 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Canonical Neural Units and Multi-Scale Training for Handwritten Text Recognition
Oct 24, 2024The segmentation-free research efforts for addressing handwritten text recognition can be divided into three categories: connectionist temporal classification (CTC), hidden Markov model and encoder-decoder methods. In this paper, inspired by the above three modeling methods, we propose a new recognition network by using a novel three-dimensional (3D) attention module and global-local context information. Based on the feature maps of the last convolutional layer, a series of 3D blocks with different resolutions are split. Then, these 3D blocks are fed into the 3D attention module to generate sequential visual features. Finally, by integrating the visual features and the corresponding global-local context features, a well-designed representation can be obtained. Main canonical neural units including attention mechanisms, fully-connected layer, recurrent unit and convolutional layer are efficiently organized into a network and can be jointly trained by the CTC loss and the cross-entropy loss. Experiments on the latest Chinese handwritten text datasets (the SCUT-HCCDoc and the SCUT-EPT) and one English handwritten text dataset (the IAM) show that the proposed method can make a new milestone.
Leveraging Structure Knowledge and Deep Models for the Detection of Abnormal Handwritten Text
Oct 15, 2024Currently, the destruction of the sequence structure in handwritten text has become one of the main bottlenecks restricting the recognition task. The typical situations include additional specific markers (the text swapping modification) and the text overlap caused by character modifications like deletion, replacement, and insertion. In this paper, we propose a two-stage detection algorithm that combines structure knowledge and deep models for the above mentioned text. Firstly, different structure prototypes are roughly located from handwritten text images. Based on the detection results of the first stage, in the second stage, we adopt different strategies. Specifically, a shape regression network trained by a novel semi-supervised contrast training strategy is introduced and the positional relationship between the characters is fully employed. Experiments on two handwritten text datasets show that the proposed method can greatly improve the detection performance. The new dataset is available at https://github.com/Wukong90.
Joint Architecture and Knowledge Distillation in Convolutional Neural Network for Offline Handwritten Chinese Text Recognition
Dec 17, 2019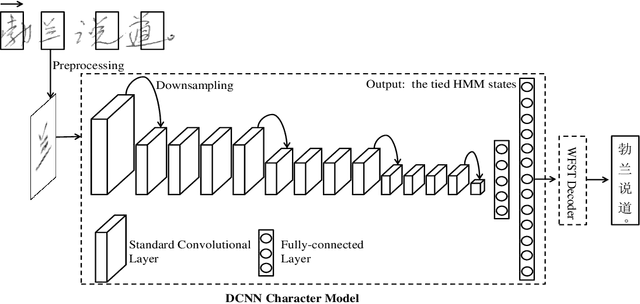
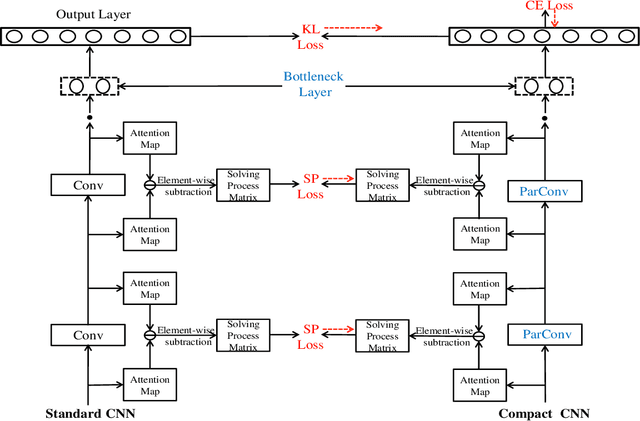
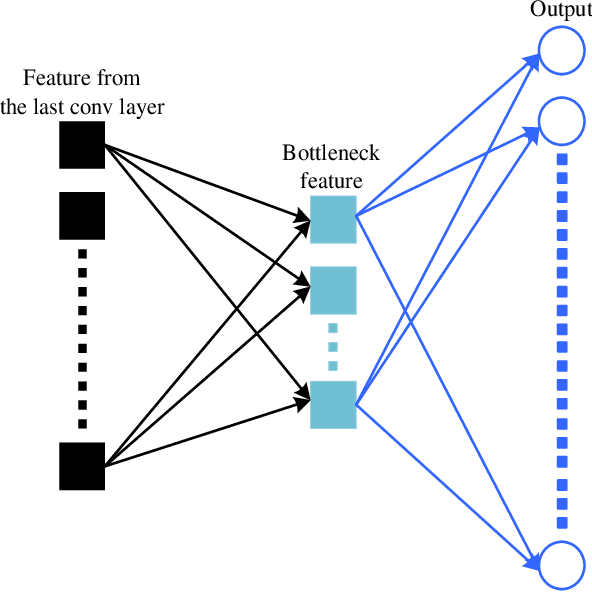
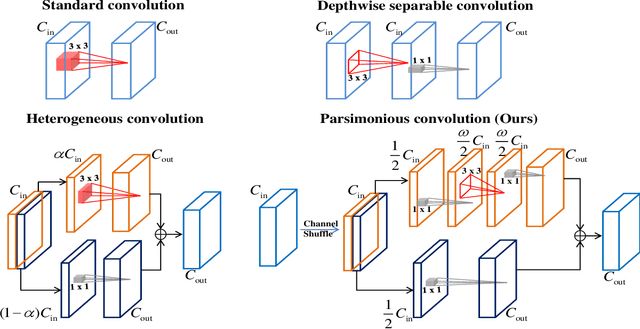
The technique of distillation helps transform cumbersome neural network into compact network so that the model can be deployed on alternative hardware devices. The main advantages of distillation based approaches include simple training process, supported by most off-the-shelf deep learning softwares and no special requirement of hardwares. In this paper, we propose a guideline to distill the architecture and knowledge of pre-trained standard CNNs simultaneously. We first make a quantitative analysis of the baseline network, including computational cost and storage overhead in different components. And then, according to the analysis results, optional strategies can be adopted to the compression of fully-connected layers. For vanilla convolution layers, the proposed parsimonious convolution (ParConv) block only consisting of depthwise separable convolution and pointwise convolution is used as a direct replacement without other adjustments such as the widths and depths in the network. Finally, the knowledge distillation with multiple losses is adopted to improve performance of the compact CNN. The proposed algorithm is first verified on offline handwritten Chinese text recognition (HCTR) where the CNNs are characterized by tens of thousands of output nodes and trained by hundreds of millions of training samples. Compared with the CNN in the state-of-the-art system, our proposed joint architecture and knowledge distillation can reduce the computational cost by >10x and model size by >8x with negligible accuracy loss. And then, by conducting experiments on one of the most popular data sets: MNIST, we demonstrate the proposed approach can also be successfully applied on mainstream backbone networks.
Deep Fusion: An Attention Guided Factorized Bilinear Pooling for Audio-video Emotion Recognition
Jan 15, 2019
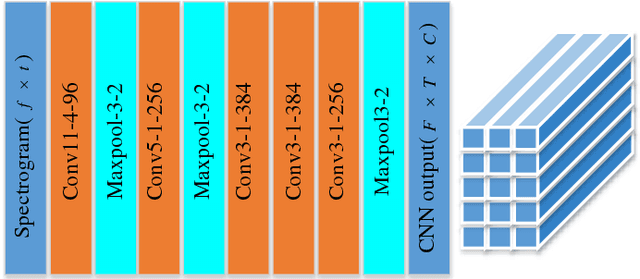
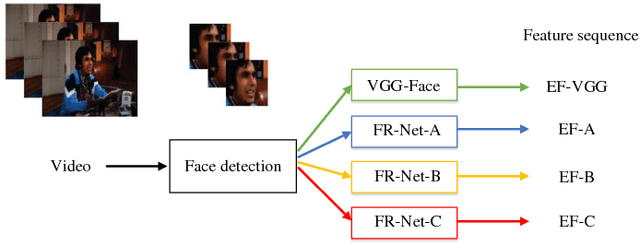
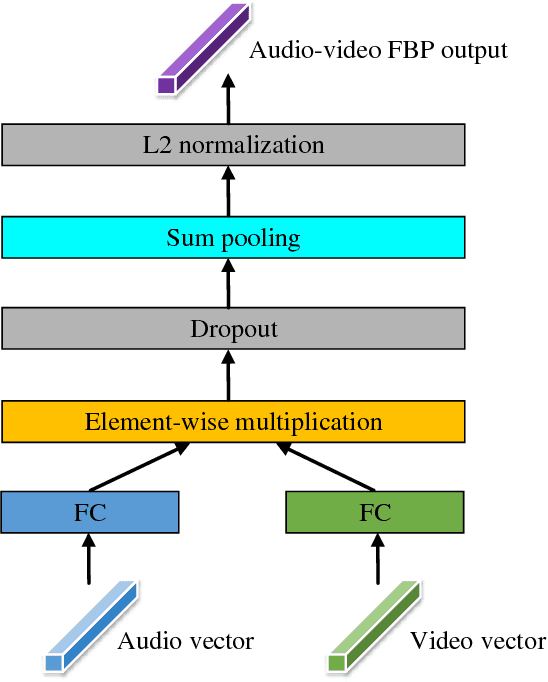
Automatic emotion recognition (AER) is a challenging task due to the abstract concept and multiple expressions of emotion. Although there is no consensus on a definition, human emotional states usually can be apperceived by auditory and visual systems. Inspired by this cognitive process in human beings, it's natural to simultaneously utilize audio and visual information in AER. However, most traditional fusion approaches only build a linear paradigm, such as feature concatenation and multi-system fusion, which hardly captures complex association between audio and video. In this paper, we introduce factorized bilinear pooling (FBP) to deeply integrate the features of audio and video. Specifically, the features are selected through the embedded attention mechanism from respective modalities to obtain the emotion-related regions. The whole pipeline can be completed in a neural network. Validated on the AFEW database of the audio-video sub-challenge in EmotiW2018, the proposed approach achieves an accuracy of 62.48%, outperforming the state-of-the-art result.
Writer-Aware CNN for Parsimonious HMM-Based Offline Handwritten Chinese Text Recognition
Dec 24, 2018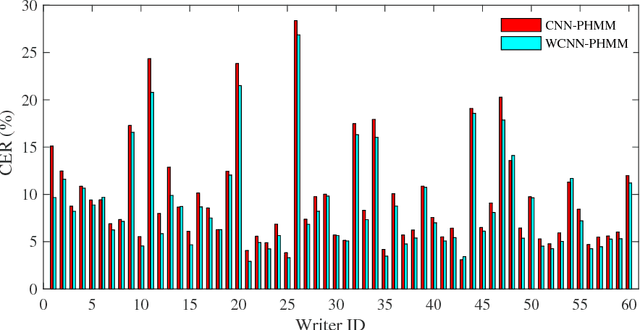
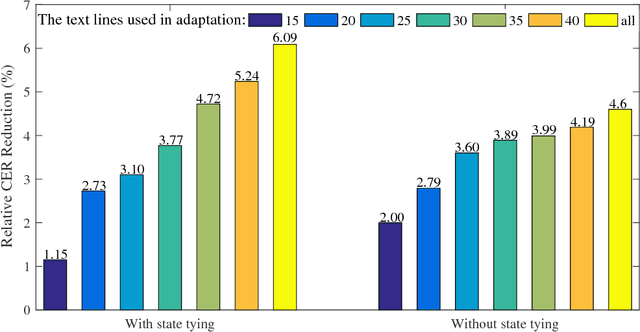
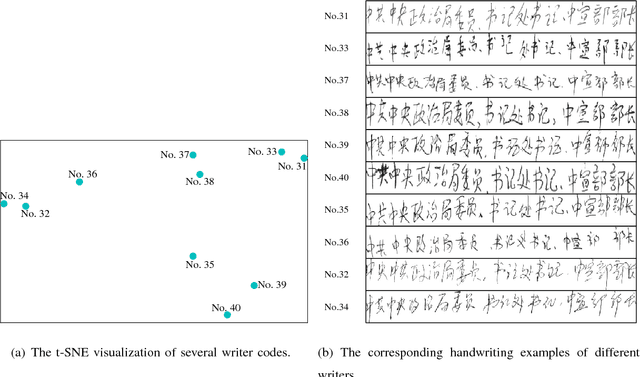
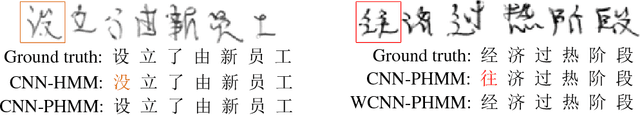
Recently, the hybrid convolutional neural network hidden Markov model (CNN-HMM) has been introduced for offline handwritten Chinese text recognition (HCTR) and has achieved state-of-the-art performance. In a CNN-HMM system, a handwritten text line is modeled by a series of cascading HMMs, each representing one character, and the posterior distributions of HMM states are calculated by CNN. However, modeling each of the large vocabulary of Chinese characters with a uniform and fixed number of hidden states requires high memory and computational costs and makes the tens of thousands of HMM state classes confusing. Another key issue of CNN-HMM for HCTR is the diversified writing style, which leads to model strain and a significant performance decline for specific writers. To address these issues, we propose a writer-aware CNN based on parsimonious HMM (WCNN-PHMM). Validated on the ICDAR 2013 competition of CASIA-HWDB database, the more compact WCNN-PHMM of a 7360-class vocabulary can achieve a relative character error rate (CER) reduction of 16.6% over the conventional CNN-HMM without considering language modeling. Moreover, the state-tying results of PHMM explicitly show the information sharing among similar characters and the confusion reduction of tied state classes. Finally, we visualize the learned writer codes and demonstrate the strong relationship with the writing styles of different writers. To the best of our knowledge, WCNN-PHMM yields the best results on the ICDAR 2013 competition set, demonstrating its power when enlarging the size of the character vocabulary.
Parsimonious HMMs for Offline Handwritten Chinese Text Recognition
Aug 13, 2018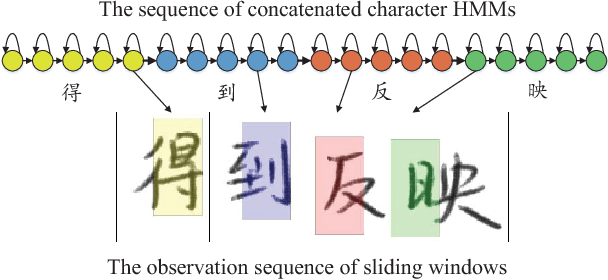
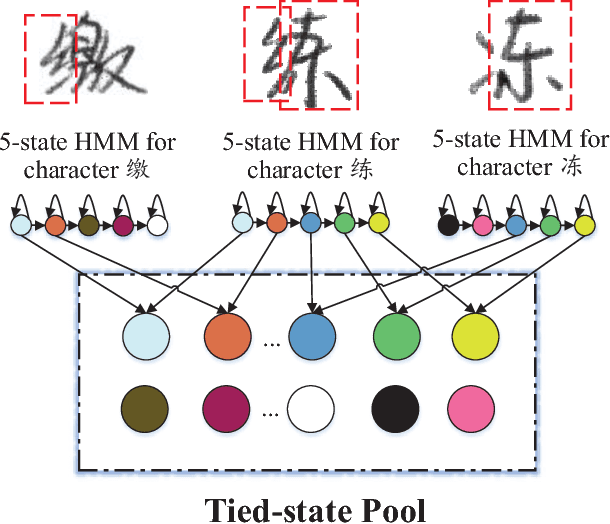
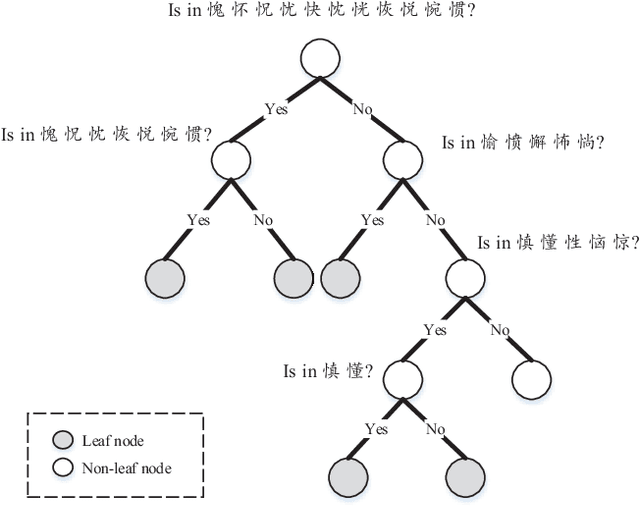
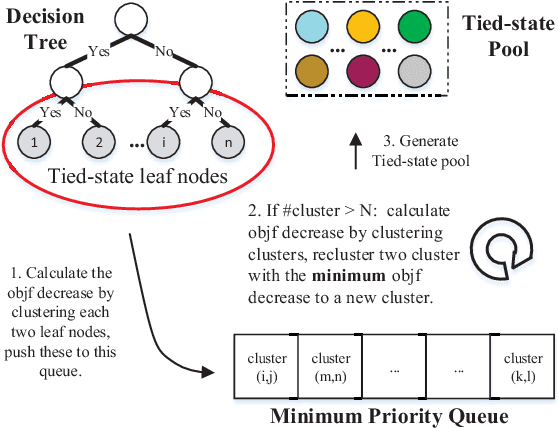
Recently, hidden Markov models (HMMs) have achieved promising results for offline handwritten Chinese text recognition. However, due to the large vocabulary of Chinese characters with each modeled by a uniform and fixed number of hidden states, a high demand of memory and computation is required. In this study, to address this issue, we present parsimonious HMMs via the state tying which can fully utilize the similarities among different Chinese characters. Two-step algorithm with the data-driven question-set is adopted to generate the tied-state pool using the likelihood measure. The proposed parsimonious HMMs with both Gaussian mixture models (GMMs) and deep neural networks (DNNs) as the emission distributions not only lead to a compact model but also improve the recognition accuracy via the data sharing for the tied states and the confusion decreasing among state classes. Tested on ICDAR-2013 competition database, in the best configured case, the new parsimonious DNN-HMM can yield a relative character error rate (CER) reduction of 6.2%, 25% reduction of model size and 60% reduction of decoding time over the conventional DNN-HMM. In the compact setting case of average 1-state HMM, our parsimonious DNN-HMM significantly outperforms the conventional DNN-HMM with a relative CER reduction of 35.5%.
DenseRAN for Offline Handwritten Chinese Character Recognition
Aug 13, 2018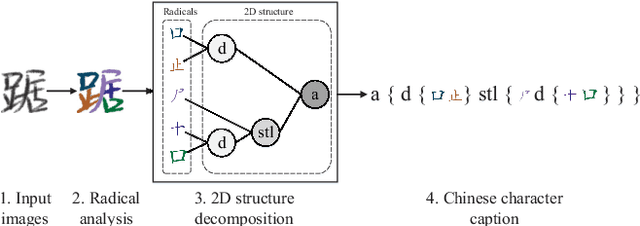
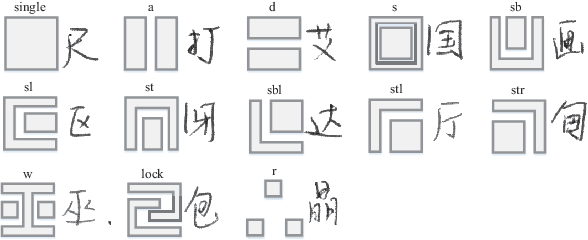
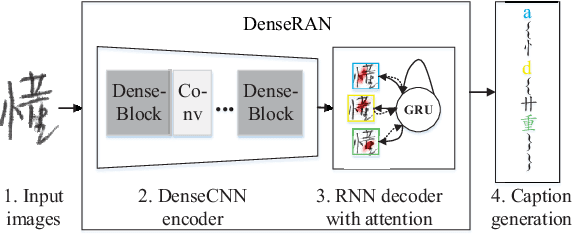

Recently, great success has been achieved in offline handwritten Chinese character recognition by using deep learning methods. Chinese characters are mainly logographic and consist of basic radicals, however, previous research mostly treated each Chinese character as a whole without explicitly considering its internal two-dimensional structure and radicals. In this study, we propose a novel radical analysis network with densely connected architecture (DenseRAN) to analyze Chinese character radicals and its two-dimensional structures simultaneously. DenseRAN first encodes input image to high-level visual features by employing DenseNet as an encoder. Then a decoder based on recurrent neural networks is employed, aiming at generating captions of Chinese characters by detecting radicals and two-dimensional structures through attention mechanism. The manner of treating a Chinese character as a composition of two-dimensional structures and radicals can reduce the size of vocabulary and enable DenseRAN to possess the capability of recognizing unseen Chinese character classes, only if the corresponding radicals have been seen in training set. Evaluated on ICDAR-2013 competition database, the proposed approach significantly outperforms whole-character modeling approach with a relative character error rate (CER) reduction of 18.54%. Meanwhile, for the case of recognizing 3277 unseen Chinese characters in CASIA-HWDB1.2 database, DenseRAN can achieve a character accuracy of about 41% while the traditional whole-character method has no capability to handle them.