 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoLT: Reasoning with Chain of Latent Tool Calls
Feb 04, 2026Chain-of-Thought (CoT) is a critical technique in enhancing the reasoning ability of Large Language Models (LLMs), and latent reasoning methods have been proposed to accelerate the inefficient token-level reasoning chain. We notice that existing latent reasoning methods generally require model structure augmentation and exhaustive training, limiting their broader applicability. In this paper, we propose CoLT, a novel framework that implements latent reasoning as ``tool calls''. Instead of reasoning entirely in the latent space, CoLT generates seed tokens that contain information of a reasoning step. When a latent tool call is triggered, a smaller external model will take the hidden states of seed tokens as its input, and unpack the seed tokens back to a full reasoning step. In this way, we can ensure that the main model reasons in the explicit token space, preserving its ability while improving efficiency. Experimental results on four mathematical datasets demonstrate that CoLT achieves higher accuracy and shorter reasoning length than baseline latent models, and is compatible with reinforcement learning algorithms and different decoder structures.
RICo: Refined In-Context Contribution for Automatic Instruction-Tuning Data Selection
May 18, 2025



Data selection for instruction tuning is crucial for improving the performance of large language models (LLMs) while reducing training costs. In this paper, we propose Refined Contribution Measurement with In-Context Learning (RICo), a novel gradient-free method that quantifies the fine-grained contribution of individual samples to both task-level and global-level model performance. RICo enables more accurate identification of high-contribution data, leading to better instruction tuning. We further introduce a lightweight selection paradigm trained on RICo scores, enabling scalable data selection with a strictly linear inference complexity. Extensive experiments on three LLMs across 12 benchmarks and 5 pairwise evaluation sets demonstrate the effectiveness of RICo. Remarkably, on LLaMA3.1-8B, models trained on 15% of RICo-selected data outperform full datasets by 5.42% points and exceed the best performance of widely used selection methods by 2.06% points. We further analyze high-contribution samples selected by RICo, which show both diverse tasks and appropriate difficulty levels, rather than just the hardest ones.
Chain-of-Thought Tokens are Computer Program Variables
May 08, 2025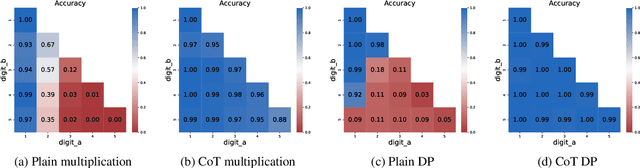



Chain-of-thoughts (CoT) requires large language models (LLMs) to generate intermediate steps before reaching the final answer, and has been proven effective to help LLMs solve complex reasoning tasks. However, the inner mechanism of CoT still remains largely unclear. In this paper, we empirically study the role of CoT tokens in LLMs on two compositional tasks: multi-digit multiplication and dynamic programming. While CoT is essential for solving these problems, we find that preserving only tokens that store intermediate results would achieve comparable performance. Furthermore, we observe that storing intermediate results in an alternative latent form will not affect model performance. We also randomly intervene some values in CoT, and notice that subsequent CoT tokens and the final answer would change correspondingly. These findings suggest that CoT tokens may function like variables in computer programs but with potential drawbacks like unintended shortcuts and computational complexity limits between tokens. The code and data are available at https://github.com/solitaryzero/CoTs_are_Variables.
ICon: In-Context Contribution for Automatic Data Selection
May 08, 2025Data selection for instruction tuning is essential for improving the performance of Large Language Models (LLMs) and reducing training cost. However, existing automated selection methods either depend on computationally expensive gradient-based measures or manually designed heuristics, which may fail to fully exploit the intrinsic attributes of data. In this paper, we propose In-context Learning for Contribution Measurement (ICon), a novel gradient-free method that takes advantage of the implicit fine-tuning nature of in-context learning (ICL) to measure sample contribution without gradient computation or manual indicators engineering. ICon offers a computationally efficient alternative to gradient-based methods and reduces human inductive bias inherent in heuristic-based approaches. ICon comprises three components and identifies high-contribution data by assessing performance shifts under implicit learning through ICL. Extensive experiments on three LLMs across 12 benchmarks and 5 pairwise evaluation sets demonstrate the effectiveness of ICon. Remarkably, on LLaMA3.1-8B, models trained on 15% of ICon-selected data outperform full datasets by 5.42% points and exceed the best performance of widely used selection methods by 2.06% points. We further analyze high-contribution samples selected by ICon, which show both diverse tasks and appropriate difficulty levels, rather than just the hardest ones.
Chip-Tuning: Classify Before Language Models Say
Oct 09, 2024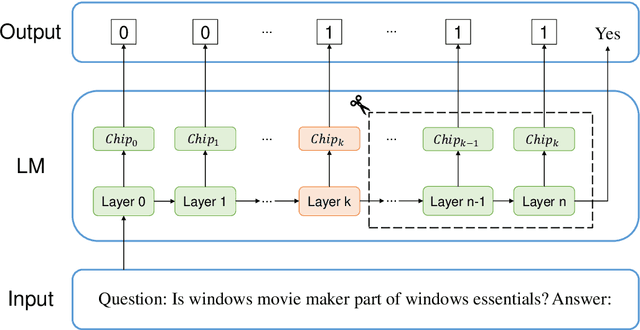
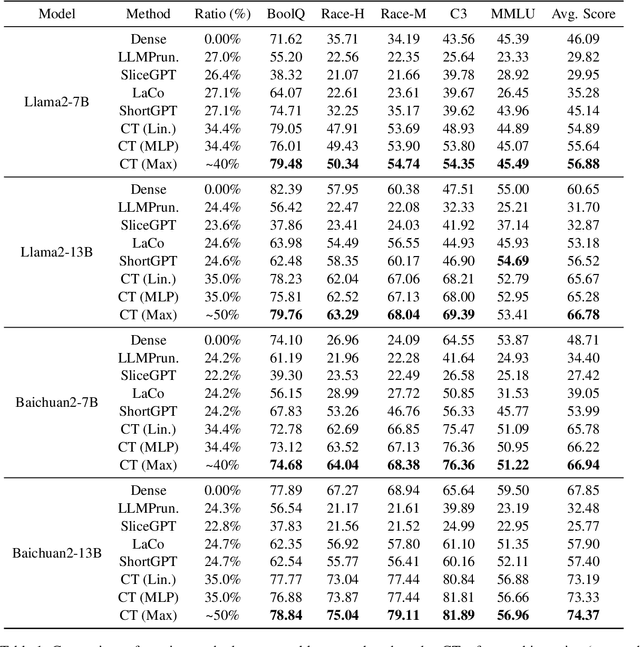
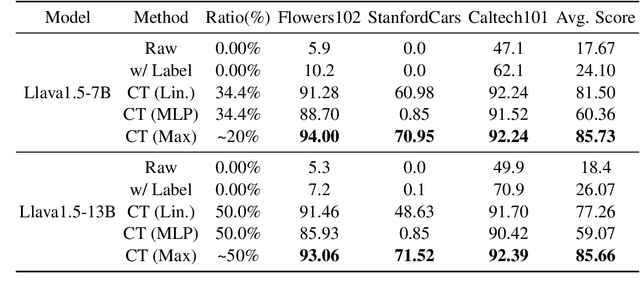
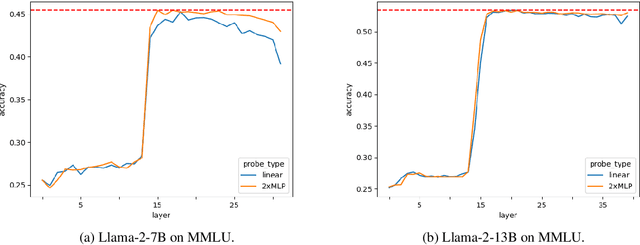
The rapid development in the performance of large language models (LLMs) is accompanied by the escalation of model size, leading to the increasing cost of model training and inference. Previous research has discovered that certain layers in LLMs exhibit redundancy, and removing these layers brings only marginal loss in model performance. In this paper, we adopt the probing technique to explain the layer redundancy in LLMs and demonstrate that language models can be effectively pruned with probing classifiers. We propose chip-tuning, a simple and effective structured pruning framework specialized for classification problems. Chip-tuning attaches tiny probing classifiers named chips to different layers of LLMs, and trains chips with the backbone model frozen. After selecting a chip for classification, all layers subsequent to the attached layer could be removed with marginal performance loss. Experimental results on various LLMs and datasets demonstrate that chip-tuning significantly outperforms previous state-of-the-art baselines in both accuracy and pruning ratio, achieving a pruning ratio of up to 50%. We also find that chip-tuning could be applied on multimodal models, and could be combined with model finetuning, proving its excellent compatibility.
LLMAEL: Large Language Models are Good Context Augmenters for Entity Linking
Jul 04, 2024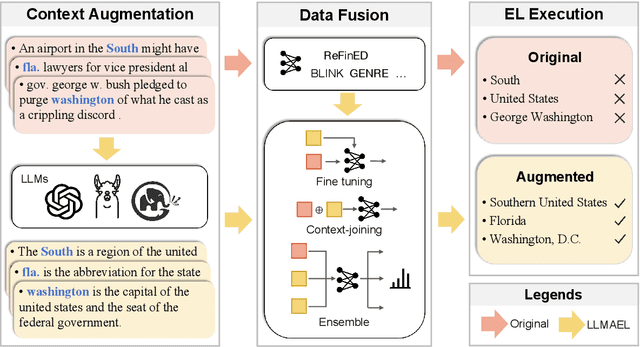

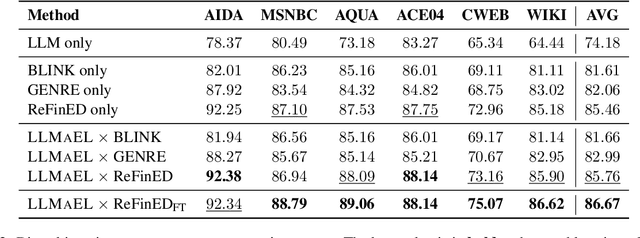
Entity Linking (EL) models are well-trained at mapping mentions to their corresponding entities according to a given context. However, EL models struggle to disambiguate long-tail entities due to their limited training data. Meanwhile, large language models (LLMs) are more robust at interpreting uncommon mentions. Yet, due to a lack of specialized training, LLMs suffer at generating correct entity IDs. Furthermore, training an LLM to perform EL is cost-intensive. Building upon these insights, we introduce LLM-Augmented Entity Linking LLMAEL, a plug-and-play approach to enhance entity linking through LLM data augmentation. We leverage LLMs as knowledgeable context augmenters, generating mention-centered descriptions as additional input, while preserving traditional EL models for task specific processing. Experiments on 6 standard datasets show that the vanilla LLMAEL outperforms baseline EL models in most cases, while the fine-tuned LLMAEL set the new state-of-the-art results across all 6 benchmarks.
CoUDA: Coherence Evaluation via Unified Data Augmentation
Mar 31, 2024



Coherence evaluation aims to assess the organization and structure of a discourse, which remains challenging even in the era of large language models. Due to the scarcity of annotated data, data augmentation is commonly used for training coherence evaluation models. However, previous augmentations for this task primarily rely on heuristic rules, lacking designing criteria as guidance. In this paper, we take inspiration from linguistic theory of discourse structure, and propose a data augmentation framework named CoUDA. CoUDA breaks down discourse coherence into global and local aspects, and designs augmentation strategies for both aspects, respectively. Especially for local coherence, we propose a novel generative strategy for constructing augmentation samples, which involves post-pretraining a generative model and applying two controlling mechanisms to control the difficulty of generated samples. During inference, CoUDA also jointly evaluates both global and local aspects to comprehensively assess the overall coherence of a discourse. Extensive experiments in coherence evaluation show that, with only 233M parameters, CoUDA achieves state-of-the-art performance in both pointwise scoring and pairwise ranking tasks, even surpassing recent GPT-3.5 and GPT-4 based metrics.
Reducing Hallucinations in Entity Abstract Summarization with Facts-Template Decomposition
Feb 29, 2024



Entity abstract summarization aims to generate a coherent description of a given entity based on a set of relevant Internet documents. Pretrained language models (PLMs) have achieved significant success in this task, but they may suffer from hallucinations, i.e. generating non-factual information about the entity. To address this issue, we decompose the summary into two components: Facts that represent the factual information about the given entity, which PLMs are prone to fabricate; and Template that comprises generic content with designated slots for facts, which PLMs can generate competently. Based on the facts-template decomposition, we propose SlotSum, an explainable framework for entity abstract summarization. SlotSum first creates the template and then predicts the fact for each template slot based on the input documents. Benefiting from our facts-template decomposition, SlotSum can easily locate errors and further rectify hallucinated predictions with external knowledge. We construct a new dataset WikiFactSum to evaluate the performance of SlotSum. Experimental results demonstrate that SlotSum could generate summaries that are significantly more factual with credible external knowledge.
Language Models Understand Numbers, at Least Partially
Jan 08, 2024Large language models (LLMs) have exhibited impressive competency in various text-related tasks. However, their opaque internal mechanisms become a hindrance to leveraging them in mathematical problems. In this paper, we study a fundamental question: whether language models understand numbers, which play a basic element in mathematical problems. We assume that to solve mathematical problems, language models should be capable of understanding numbers and compressing these numbers in their hidden states. We construct a synthetic dataset comprising addition problems and utilize linear probes to read out input numbers from the hidden states of models. Experimental results demonstrate evidence supporting the existence of compressed numbers in the LLaMA-2 model family from early layers. However, the compression process seems to be not lossless, presenting difficulty in precisely reconstructing the original numbers. Further experiments show that language models can utilize the encoded numbers to perform arithmetic computations, and the computational ability scales up with the model size. Our preliminary research suggests that language models exhibit a partial understanding of numbers, offering insights into future investigations about the models' capability of solving mathematical problems.
Learn to Not Link: Exploring NIL Prediction in Entity Linking
May 25, 2023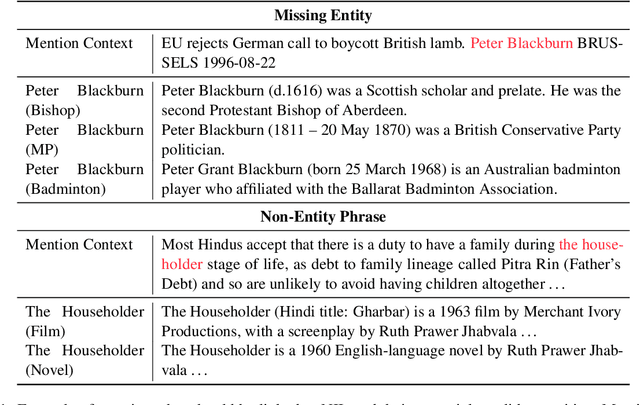
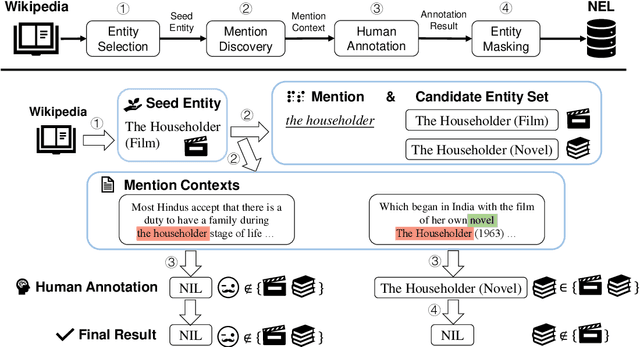
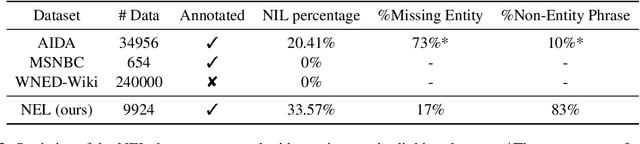
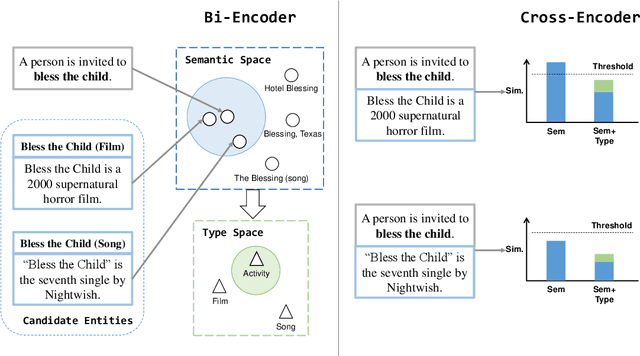
Entity linking models have achieved significant success via utilizing pretrained language models to capture semantic features. However, the NIL prediction problem, which aims to identify mentions without a corresponding entity in the knowledge base, has received insufficient attention. We categorize mentions linking to NIL into Missing Entity and Non-Entity Phrase, and propose an entity linking dataset NEL that focuses on the NIL prediction problem. NEL takes ambiguous entities as seeds, collects relevant mention context in the Wikipedia corpus, and ensures the presence of mentions linking to NIL by human annotation and entity masking. We conduct a series of experiments with the widely used bi-encoder and cross-encoder entity linking models, results show that both types of NIL mentions in training data have a significant influence on the accuracy of NIL prediction. Our code and dataset can be accessed at https://github.com/solitaryzero/NIL_EL