 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Scalability and Extensibility of Query Reformulation Modeling in E-commerce Search
Feb 17, 2024



Customer behavioral data significantly impacts e-commerce search systems. However, in the case of less common queries, the associated behavioral data tends to be sparse and noisy, offering inadequate support to the search mechanism. To address this challenge, the concept of query reformulation has been introduced. It suggests that less common queries could utilize the behavior patterns of their popular counterparts with similar meanings. In Amazon product search, query reformulation has displayed its effectiveness in improving search relevance and bolstering overall revenue. Nonetheless, adapting this method for smaller or emerging businesses operating in regions with lower traffic and complex multilingual settings poses the challenge in terms of scalability and extensibility. This study focuses on overcoming this challenge by constructing a query reformulation solution capable of functioning effectively, even when faced with limited training data, in terms of quality and scale, along with relatively complex linguistic characteristics. In this paper we provide an overview of the solution implemented within Amazon product search infrastructure, which encompasses a range of elements, including refining the data mining process, redefining model training objectives, and reshaping training strategies. The effectiveness of the proposed solution is validated through online A/B testing on search ranking and Ads matching. Notably, employing the proposed solution in search ranking resulted in 0.14% and 0.29% increase in overall revenue in Japanese and Hindi cases, respectively, and a 0.08\% incremental gain in the English case compared to the legacy implementation; while in search Ads matching led to a 0.36% increase in Ads revenue in the Japanese case.
PERT: A New Solution to Pinyin to Character Conversion Task
May 24, 2022
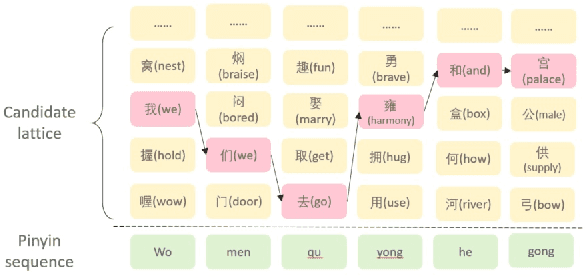
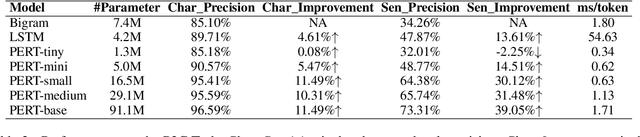
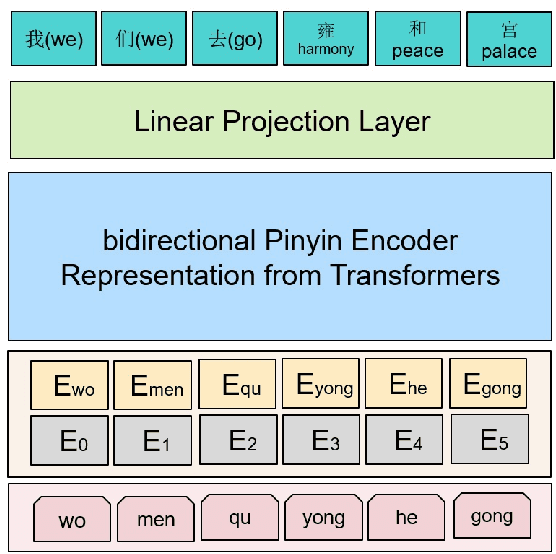
Pinyin to Character conversion (P2C) task is the key task of Input Method Engine (IME) in commercial input software for Asian languages, such as Chinese, Japanese, Thai language and so on. It's usually treated as sequence labelling task and resolved by language model, i.e. n-gram or RNN. However, the low capacity of the n-gram or RNN limits its performance. This paper introduces a new solution named PERT which stands for bidirectional Pinyin Encoder Representations from Transformers. It achieves significant improvement of performance over baselines. Furthermore, we combine PERT with n-gram under a Markov framework, and improve performance further. Lastly, the external lexicon is incorporated into PERT so as to resolve the OOD issue of IME.
Program Transfer and Ontology Awareness for Semantic Parsing in KBQA
Oct 13, 2021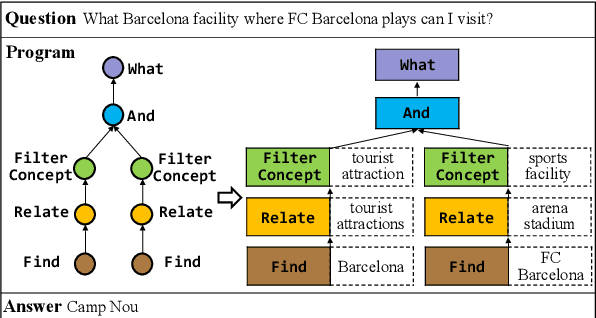
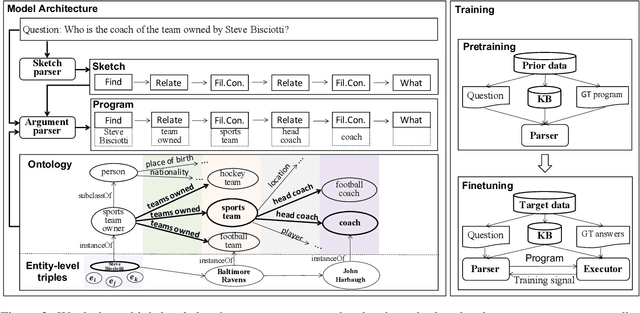

Semantic parsing in KBQA aims to parse natural language questions into logical forms, whose execution against a knowledge base produces answers. Learning semantic parsers from question-answer pairs requires searching over a huge space of logical forms for ones consistent with answers. Current methods utilize various prior knowlege or entity-level KB constraints to reduce the search space. In this paper, we investigate for the first time prior knowledge from external logical form annotations and ontology-level constraints. We design a hierarchical architecture for program transfer, and propose an ontology-guided pruning algorithm to reduce the search space. The experiments on ComplexWebQuestions show that our method improves the state-of-the-art F1 score from 44.0% to 58.7%, with an absolute gain of 14.7%, which demonstrates the effectiveness of program transfer and ontology awareness.
TravelBERT: Pre-training Language Model Incorporating Domain-specific Heterogeneous Knowledge into A Unified Representation
Sep 05, 2021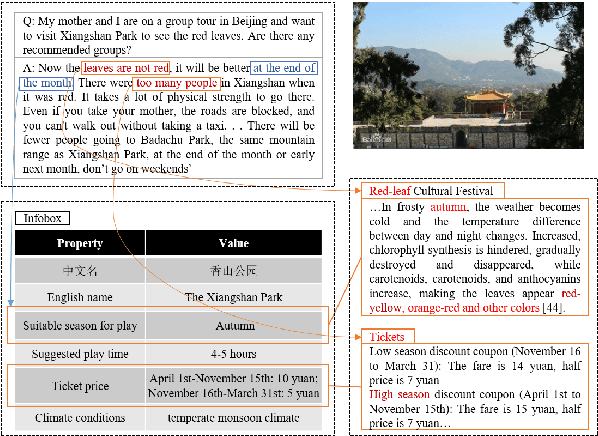

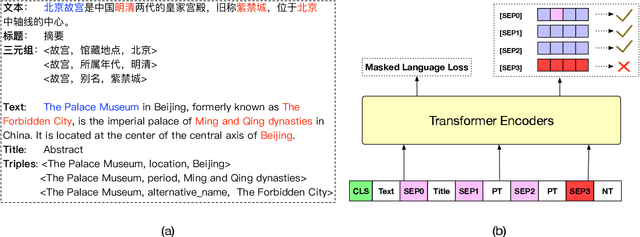
Existing technologies expand BERT from different perspectives, e.g. designing different pre-training tasks, different semantic granularities and different model architectures. Few models consider expanding BERT from different text formats. In this paper, we propose a heterogeneous knowledge language model (HKLM), a unified pre-trained language model (PLM) for all forms of text, including unstructured text, semi-structured text and well-structured text. To capture the corresponding relations among these multi-format knowledge, our approach uses masked language model objective to learn word knowledge, uses triple classification objective and title matching objective to learn entity knowledge and topic knowledge respectively. To obtain the aforementioned multi-format text, we construct a corpus in the tourism domain and conduct experiments on 5 tourism NLP datasets. The results show that our approach outperforms the pre-training of plain text using only 1/4 of the data. The code, datasets, corpus and knowledge graph will be released.
An Approach to Improve Robustness of NLP Systems against ASR Errors
Mar 25, 2021
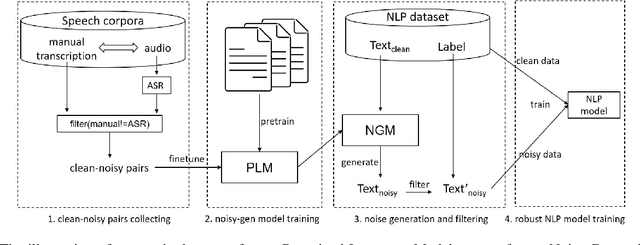


Speech-enabled systems typically first convert audio to text through an automatic speech recognition (ASR) model and then feed the text to downstream natural language processing (NLP) modules. The errors of the ASR system can seriously downgrade the performance of the NLP modules. Therefore, it is essential to make them robust to the ASR errors. Previous work has shown it is effective to employ data augmentation methods to solve this problem by injecting ASR noise during the training process. In this paper, we utilize the prevalent pre-trained language model to generate training samples with ASR-plausible noise. Compare to the previous methods, our approach generates ASR noise that better fits the real-world error distribution. Experimental results on spoken language translation(SLT) and spoken language understanding (SLU) show that our approach effectively improves the system robustness against the ASR errors and achieves state-of-the-art results on both tasks.
PPKE: Knowledge Representation Learning by Path-based Pre-training
Dec 07, 2020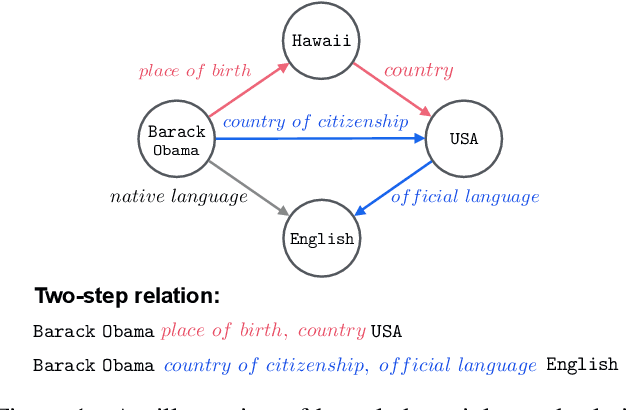

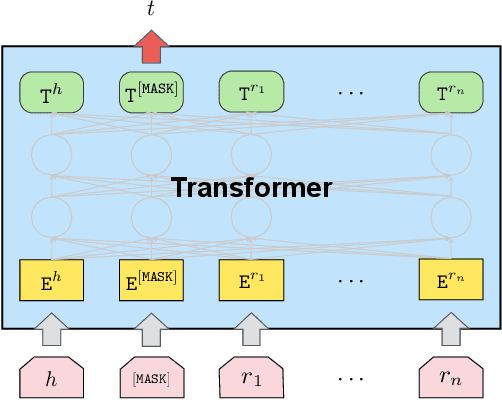
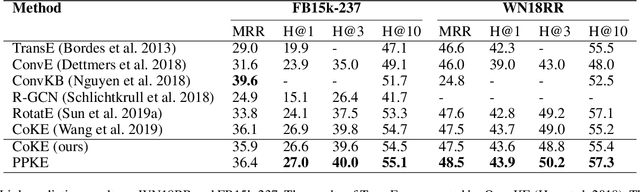
Entities may have complex interactions in a knowledge graph (KG), such as multi-step relationships, which can be viewed as graph contextual information of the entities. Traditional knowledge representation learning (KRL) methods usually treat a single triple as a training unit, and neglect most of the graph contextual information exists in the topological structure of KGs. In this study, we propose a Path-based Pre-training model to learn Knowledge Embeddings, called PPKE, which aims to integrate more graph contextual information between entities into the KRL model. Experiments demonstrate that our model achieves state-of-the-art results on several benchmark datasets for link prediction and relation prediction tasks, indicating that our model provides a feasible way to take advantage of graph contextual information in KGs.
KgPLM: Knowledge-guided Language Model Pre-training via Generative and Discriminative Learning
Dec 07, 2020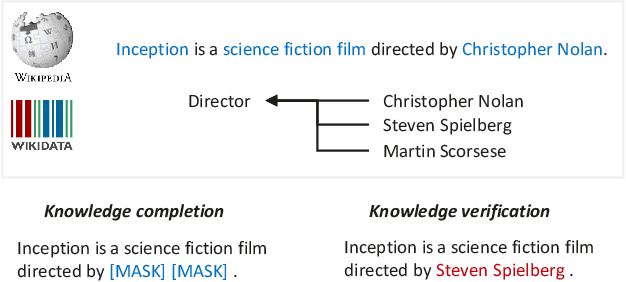
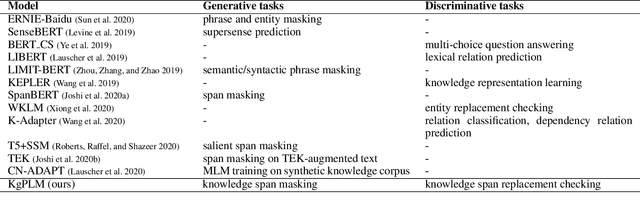

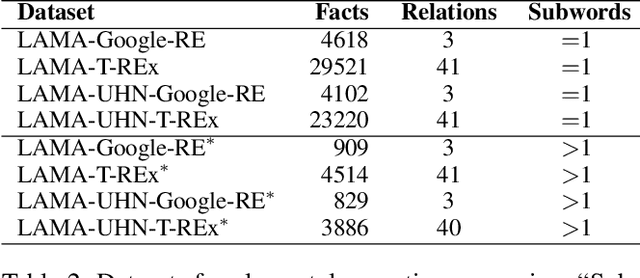
Recent studies on pre-trained language models have demonstrated their ability to capture factual knowledge and applications in knowledge-aware downstream tasks. In this work, we present a language model pre-training framework guided by factual knowledge completion and verification, and use the generative and discriminative approaches cooperatively to learn the model. Particularly, we investigate two learning schemes, named two-tower scheme and pipeline scheme, in training the generator and discriminator with shared parameter. Experimental results on LAMA, a set of zero-shot cloze-style question answering tasks, show that our model contains richer factual knowledge than the conventional pre-trained language models. Furthermore, when fine-tuned and evaluated on the MRQA shared tasks which consists of several machine reading comprehension datasets, our model achieves the state-of-the-art performance, and gains large improvements on NewsQA (+1.26 F1) and TriviaQA (+1.56 F1) over RoBERTa.
HyperText: Endowing FastText with Hyperbolic Geometry
Oct 30, 2020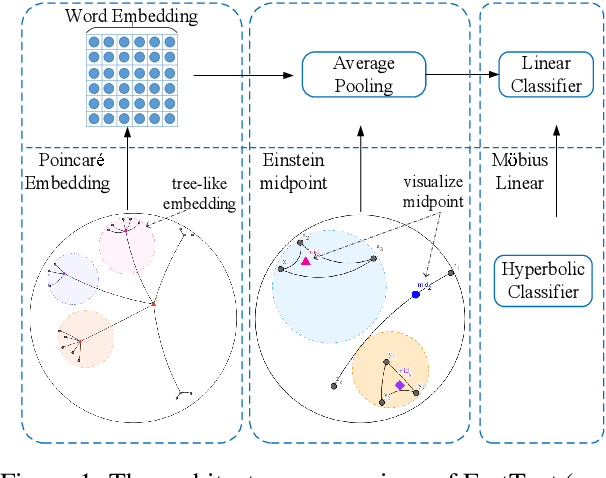


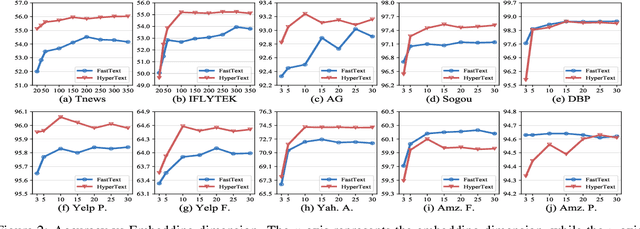
Natural language data exhibit tree-like hierarchical structures such as the hypernym-hyponym relations in WordNet. FastText, as the state-of-the-art text classifier based on shallow neural network in Euclidean space, may not model such hierarchies precisely with limited representation capacity. Considering that hyperbolic space is naturally suitable for modeling tree-like hierarchical data, we propose a new model named HyperText for efficient text classification by endowing FastText with hyperbolic geometry. Empirically, we show that HyperText outperforms FastText on a range of text classification tasks with much reduced parameters.
Integrating Graph Contextualized Knowledge into Pre-trained Language Models
Dec 03, 2019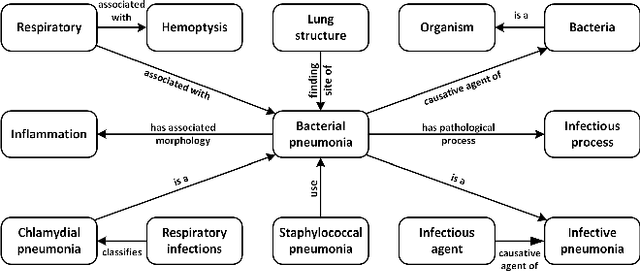

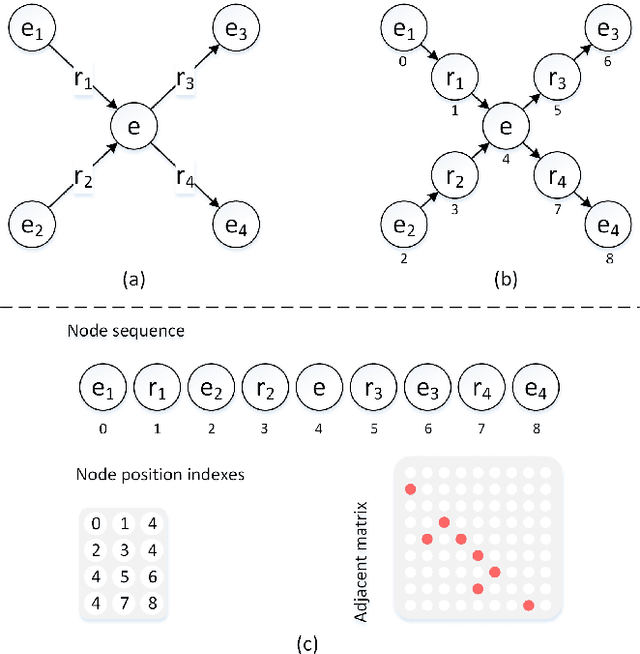

Complex node interactions are common in knowledge graphs, and these interactions also contain rich knowledge information. However, traditional methods usually treat a triple as a training unit during the knowledge representation learning (KRL) procedure, neglecting contextualized information of the nodes in knowledge graphs (KGs). We generalize the modeling object to a very general form, which theoretically supports any subgraph extracted from the knowledge graph, and these subgraphs are fed into a novel transformer-based model to learn the knowledge embeddings. To broaden usage scenarios of knowledge, pre-trained language models are utilized to build a model that incorporates the learned knowledge representations. Experimental results demonstrate that our model achieves the state-of-the-art performance on several medical NLP tasks, and improvement above TransE indicates that our KRL method captures the graph contextualized information effectively.