 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmoothing the Landscape: Causal Structure Learning via Diffusion Denoising Objectives
Apr 02, 2026Understanding causal dependencies in observational data is critical for informing decision-making. These relationships are often modeled as Bayesian Networks (BNs) and Directed Acyclic Graphs (DAGs). Existing methods, such as NOTEARS and DAG-GNN, often face issues with scalability and stability in high-dimensional data, especially when there is a feature-sample imbalance. Here, we show that the denoising score matching objective of diffusion models could smooth the gradients for faster, more stable convergence. We also propose an adaptive k-hop acyclicity constraint that improves runtime over existing solutions that require matrix inversion. We name this framework Denoising Diffusion Causal Discovery (DDCD). Unlike generative diffusion models, DDCD utilizes the reverse denoising process to infer a parameterized causal structure rather than to generate data. We demonstrate the competitive performance of DDCDs on synthetic benchmarking data. We also show that our methods are practically useful by conducting qualitative analyses on two real-world examples. Code is available at this url: https://github.com/haozhu233/ddcd.
Smart Sensor Placement: A Correlation-Aware Attribution Framework (CAAF) for Real-world Data Modeling
Oct 26, 2025



Optimal sensor placement (OSP) is critical for efficient, accurate monitoring, control, and inference in complex real-world systems. We propose a machine-learning-based feature attribution framework to identify OSP for the prediction of quantities of interest. Feature attribution quantifies input contributions to a model's output; however, it struggles with highly correlated input data often encountered in real-world applications. To address this, we propose a Correlation-Aware Attribution Framework (CAAF), which introduces a clustering step before performing feature attribution to reduce redundancy and enhance generalizability. We first illustrate the core principles of the proposed framework through a series of validation cases, then demonstrate its effectiveness in real-world dynamical systems, such as structural health monitoring, airfoil lift prediction, and wall-normal velocity estimation for turbulent channel flow. The results show that the CAAF outperforms alternative approaches that typically struggle due to the presence of nonlinear dynamics, chaotic behavior, and multi-scale interactions, and enables the effective application of feature attribution for identifying OSP in real-world environments.
AgentSociety: Large-Scale Simulation of LLM-Driven Generative Agents Advances Understanding of Human Behaviors and Society
Feb 12, 2025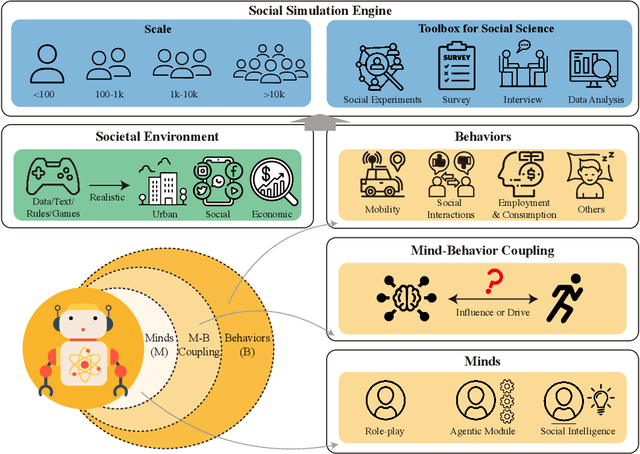
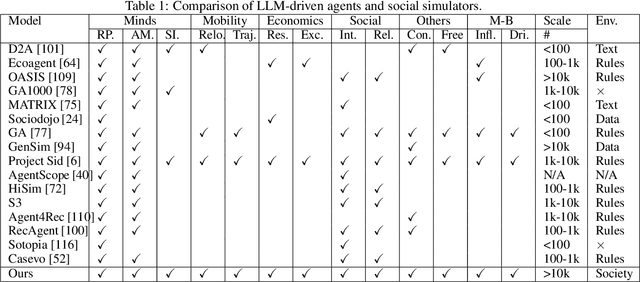
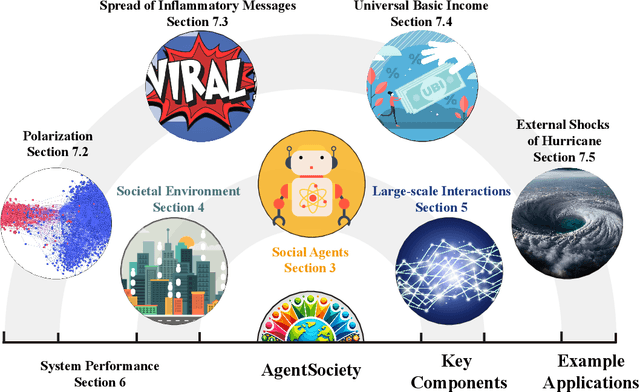

Understanding human behavior and society is a central focus in social sciences, with the rise of generative social science marking a significant paradigmatic shift. By leveraging bottom-up simulations, it replaces costly and logistically challenging traditional experiments with scalable, replicable, and systematic computational approaches for studying complex social dynamics. Recent advances in large language models (LLMs) have further transformed this research paradigm, enabling the creation of human-like generative social agents and realistic simulacra of society. In this paper, we propose AgentSociety, a large-scale social simulator that integrates LLM-driven agents, a realistic societal environment, and a powerful large-scale simulation engine. Based on the proposed simulator, we generate social lives for over 10k agents, simulating their 5 million interactions both among agents and between agents and their environment. Furthermore, we explore the potential of AgentSociety as a testbed for computational social experiments, focusing on four key social issues: polarization, the spread of inflammatory messages, the effects of universal basic income policies, and the impact of external shocks such as hurricanes. These four issues serve as valuable cases for assessing AgentSociety's support for typical research methods -- such as surveys, interviews, and interventions -- as well as for investigating the patterns, causes, and underlying mechanisms of social issues. The alignment between AgentSociety's outcomes and real-world experimental results not only demonstrates its ability to capture human behaviors and their underlying mechanisms, but also underscores its potential as an important platform for social scientists and policymakers.
Beyond Closure Models: Learning Chaotic-Systems via Physics-Informed Neural Operators
Aug 09, 2024Accurately predicting the long-term behavior of chaotic systems is crucial for various applications such as climate modeling. However, achieving such predictions typically requires iterative computations over a dense spatiotemporal grid to account for the unstable nature of chaotic systems, which is expensive and impractical in many real-world situations. An alternative approach to such a full-resolved simulation is using a coarse grid and then correcting its errors through a \textit{closure model}, which approximates the overall information from fine scales not captured in the coarse-grid simulation. Recently, ML approaches have been used for closure modeling, but they typically require a large number of training samples from expensive fully-resolved simulations (FRS). In this work, we prove an even more fundamental limitation, i.e., the standard approach to learning closure models suffers from a large approximation error for generic problems, no matter how large the model is, and it stems from the non-uniqueness of the mapping. We propose an alternative end-to-end learning approach using a physics-informed neural operator (PINO) that overcomes this limitation by not using a closure model or a coarse-grid solver. We first train the PINO model on data from a coarse-grid solver and then fine-tune it with (a small amount of) FRS and physics-based losses on a fine grid. The discretization-free nature of neural operators means that they do not suffer from the restriction of a coarse grid that closure models face, and they can provably approximate the long-term statistics of chaotic systems. In our experiments, our PINO model achieves a 120x speedup compared to FRS with a relative error $\sim 5\%$. In contrast, the closure model coupled with a coarse-grid solver is $58$x slower than PINO while having a much higher error $\sim205\%$ when the closure model is trained on the same FRS dataset.
Representation Alignment Contrastive Regularization for Multi-Object Tracking
Apr 03, 2024Achieving high-performance in multi-object tracking algorithms heavily relies on modeling spatio-temporal relationships during the data association stage. Mainstream approaches encompass rule-based and deep learning-based methods for spatio-temporal relationship modeling. While the former relies on physical motion laws, offering wider applicability but yielding suboptimal results for complex object movements, the latter, though achieving high-performance, lacks interpretability and involves complex module designs. This work aims to simplify deep learning-based spatio-temporal relationship models and introduce interpretability into features for data association. Specifically, a lightweight single-layer transformer encoder is utilized to model spatio-temporal relationships. To make features more interpretative, two contrastive regularization losses based on representation alignment are proposed, derived from spatio-temporal consistency rules. By applying weighted summation to affinity matrices, the aligned features can seamlessly integrate into the data association stage of the original tracking workflow. Experimental results showcase that our model enhances the majority of existing tracking networks' performance without excessive complexity, with minimal increase in training overhead and nearly negligible computational and storage costs.
Red AI? Inconsistent Responses from GPT3.5 Models on Political Issues in the US and China
Dec 15, 2023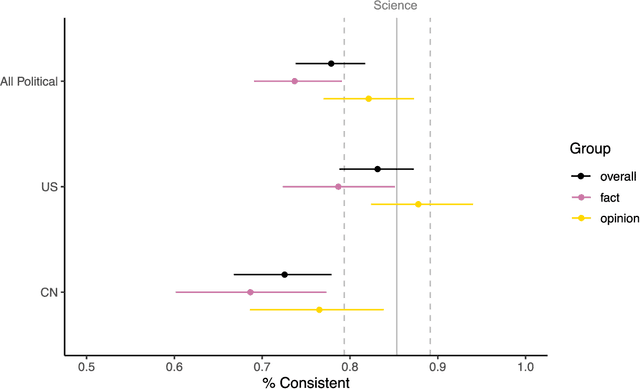


The rising popularity of ChatGPT and other AI-powered large language models (LLMs) has led to increasing studies highlighting their susceptibility to mistakes and biases. However, most of these studies focus on models trained on English texts. Taking an innovative approach, this study investigates political biases in GPT's multilingual models. We posed the same question about high-profile political issues in the United States and China to GPT in both English and simplified Chinese, and our analysis of the bilingual responses revealed that GPT's bilingual models' political "knowledge" (content) and the political "attitude" (sentiment) are significantly more inconsistent on political issues in China. The simplified Chinese GPT models not only tended to provide pro-China information but also presented the least negative sentiment towards China's problems, whereas the English GPT was significantly more negative towards China. This disparity may stem from Chinese state censorship and US-China geopolitical tensions, which influence the training corpora of GPT bilingual models. Moreover, both Chinese and English models tended to be less critical towards the issues of "their own" represented by the language used, than the issues of "the other." This suggests that GPT multilingual models could potentially develop a "political identity" and an associated sentiment bias based on their training language. We discussed the implications of our findings for information transmission and communication in an increasingly divided world.
Reconfigurable Intelligent Surface Enabled Joint Backscattering and Communication
Aug 21, 2023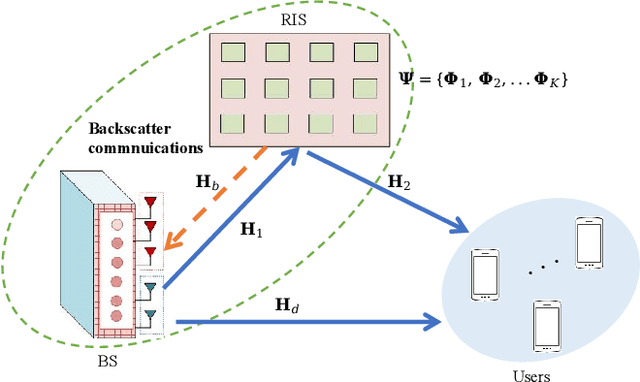

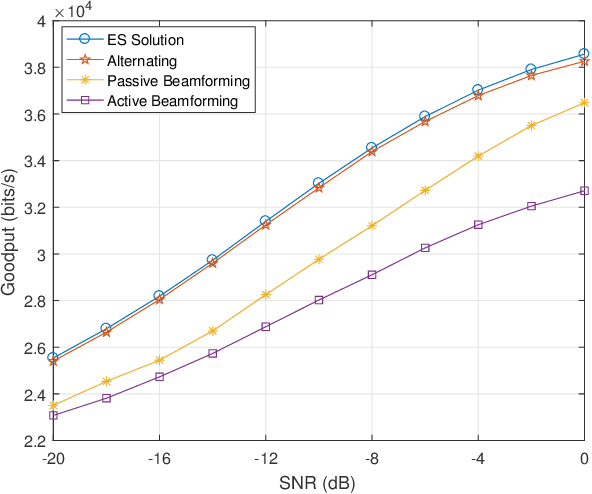
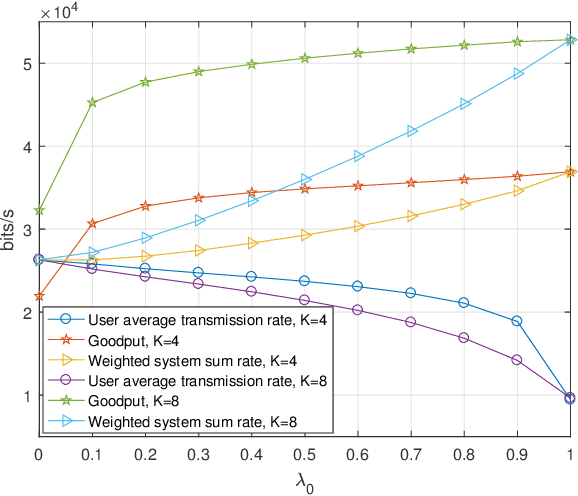
Reconfigurable intelligent surface (RIS) as an essential topic in the sixth-generation (6G) communications aims to enhance communication performance or mitigate undesired transmission. However, the controllability of each reflecting element on RIS also enables it to act as a passive backscatter device (BD) and transmit its information to reader devices. In this paper, we propose a RIS-enabled joint backscattering and communication (JBAC) system, where the backscatter communication coexists with the primary communication and occupies no extra spectrum. Specifically, the RIS modifies its reflecting pattern to act as a passive BD and reflect its own information back to the base station (BS) in the backscatter communication, while helping the primary communication from the BS to the users simultaneously. We further present an iterative active beamforming and reflecting pattern design to maximize the user average transmission rate of the primary communication and the goodput of the backscatter communication by solving the formulated multi-objective optimization problem (MOOP). Numerical results fully uncover the impacts of the number of reflecting elements and the reflecting patterns on the system performance, and demonstrate the effectiveness of the proposed scheme. Important practical implementation remarks have also been discussed.
* 11 pages, 8 figures, published to IEEE TVT
Multi-agent reinforcement learning for wall modeling in LES of flow over periodic hills
Nov 29, 2022



We develop a wall model for large-eddy simulation (LES) that takes into account various pressure-gradient effects using multi-agent reinforcement learning (MARL). The model is trained using low-Reynolds-number flow over periodic hills with agents distributed on the wall along the computational grid points. The model utilizes a wall eddy-viscosity formulation as the boundary condition, which is shown to provide better predictions of the mean velocity field, rather than the typical wall-shear stress formulation. Each agent receives states based on local instantaneous flow quantities at an off-wall location, computes a reward based on the estimated wall-shear stress, and provides an action to update the wall eddy viscosity at each time step. The trained wall model is validated in wall-modeled LES (WMLES) of flow over periodic hills at higher Reynolds numbers, and the results show the effectiveness of the model on flow with pressure gradients. The analysis of the trained model indicates that the model is capable of distinguishing between the various pressure gradient regimes present in the flow.
PPKE: Knowledge Representation Learning by Path-based Pre-training
Dec 07, 2020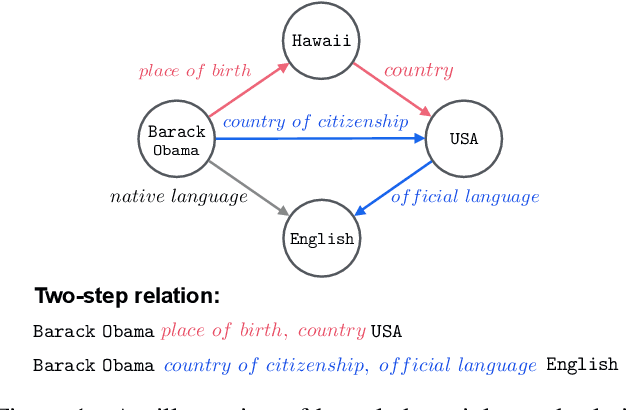

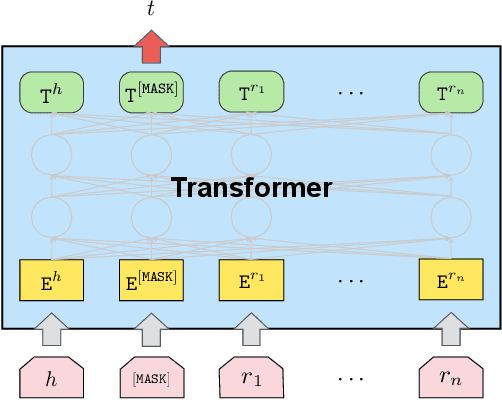
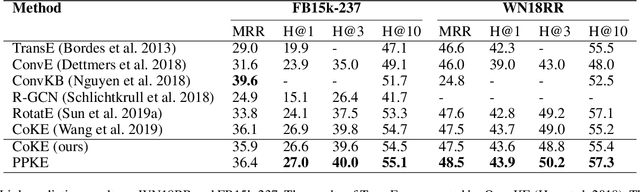
Entities may have complex interactions in a knowledge graph (KG), such as multi-step relationships, which can be viewed as graph contextual information of the entities. Traditional knowledge representation learning (KRL) methods usually treat a single triple as a training unit, and neglect most of the graph contextual information exists in the topological structure of KGs. In this study, we propose a Path-based Pre-training model to learn Knowledge Embeddings, called PPKE, which aims to integrate more graph contextual information between entities into the KRL model. Experiments demonstrate that our model achieves state-of-the-art results on several benchmark datasets for link prediction and relation prediction tasks, indicating that our model provides a feasible way to take advantage of graph contextual information in KGs.
HyperText: Endowing FastText with Hyperbolic Geometry
Oct 30, 2020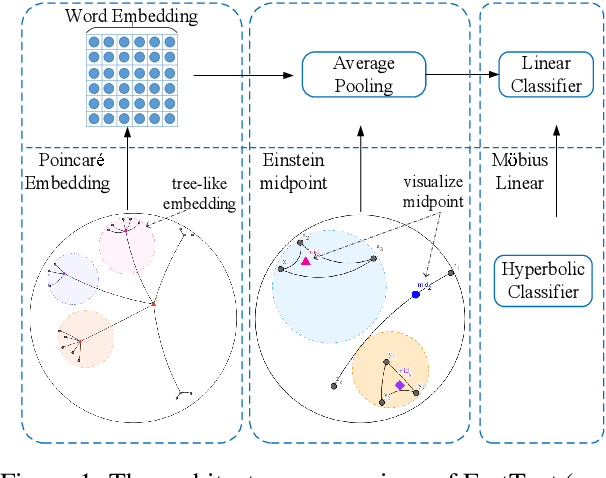


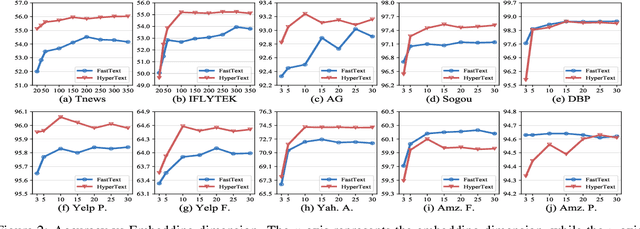
Natural language data exhibit tree-like hierarchical structures such as the hypernym-hyponym relations in WordNet. FastText, as the state-of-the-art text classifier based on shallow neural network in Euclidean space, may not model such hierarchies precisely with limited representation capacity. Considering that hyperbolic space is naturally suitable for modeling tree-like hierarchical data, we propose a new model named HyperText for efficient text classification by endowing FastText with hyperbolic geometry. Empirically, we show that HyperText outperforms FastText on a range of text classification tasks with much reduced parameters.