 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTWAG: A Topic-Guided Wikipedia Abstract Generator
Paper and Code



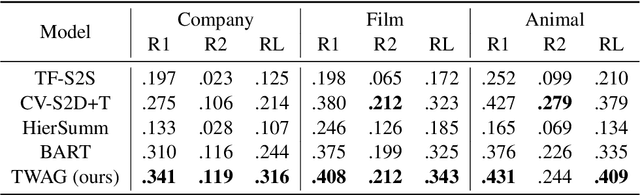
Wikipedia abstract generation aims to distill a Wikipedia abstract from web sources and has met significant success by adopting multi-document summarization techniques. However, previous works generally view the abstract as plain text, ignoring the fact that it is a description of a certain entity and can be decomposed into different topics. In this paper, we propose a two-stage model TWAG that guides the abstract generation with topical information. First, we detect the topic of each input paragraph with a classifier trained on existing Wikipedia articles to divide input documents into different topics. Then, we predict the topic distribution of each abstract sentence, and decode the sentence from topic-aware representations with a Pointer-Generator network. We evaluate our model on the WikiCatSum dataset, and the results show that \modelnames outperforms various existing baselines and is capable of generating comprehensive abstracts. Our code and dataset can be accessed at \url{https://github.com/THU-KEG/TWAG}