 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Fusion: An Attention Guided Factorized Bilinear Pooling for Audio-video Emotion Recognition
Paper and Code
Jan 15, 2019
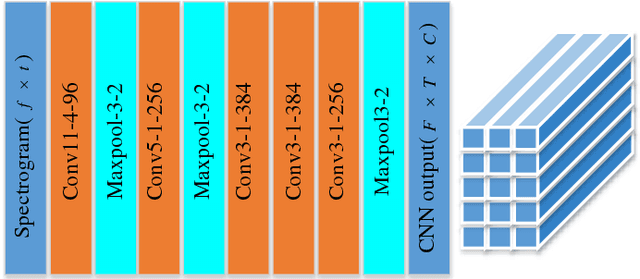
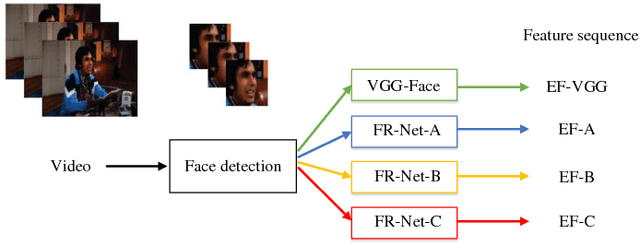
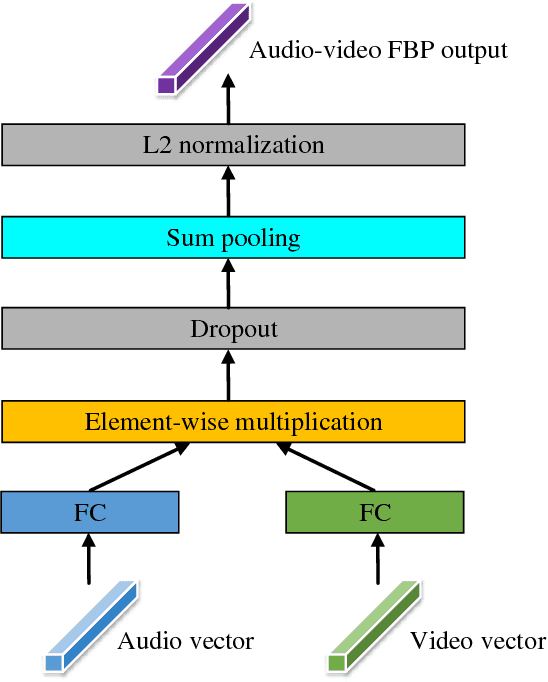
Automatic emotion recognition (AER) is a challenging task due to the abstract concept and multiple expressions of emotion. Although there is no consensus on a definition, human emotional states usually can be apperceived by auditory and visual systems. Inspired by this cognitive process in human beings, it's natural to simultaneously utilize audio and visual information in AER. However, most traditional fusion approaches only build a linear paradigm, such as feature concatenation and multi-system fusion, which hardly captures complex association between audio and video. In this paper, we introduce factorized bilinear pooling (FBP) to deeply integrate the features of audio and video. Specifically, the features are selected through the embedded attention mechanism from respective modalities to obtain the emotion-related regions. The whole pipeline can be completed in a neural network. Validated on the AFEW database of the audio-video sub-challenge in EmotiW2018, the proposed approach achieves an accuracy of 62.48%, outperforming the state-of-the-art result.