 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYou Only Erase Once: Erasing Anything without Bringing Unexpected Content
Mar 29, 2026We present YOEO, an approach for object erasure. Unlike recent diffusion-based methods which struggle to erase target objects without generating unexpected content within the masked regions due to lack of sufficient paired training data and explicit constraint on content generation, our method allows to produce high-quality object erasure results free of unwanted objects or artifacts while faithfully preserving the overall context coherence to the surrounding content. We achieve this goal by training an object erasure diffusion model on unpaired data containing only large-scale real-world images, under the supervision of a sundries detector and a context coherence loss that are built upon an entity segmentation model. To enable more efficient training and inference, a diffusion distillation strategy is employed to train for a few-step erasure diffusion model. Extensive experiments show that our method outperforms the state-of-the-art object erasure methods. Code will be available at https://zyxunh.github.io/YOEO-ProjectPage/.
ByteEdit: Boost, Comply and Accelerate Generative Image Editing
Apr 07, 2024



Recent advancements in diffusion-based generative image editing have sparked a profound revolution, reshaping the landscape of image outpainting and inpainting tasks. Despite these strides, the field grapples with inherent challenges, including: i) inferior quality; ii) poor consistency; iii) insufficient instrcution adherence; iv) suboptimal generation efficiency. To address these obstacles, we present ByteEdit, an innovative feedback learning framework meticulously designed to Boost, Comply, and Accelerate Generative Image Editing tasks. ByteEdit seamlessly integrates image reward models dedicated to enhancing aesthetics and image-text alignment, while also introducing a dense, pixel-level reward model tailored to foster coherence in the output. Furthermore, we propose a pioneering adversarial and progressive feedback learning strategy to expedite the model's inference speed. Through extensive large-scale user evaluations, we demonstrate that ByteEdit surpasses leading generative image editing products, including Adobe, Canva, and MeiTu, in both generation quality and consistency. ByteEdit-Outpainting exhibits a remarkable enhancement of 388% and 135% in quality and consistency, respectively, when compared to the baseline model. Experiments also verfied that our acceleration models maintains excellent performance results in terms of quality and consistency.
Adaptive Period Embedding for Representing Oriented Objects in Aerial Images
Jun 22, 2019


We propose a novel method for representing oriented objects in aerial images named Adaptive Period Embedding (APE). While traditional object detection methods represent object with horizontal bounding boxes, the objects in aerial images are oritented. Calculating the angle of object is an yet challenging task. While almost all previous object detectors for aerial images directly regress the angle of objects, they use complex rules to calculate the angle, and their performance is limited by the rule design. In contrast, our method is based on the angular periodicity of oriented objects. The angle is represented by two two-dimensional periodic vectors whose periods are different, the vector is continuous as shape changes. The label generation rule is more simple and reasonable compared with previous methods. The proposed method is general and can be applied to other oriented detector. Besides, we propose a novel IoU calculation method for long objects named length independent IoU (LIIoU). We intercept part of the long side of the target box to get the maximum IoU between the proposed box and the intercepted target box. Thereby, some long boxes will have corresponding positive samples. Our method reaches the 1st place of DOAI2019 competition task1 (oriented object) held in workshop on Detecting Objects in Aerial Images in conjunction with IEEE CVPR 2019.
TextMountain: Accurate Scene Text Detection via Instance Segmentation
Nov 30, 2018
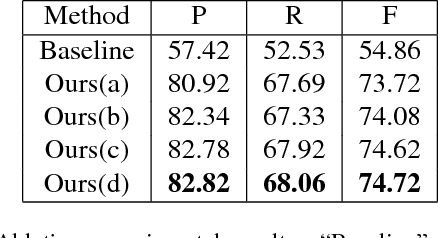
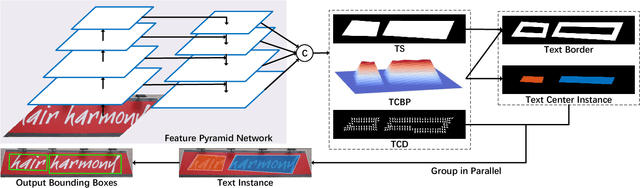
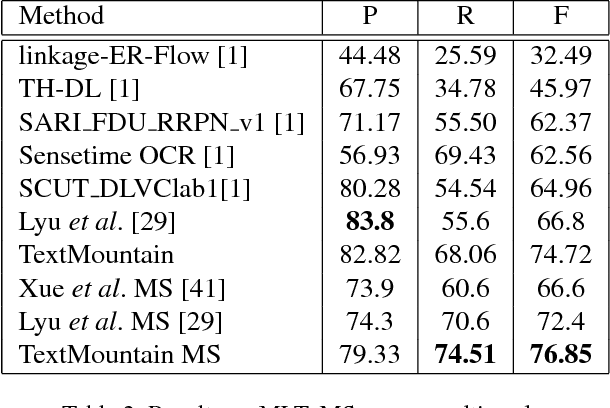
In this paper, we propose a novel scene text detection method named TextMountain. The key idea of TextMountain is making full use of border-center information. Different from previous works that treat center-border as a binary classification problem, we predict text center-border probability (TCBP) and text center-direction (TCD). The TCBP is just like a mountain whose top is text center and foot is text border. The mountaintop can separate text instances which cannot be easily achieved using semantic segmentation map and its rising direction can plan a road to top for each pixel on mountain foot at the group stage. The TCD helps TCBP learning better. Our label rules will not lead to the ambiguous problem with the transformation of angle, so the proposed method is robust to multi-oriented text and can also handle well with curved text. In inference stage, each pixel at the mountain foot needs to search the path to the mountaintop and this process can be efficiently completed in parallel, yielding the efficiency of our method compared with others. The experiments on MLT, ICDAR2015, RCTW-17 and SCUT-CTW1500 databases demonstrate that the proposed method achieves better or comparable performance in terms of both accuracy and efficiency. It is worth mentioning our method achieves an F-measure of 76.85% on MLT which outperforms the previous methods by a large margin. Code will be made available.
DenseRAN for Offline Handwritten Chinese Character Recognition
Aug 13, 2018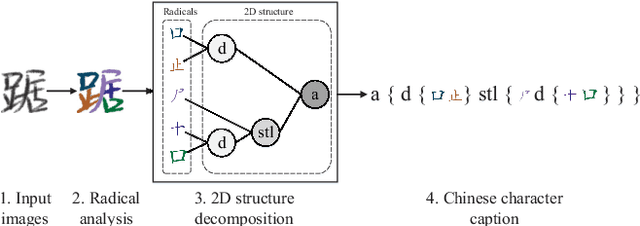
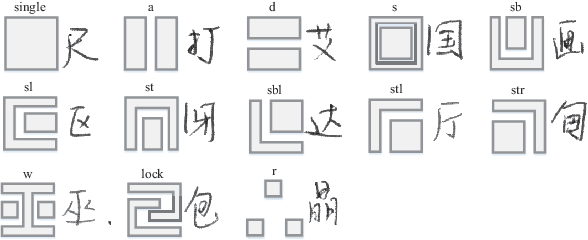
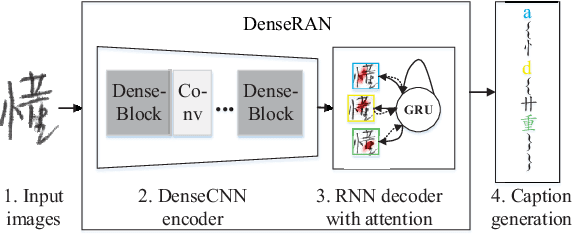

Recently, great success has been achieved in offline handwritten Chinese character recognition by using deep learning methods. Chinese characters are mainly logographic and consist of basic radicals, however, previous research mostly treated each Chinese character as a whole without explicitly considering its internal two-dimensional structure and radicals. In this study, we propose a novel radical analysis network with densely connected architecture (DenseRAN) to analyze Chinese character radicals and its two-dimensional structures simultaneously. DenseRAN first encodes input image to high-level visual features by employing DenseNet as an encoder. Then a decoder based on recurrent neural networks is employed, aiming at generating captions of Chinese characters by detecting radicals and two-dimensional structures through attention mechanism. The manner of treating a Chinese character as a composition of two-dimensional structures and radicals can reduce the size of vocabulary and enable DenseRAN to possess the capability of recognizing unseen Chinese character classes, only if the corresponding radicals have been seen in training set. Evaluated on ICDAR-2013 competition database, the proposed approach significantly outperforms whole-character modeling approach with a relative character error rate (CER) reduction of 18.54%. Meanwhile, for the case of recognizing 3277 unseen Chinese characters in CASIA-HWDB1.2 database, DenseRAN can achieve a character accuracy of about 41% while the traditional whole-character method has no capability to handle them.
Radical analysis network for zero-shot learning in printed Chinese character recognition
Mar 29, 2018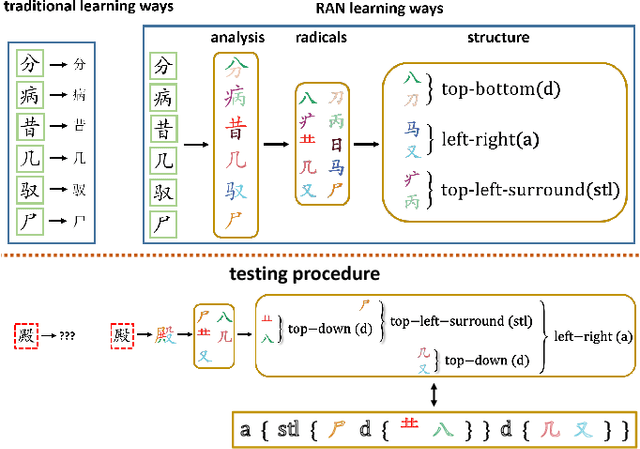
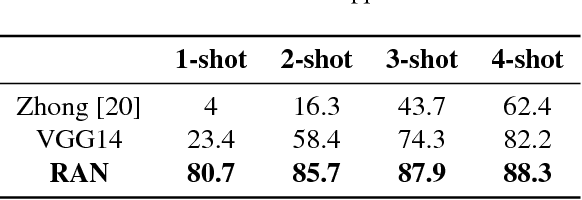
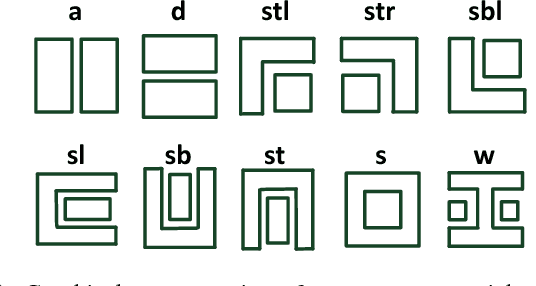
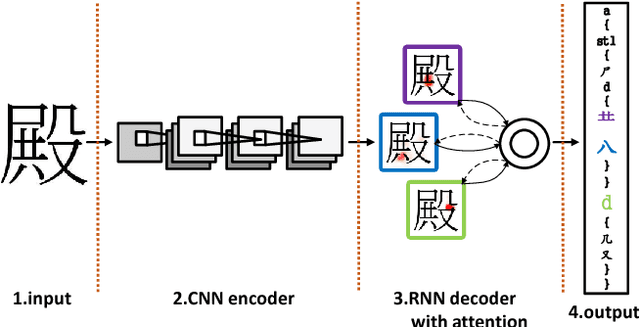
Chinese characters have a huge set of character categories, more than 20,000 and the number is still increasing as more and more novel characters continue being created. However, the enormous characters can be decomposed into a compact set of about 500 fundamental and structural radicals. This paper introduces a novel radical analysis network (RAN) to recognize printed Chinese characters by identifying radicals and analyzing two-dimensional spatial structures among them. The proposed RAN first extracts visual features from input by employing convolutional neural networks as an encoder. Then a decoder based on recurrent neural networks is employed, aiming at generating captions of Chinese characters by detecting radicals and two-dimensional structures through a spatial attention mechanism. The manner of treating a Chinese character as a composition of radicals rather than a single character class largely reduces the size of vocabulary and enables RAN to possess the ability of recognizing unseen Chinese character classes, namely zero-shot learning.
Sliding Line Point Regression for Shape Robust Scene Text Detection
Jan 30, 2018
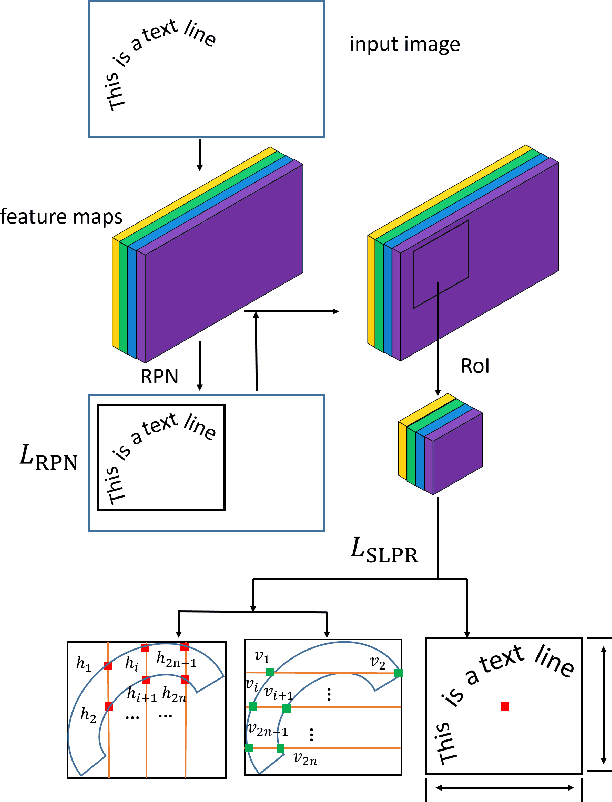
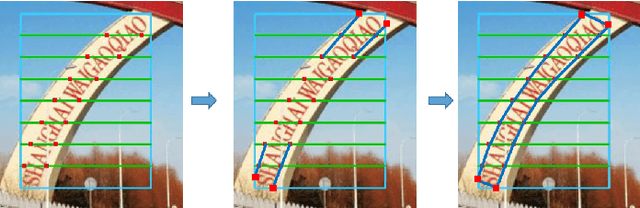

Traditional text detection methods mostly focus on quadrangle text. In this study we propose a novel method named sliding line point regression (SLPR) in order to detect arbitrary-shape text in natural scene. SLPR regresses multiple points on the edge of text line and then utilizes these points to sketch the outlines of the text. The proposed SLPR can be adapted to many object detection architectures such as Faster R-CNN and R-FCN. Specifically, we first generate the smallest rectangular box including the text with region proposal network (RPN), then isometrically regress the points on the edge of text by using the vertically and horizontally sliding lines. To make full use of information and reduce redundancy, we calculate x-coordinate or y-coordinate of target point by the rectangular box position, and just regress the remaining y-coordinate or x-coordinate. Accordingly we can not only reduce the parameters of system, but also restrain the points which will generate more regular polygon. Our approach achieved competitive results on traditional ICDAR2015 Incidental Scene Text benchmark and curve text detection dataset CTW1500.
Trajectory-based Radical Analysis Network for Online Handwritten Chinese Character Recognition
Jan 22, 2018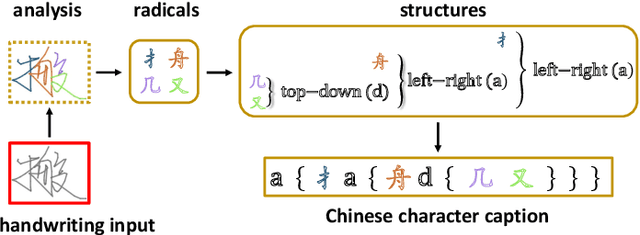

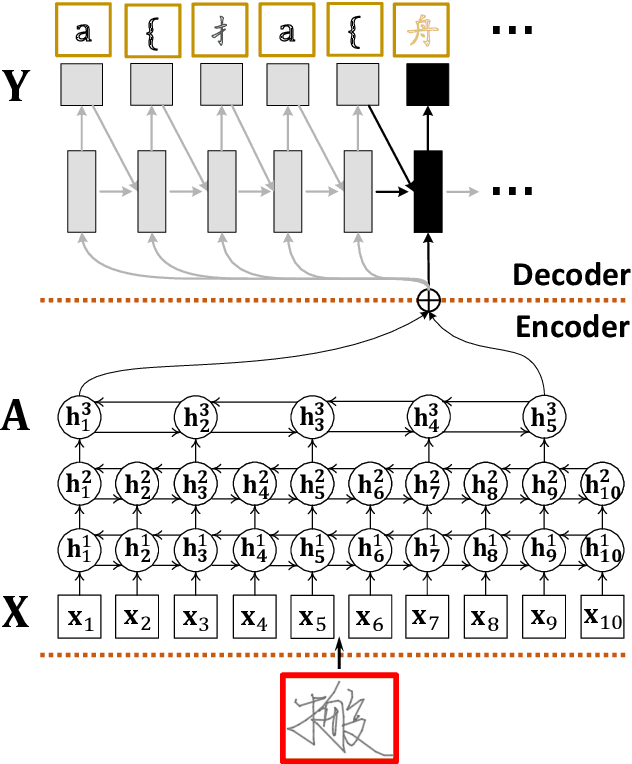
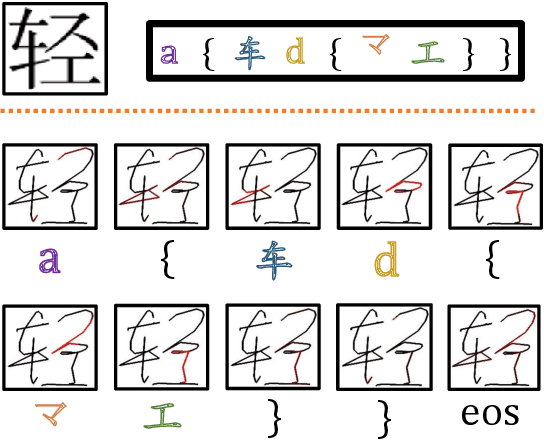
Recently, great progress has been made for online handwritten Chinese character recognition due to the emergence of deep learning techniques. However, previous research mostly treated each Chinese character as one class without explicitly considering its inherent structure, namely the radical components with complicated geometry. In this study, we propose a novel trajectory-based radical analysis network (TRAN) to firstly identify radicals and analyze two-dimensional structures among radicals simultaneously, then recognize Chinese characters by generating captions of them based on the analysis of their internal radicals. The proposed TRAN employs recurrent neural networks (RNNs) as both an encoder and a decoder. The RNN encoder makes full use of online information by directly transforming handwriting trajectory into high-level features. The RNN decoder aims at generating the caption by detecting radicals and spatial structures through an attention model. The manner of treating a Chinese character as a two-dimensional composition of radicals can reduce the size of vocabulary and enable TRAN to possess the capability of recognizing unseen Chinese character classes, only if the corresponding radicals have been seen. Evaluated on CASIA-OLHWDB database, the proposed approach significantly outperforms the state-of-the-art whole-character modeling approach with a relative character error rate (CER) reduction of 10%. Meanwhile, for the case of recognition of 500 unseen Chinese characters, TRAN can achieve a character accuracy of about 60% while the traditional whole-character method has no capability to handle them.