 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Architecture and Knowledge Distillation in Convolutional Neural Network for Offline Handwritten Chinese Text Recognition
Paper and Code
Dec 17, 2019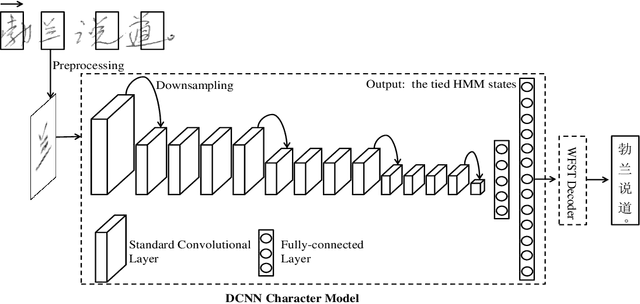
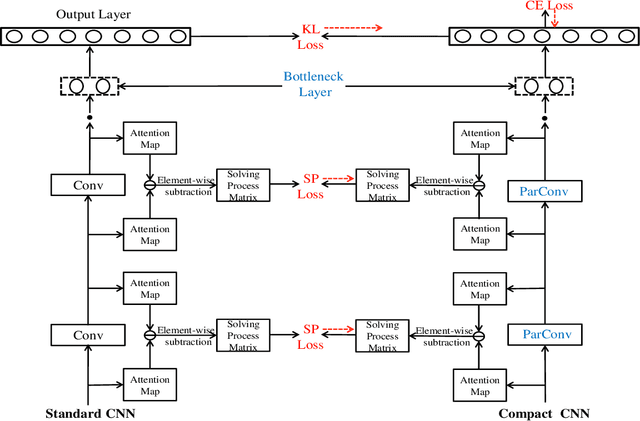
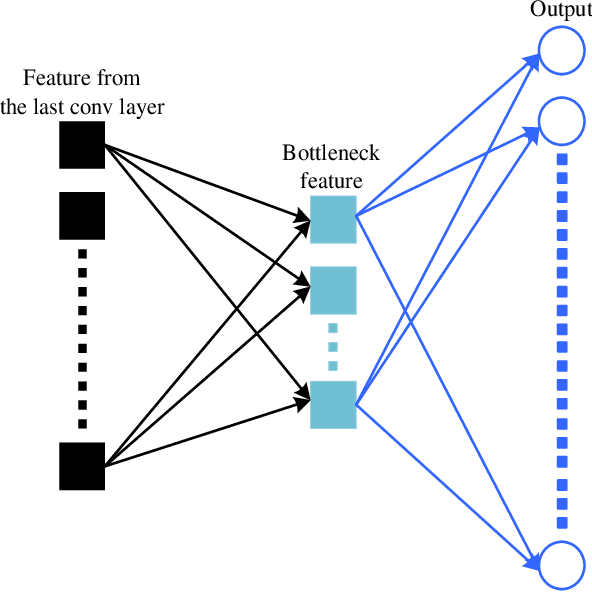
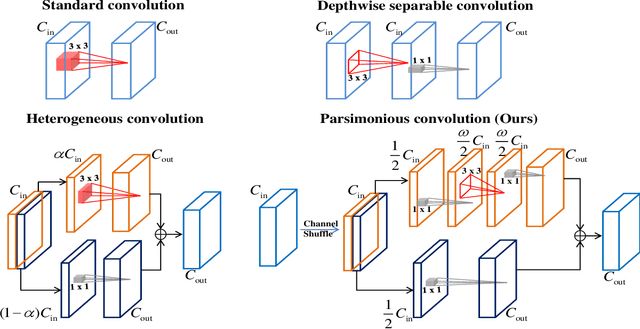
The technique of distillation helps transform cumbersome neural network into compact network so that the model can be deployed on alternative hardware devices. The main advantages of distillation based approaches include simple training process, supported by most off-the-shelf deep learning softwares and no special requirement of hardwares. In this paper, we propose a guideline to distill the architecture and knowledge of pre-trained standard CNNs simultaneously. We first make a quantitative analysis of the baseline network, including computational cost and storage overhead in different components. And then, according to the analysis results, optional strategies can be adopted to the compression of fully-connected layers. For vanilla convolution layers, the proposed parsimonious convolution (ParConv) block only consisting of depthwise separable convolution and pointwise convolution is used as a direct replacement without other adjustments such as the widths and depths in the network. Finally, the knowledge distillation with multiple losses is adopted to improve performance of the compact CNN. The proposed algorithm is first verified on offline handwritten Chinese text recognition (HCTR) where the CNNs are characterized by tens of thousands of output nodes and trained by hundreds of millions of training samples. Compared with the CNN in the state-of-the-art system, our proposed joint architecture and knowledge distillation can reduce the computational cost by >10x and model size by >8x with negligible accuracy loss. And then, by conducting experiments on one of the most popular data sets: MNIST, we demonstrate the proposed approach can also be successfully applied on mainstream backbone networks.