recommendation list in the following manual cross-camera trajectory matching process. The recommendation list is generated based on side information, including camera location, timestamp relation, and background scene. In the experimental stage, extensive results further demonstrate the efficiency of the proposed system.