 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTWAG: A Topic-Guided Wikipedia Abstract Generator
Jun 29, 2021


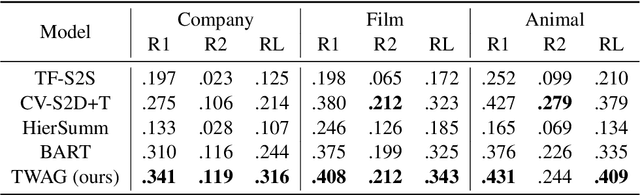
Wikipedia abstract generation aims to distill a Wikipedia abstract from web sources and has met significant success by adopting multi-document summarization techniques. However, previous works generally view the abstract as plain text, ignoring the fact that it is a description of a certain entity and can be decomposed into different topics. In this paper, we propose a two-stage model TWAG that guides the abstract generation with topical information. First, we detect the topic of each input paragraph with a classifier trained on existing Wikipedia articles to divide input documents into different topics. Then, we predict the topic distribution of each abstract sentence, and decode the sentence from topic-aware representations with a Pointer-Generator network. We evaluate our model on the WikiCatSum dataset, and the results show that \modelnames outperforms various existing baselines and is capable of generating comprehensive abstracts. Our code and dataset can be accessed at \url{https://github.com/THU-KEG/TWAG}
An Approach to Improve Robustness of NLP Systems against ASR Errors
Mar 25, 2021
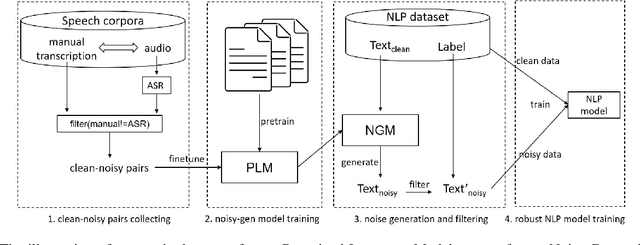


Speech-enabled systems typically first convert audio to text through an automatic speech recognition (ASR) model and then feed the text to downstream natural language processing (NLP) modules. The errors of the ASR system can seriously downgrade the performance of the NLP modules. Therefore, it is essential to make them robust to the ASR errors. Previous work has shown it is effective to employ data augmentation methods to solve this problem by injecting ASR noise during the training process. In this paper, we utilize the prevalent pre-trained language model to generate training samples with ASR-plausible noise. Compare to the previous methods, our approach generates ASR noise that better fits the real-world error distribution. Experimental results on spoken language translation(SLT) and spoken language understanding (SLU) show that our approach effectively improves the system robustness against the ASR errors and achieves state-of-the-art results on both tasks.
Multi-pretrained Deep Neural Network
Jun 02, 2016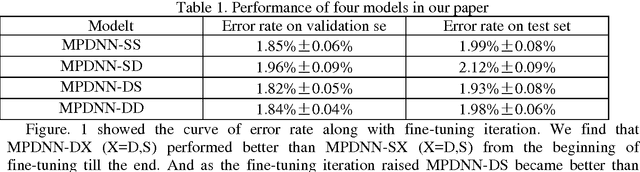

Pretraining is widely used in deep neutral network and one of the most famous pretraining models is Deep Belief Network (DBN). The optimization formulas are different during the pretraining process for different pretraining models. In this paper, we pretrained deep neutral network by different pretraining models and hence investigated the difference between DBN and Stacked Denoising Autoencoder (SDA) when used as pretraining model. The experimental results show that DBN get a better initial model. However the model converges to a relatively worse model after the finetuning process. Yet after pretrained by SDA for the second time the model converges to a better model if finetuned.