 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLOCUS: Local Visual Cue Search for Enhancing Fine-Grained Perception in Multimodal Large Language Models
Jun 15, 2026Multimodal Large Language Models (MLLMs) remain unreliable on fine-grained visual perception, even when high-resolution inputs preserve the necessary local details. We identify this limitation as visual context rot: decisive evidence may exist in the full image, yet fail to be reliably selected and used amid redundant visual context. We propose LOCUS (LOcal visual CUe Search), a training framework that teaches MLLMs to internalize local evidence search through a verifiable proxy task. During training, LOCUS provides a local crop as a visual cue and optimizes the model to recover its spatial support in the full image using an IoU-based reward. The visual cue is used only during training, leaving the standard image-question inference interface unchanged. Experiments across fine-grained perception, hallucination, general understanding, and reasoning benchmarks show that LOCUS improves localization-sensitive visual understanding while preserving broad capabilities. Attention analyses further indicate stronger focus on task-relevant evidence regions, suggesting that training-time visual cue search provides an effective route to internalized fine-grained evidence selection.
Driving risk emerges from the required two-dimensional joint evasive acceleration
Apr 20, 2026Most autonomous driving safety benchmarks use time-to-collision (TTC) to assess risk and guide safe behaviour. However, TTC-based methods treat risk as a one-dimensional closing problem, despite the inherently two-dimensional nature of collision avoidance, and therefore cannot faithfully capture risk or its evolution over time. Here, we report evasive acceleration (EA), a hyperparameter-free and physically interpretable two-dimensional paradigm for risk quantification. By evaluating all possible directions of collision avoidance, EA defines risk as the minimum magnitude of a constant relative acceleration vector required to alter the relative motion and make the interaction collision-free. Using interaction data from five open datasets and more than 600 real crashes, we derive percentile-based warning thresholds and show that EA provides the earliest statistically significant warning across all thresholds. Moreover, EA provides the best discrimination of eventual collision outcomes and improves information retention by 54.2-241.4% over all compared baselines. Adding EA to existing methods yields 17.5-95.5 times more information gain than adding existing methods to EA, indicating that EA captures much of the outcome-relevant information in existing methods while contributing substantial additional nonredundant information. Overall, EA better captures the structure of collision risk and provides a foundation for next-generation autonomous driving systems.
DriveCode: Domain Specific Numerical Encoding for LLM-Based Autonomous Driving
Mar 01, 2026Large language models (LLMs) have shown great promise for autonomous driving. However, discretizing numbers into tokens limits precise numerical reasoning, fails to reflect the positional significance of digits in the training objective, and makes it difficult to achieve both decoding efficiency and numerical precision. These limitations affect both the processing of sensor measurements and the generation of precise control commands, creating a fundamental barrier for deploying LLM-based autonomous driving systems. In this paper, we introduce DriveCode, a novel numerical encoding method that represents numbers as dedicated embeddings rather than discrete text tokens. DriveCode employs a number projector to map numbers into the language model's hidden space, enabling seamless integration with visual and textual features in a unified multimodal sequence. Evaluated on OmniDrive, DriveGPT4, and DriveGPT4-V2 datasets, DriveCode demonstrates superior performance in trajectory prediction and control signal generation, confirming its effectiveness for LLM-based autonomous driving systems.
Learning to Decode in Parallel: Self-Coordinating Neural Network for Real-Time Quantum Error Correction
Jan 14, 2026Fast, reliable decoders are pivotal components for enabling fault-tolerant quantum computation (FTQC). Neural network decoders like AlphaQubit have demonstrated potential, achieving higher accuracy than traditional human-designed decoding algorithms. However, existing implementations of neural network decoders lack the parallelism required to decode the syndrome stream generated by a superconducting logical qubit in real time. Moreover, integrating AlphaQubit with sliding window-based parallel decoding schemes presents non-trivial challenges: AlphaQubit is trained solely to output a single bit corresponding to the global logical correction for an entire memory experiment, rather than local physical corrections that can be easily integrated. We address this issue by training a recurrent, transformer-based neural network specifically tailored for parallel window decoding. While it still outputs a single bit, we derive training labels from a consistent set of local corrections and train on various types of decoding windows simultaneously. This approach enables the network to self-coordinate across neighboring windows, facilitating high-accuracy parallel decoding of arbitrarily long memory experiments. As a result, we overcome the throughput bottleneck that previously precluded the use of AlphaQubit-type decoders in FTQC. Our work presents the first scalable, neural-network-based parallel decoding framework that simultaneously achieves SOTA accuracy and the stringent throughput required for real-time quantum error correction. Using an end-to-end experimental workflow, we benchmark our decoder on the Zuchongzhi 3.2 superconducting quantum processor on surface codes with distances up to 7, demonstrating its superior accuracy. Moreover, we demonstrate that, using our approach, a single TPU v6e is capable of decoding surface codes with distances up to 25 within 1us per decoding round.
Lifting Biomolecular Data Acquisition
Dec 17, 2025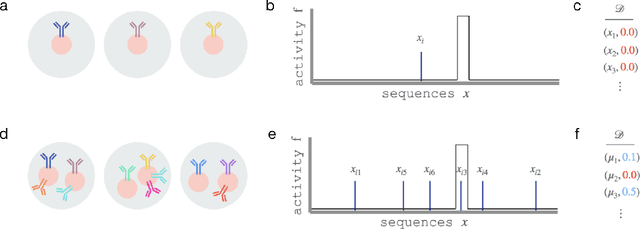
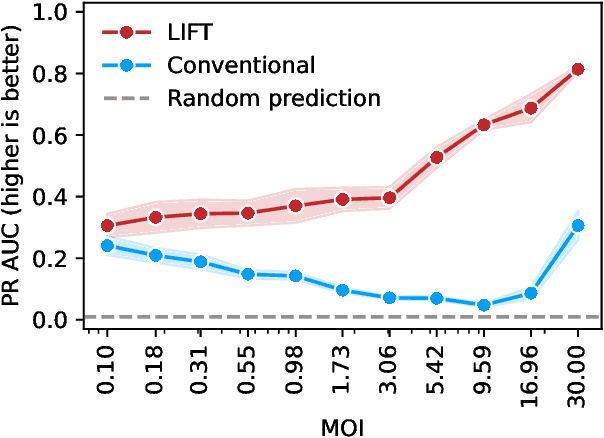
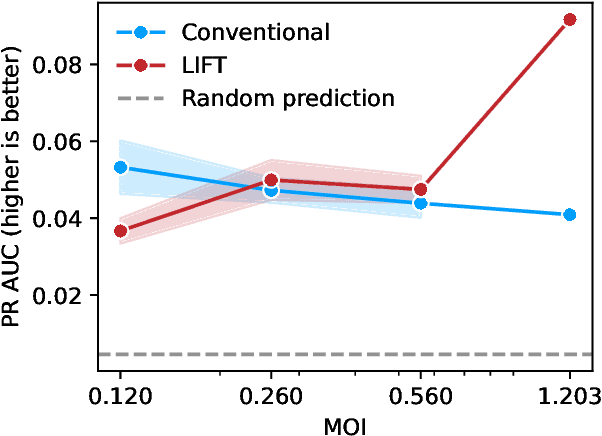
One strategy to scale up ML-driven science is to increase wet lab experiments' information density. We present a method based on a neural extension of compressed sensing to function space. We measure the activity of multiple different molecules simultaneously, rather than individually. Then, we deconvolute the molecule-activity map during model training. Co-design of wet lab experiments and learning algorithms provably leads to orders-of-magnitude gains in information density. We demonstrate on antibodies and cell therapies.
AgentSociety: Large-Scale Simulation of LLM-Driven Generative Agents Advances Understanding of Human Behaviors and Society
Feb 12, 2025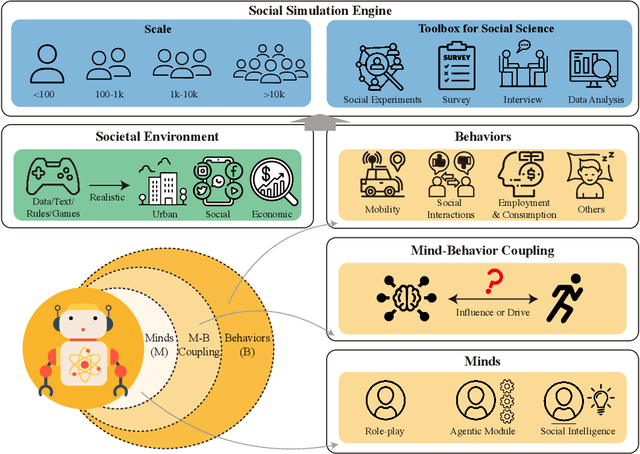
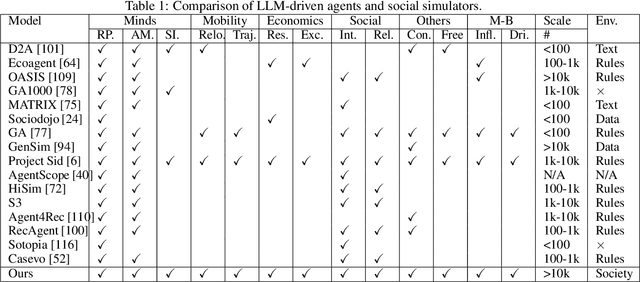
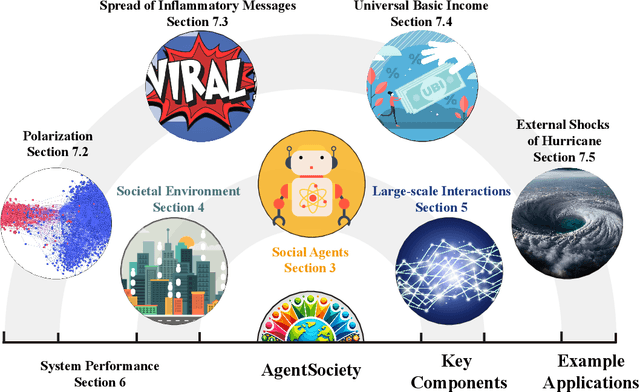

Understanding human behavior and society is a central focus in social sciences, with the rise of generative social science marking a significant paradigmatic shift. By leveraging bottom-up simulations, it replaces costly and logistically challenging traditional experiments with scalable, replicable, and systematic computational approaches for studying complex social dynamics. Recent advances in large language models (LLMs) have further transformed this research paradigm, enabling the creation of human-like generative social agents and realistic simulacra of society. In this paper, we propose AgentSociety, a large-scale social simulator that integrates LLM-driven agents, a realistic societal environment, and a powerful large-scale simulation engine. Based on the proposed simulator, we generate social lives for over 10k agents, simulating their 5 million interactions both among agents and between agents and their environment. Furthermore, we explore the potential of AgentSociety as a testbed for computational social experiments, focusing on four key social issues: polarization, the spread of inflammatory messages, the effects of universal basic income policies, and the impact of external shocks such as hurricanes. These four issues serve as valuable cases for assessing AgentSociety's support for typical research methods -- such as surveys, interviews, and interventions -- as well as for investigating the patterns, causes, and underlying mechanisms of social issues. The alignment between AgentSociety's outcomes and real-world experimental results not only demonstrates its ability to capture human behaviors and their underlying mechanisms, but also underscores its potential as an important platform for social scientists and policymakers.
Deep Learning based Quasi-consciousness Training for Robot Intelligent Model
Jan 31, 2025



This paper explores a deep learning based robot intelligent model that renders robots learn and reason for complex tasks. First, by constructing a network of environmental factor matrix to stimulate the learning process of the robot intelligent model, the model parameters must be subjected to coarse & fine tuning to optimize the loss function for minimizing the loss score, meanwhile robot intelligent model can fuse all previously known concepts together to represent things never experienced before, which need robot intelligent model can be generalized extensively. Secondly, in order to progressively develop a robot intelligent model with primary consciousness, every robot must be subjected to at least 1~3 years of special school for training anthropomorphic behaviour patterns to understand and process complex environmental information and make rational decisions. This work explores and delivers the potential application of deep learning-based quasi-consciousness training in the field of robot intelligent model.
A real-time battle situation intelligent awareness system based on Meta-learning & RNN
Jan 23, 2025



In modern warfare, real-time and accurate battle situation analysis is crucial for making strategic and tactical decisions. The proposed real-time battle situation intelligent awareness system (BSIAS) aims at meta-learning analysis and stepwise RNN (recurrent neural network) modeling, where the former carries out the basic processing and analysis of battlefield data, which includes multi-steps such as data cleansing, data fusion, data mining and continuously updates, and the latter optimizes the battlefield modeling by stepwise capturing the temporal dependencies of data set. BSIAS can predict the possible movement from any side of the fence and attack routes by taking a simulated battle as an example, which can be an intelligent support platform for commanders to make scientific decisions during wartime. This work delivers the potential application of integrated BSIAS in the field of battlefield command & analysis engineering.
An Instance-based Plus Ensemble Learning Method for Classification of Scientific Papers
Sep 21, 2024
The exponential growth of scientific publications in recent years has posed a significant challenge in effective and efficient categorization. This paper introduces a novel approach that combines instance-based learning and ensemble learning techniques for classifying scientific papers into relevant research fields. Working with a classification system with a group of research fields, first a number of typical seed papers are allocated to each of the fields manually. Then for each paper that needs to be classified, we compare it with all the seed papers in every field. Contents and citations are considered separately. An ensemble-based method is then employed to make the final decision. Experimenting with the datasets from DBLP, our experimental results demonstrate that the proposed classification method is effective and efficient in categorizing papers into various research areas. We also find that both content and citation features are useful for the classification of scientific papers.
Difformer: Empowering Diffusion Model on Embedding Space for Text Generation
Dec 19, 2022



Diffusion models have achieved state-of-the-art synthesis quality on visual and audio tasks, and recent works adapt them to textual data by diffusing on the embedding space. But the difference between the continuous data space and the embedding space raises challenges to the diffusion model, which have not been carefully explored. In this paper, we conduct systematic studies and analyze the challenges threefold. Firstly, the data distribution is learnable for embeddings, which may lead to the collapse of the loss function. Secondly, as the norm of embedding varies between popular and rare words, adding the same noise scale will lead to sub-optimal results. In addition, we find that noises sampled from a standard Gaussian distribution may distract the diffusion process. To solve the above challenges, we propose Difformer, a denoising diffusion probabilistic model based on Transformer, which consists of three techniques including utilizing an anchor loss function, a layer normalization module for embeddings, and a norm factor to the Gaussian noise. All techniques are complementary to each other and critical to boosting the model performance together. Experiments are conducted on benchmark datasets over two seminal text generation tasks including machine translation and text summarization. The results show that Difformer significantly outperforms the embedding diffusion baselines, while achieving competitive results with strong autoregressive baselines.