 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParsimonious HMMs for Offline Handwritten Chinese Text Recognition
Paper and Code
Aug 13, 2018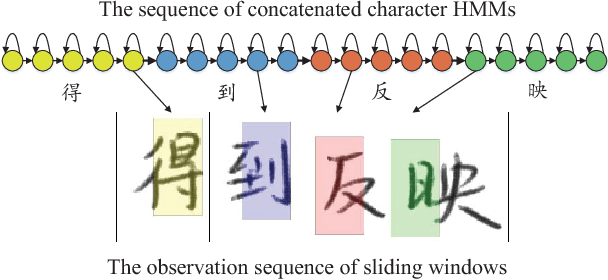
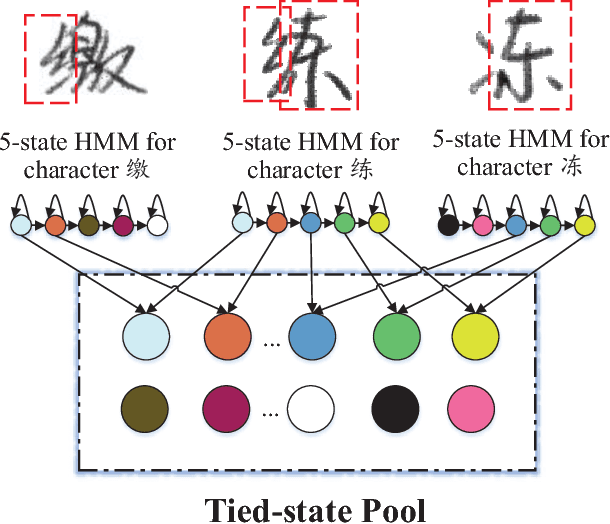
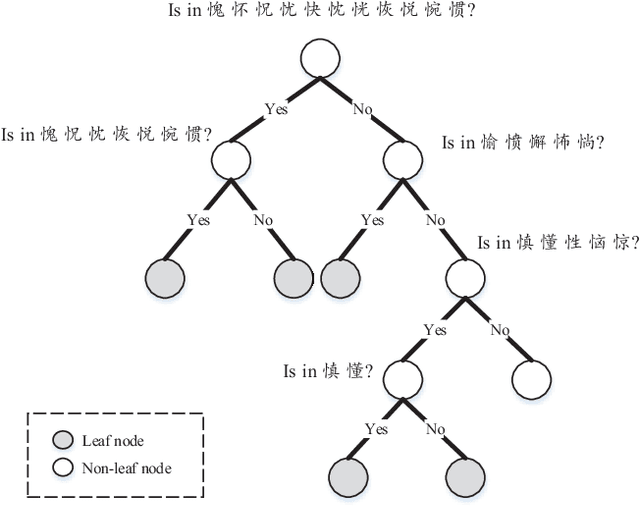
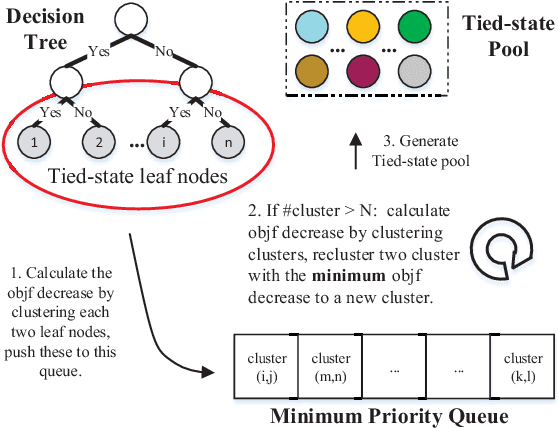
Recently, hidden Markov models (HMMs) have achieved promising results for offline handwritten Chinese text recognition. However, due to the large vocabulary of Chinese characters with each modeled by a uniform and fixed number of hidden states, a high demand of memory and computation is required. In this study, to address this issue, we present parsimonious HMMs via the state tying which can fully utilize the similarities among different Chinese characters. Two-step algorithm with the data-driven question-set is adopted to generate the tied-state pool using the likelihood measure. The proposed parsimonious HMMs with both Gaussian mixture models (GMMs) and deep neural networks (DNNs) as the emission distributions not only lead to a compact model but also improve the recognition accuracy via the data sharing for the tied states and the confusion decreasing among state classes. Tested on ICDAR-2013 competition database, in the best configured case, the new parsimonious DNN-HMM can yield a relative character error rate (CER) reduction of 6.2%, 25% reduction of model size and 60% reduction of decoding time over the conventional DNN-HMM. In the compact setting case of average 1-state HMM, our parsimonious DNN-HMM significantly outperforms the conventional DNN-HMM with a relative CER reduction of 35.5%.