 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly-Supervised 3D Scene Graph Generation via Visual-Linguistic Assisted Pseudo-labeling
Apr 03, 2024



Learning to build 3D scene graphs is essential for real-world perception in a structured and rich fashion. However, previous 3D scene graph generation methods utilize a fully supervised learning manner and require a large amount of entity-level annotation data of objects and relations, which is extremely resource-consuming and tedious to obtain. To tackle this problem, we propose 3D-VLAP, a weakly-supervised 3D scene graph generation method via Visual-Linguistic Assisted Pseudo-labeling. Specifically, our 3D-VLAP exploits the superior ability of current large-scale visual-linguistic models to align the semantics between texts and 2D images, as well as the naturally existing correspondences between 2D images and 3D point clouds, and thus implicitly constructs correspondences between texts and 3D point clouds. First, we establish the positional correspondence from 3D point clouds to 2D images via camera intrinsic and extrinsic parameters, thereby achieving alignment of 3D point clouds and 2D images. Subsequently, a large-scale cross-modal visual-linguistic model is employed to indirectly align 3D instances with the textual category labels of objects by matching 2D images with object category labels. The pseudo labels for objects and relations are then produced for 3D-VLAP model training by calculating the similarity between visual embeddings and textual category embeddings of objects and relations encoded by the visual-linguistic model, respectively. Ultimately, we design an edge self-attention based graph neural network to generate scene graphs of 3D point cloud scenes. Extensive experiments demonstrate that our 3D-VLAP achieves comparable results with current advanced fully supervised methods, meanwhile significantly alleviating the pressure of data annotation.
Semi-automatic Data Annotation System for Multi-Target Multi-Camera Vehicle Tracking
Sep 20, 2022
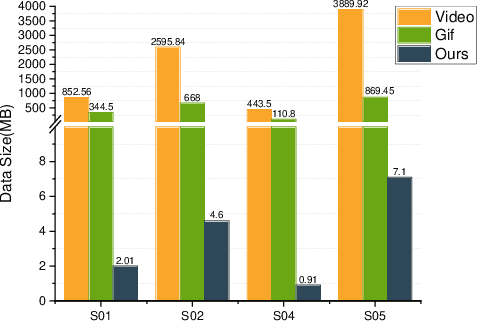
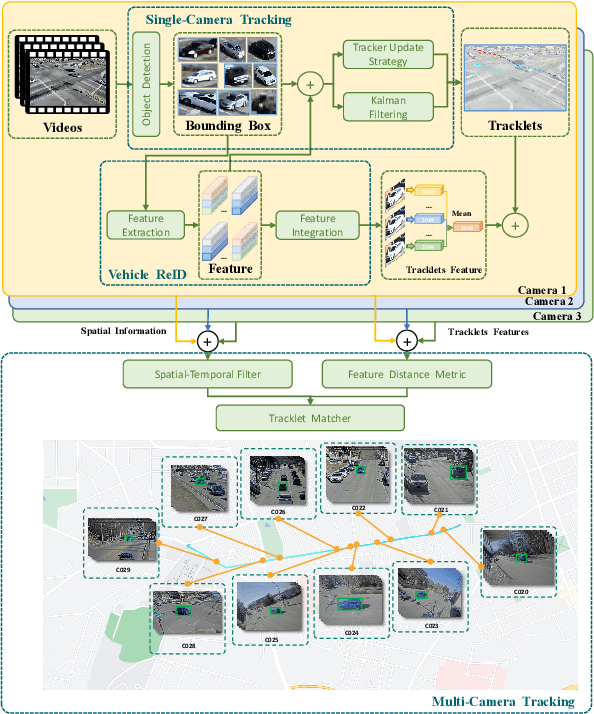
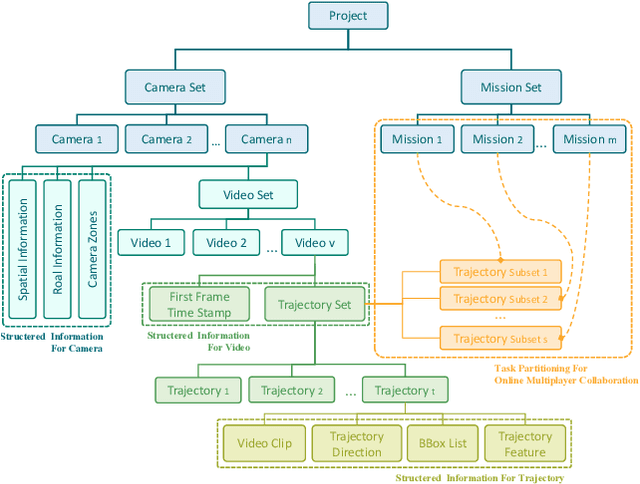
Multi-target multi-camera tracking (MTMCT) plays an important role in intelligent video analysis, surveillance video retrieval, and other application scenarios. Nowadays, the deep-learning-based MTMCT has been the mainstream and has achieved fascinating improvements regarding tracking accuracy and efficiency. However, according to our investigation, the lacking of datasets focusing on real-world application scenarios limits the further improvements for current learning-based MTMCT models. Specifically, the learning-based MTMCT models training by common datasets usually cannot achieve satisfactory results in real-world application scenarios. Motivated by this, this paper presents a semi-automatic data annotation system to facilitate the real-world MTMCT dataset establishment. The proposed system first employs a deep-learning-based single-camera trajectory generation method to automatically extract trajectories from surveillance videos. Subsequently, the system provides a recommendation list in the following manual cross-camera trajectory matching process. The recommendation list is generated based on side information, including camera location, timestamp relation, and background scene. In the experimental stage, extensive results further demonstrate the efficiency of the proposed system.
ASP-based Discovery of Semi-Markovian Causal Models under Weaker Assumptions
Jun 06, 2019

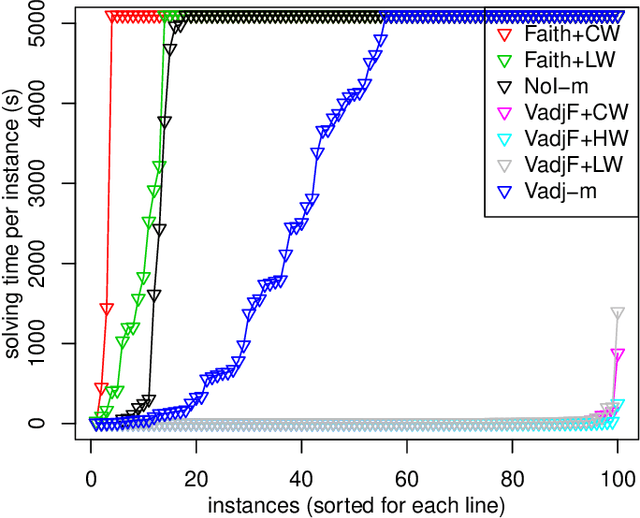

In recent years the possibility of relaxing the so-called Faithfulness assumption in automated causal discovery has been investigated. The investigation showed (1) that the Faithfulness assumption can be weakened in various ways that in an important sense preserve its power, and (2) that weakening of Faithfulness may help to speed up methods based on Answer Set Programming. However, this line of work has so far only considered the discovery of causal models without latent variables. In this paper, we study weakenings of Faithfulness for constraint-based discovery of semi-Markovian causal models, which accommodate the possibility of latent variables, and show that both (1) and (2) remain the case in this more realistic setting.