 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Dynamic Batching with Formal Guarantees for LLM Training
Jun 18, 2026Modern LLM training breaks a core assumption behind offline batch samplers: the true training cost of a sample is only observable after preprocessing, augmentation, templating, tokenization, and multimodal visual-token expansion. Unless one pays for a preprocessing- and augmentation-dependent length cache, batch construction is therefore blind to the quantity that determines padding, memory use, and GPU saturation. We introduce Online Dynamic Batching (ODB), a DataLoader-side drop-in system that moves batch formation to this point of accurate observability while preserving DDP step alignment. We formalize this synchronization requirement as the Distributed Group Alignment Problem and prove deadlock-free bounded termination with default join-mode identity coverage and opt-in non-join sample-quota closure. ODB requires no model, optimizer, or attention-kernel changes and is released as online-dynamic-batching with lightweight trainer adapters. Across public 2B/8B Qwen3-VL runs on UltraChat/LLaVA/ShareGPT4o, ODB improves literal emitted-sample throughput vs. fixed-batch Standard by 1.58-2.51x on single-node Full FT/LoRA and 1.71-3.78x on two-node Full FT, with Standard-comparable quality; production MM-Mix reaches 4.43x. Against GMT/BMT offline token-budget oracles, ODB is within 15% on UltraChat/LLaVA and faster on high-CV ShareGPT4o: 2.24-2.39x single-node Full FT/LoRA and 3.06-3.69x two-node Full FT. Together, ODB occupies the online/drop-in regime for high-heterogeneity LLM fine-tuning: large throughput gains at Standard-comparable quality, formal DGAP guarantees, and no length-cache precompute or kernel rewrites.
LiveK12Bench: Have Large Multimodal Models Truly Conquered High School-level Examinations?
May 26, 2026Advanced Large Multimodal Models (LMMs) have demonstrated impressive performance in K-12 reasoning tasks, exhibiting great promise as intelligent tutors. Realizing this potential requires models to navigate real-world examinations effectively, yet most existing benchmarks fail to capture the complexity of authentic testing environments. Specifically, most datasets are static, prone to data contamination, and are often confined to restricted modalities, disciplines, and evaluation criteria. To address these issues, we introduce LiveK12Bench, a dynamic, holistic, multi-disciplinary benchmark designed to evaluate the reasoning abilities of LMMs in realistic examination scenarios. LiveK12Bench comprises 2K+ verified questions spanning Mathematics, Physics, Chemistry, and Biology, sourced from the latest real-world exam papers and designed to grow over time. Our framework features several core innovations: 1) featuring an automated pipeline that continuously ingests and parses the latest examination papers to mitigate data leakage; and 2) proposing a novel `Mock Exam' evaluation scheme, which assesses the ability to complete end-to-end exams autonomously with accurate and efficient reasoning paths. Extensive experiments on 12 LMMs reveal that advanced models suffer substantial performance degradation under exam-realistic constraints: GPT-5's score drops from 79 to 53 (out of 100) when process rigor and efficiency are jointly evaluated. Our findings expose critical vulnerabilities, such as sensitivity to complex visual layouts, highlighting the gap between idealized reasoning capabilities and true educational readiness. Both code and dataset are publicly available.
Adaptive Global and Fine-Grained Perceptual Fusion for MLLM Embeddings Compatible with Hard Negative Amplification
Feb 05, 2026Multimodal embeddings serve as a bridge for aligning vision and language, with the two primary implementations -- CLIP-based and MLLM-based embedding models -- both limited to capturing only global semantic information. Although numerous studies have focused on fine-grained understanding, we observe that complex scenarios currently targeted by MLLM embeddings often involve a hybrid perceptual pattern of both global and fine-grained elements, thus necessitating a compatible fusion mechanism. In this paper, we propose Adaptive Global and Fine-grained perceptual Fusion for MLLM Embeddings (AGFF-Embed), a method that prompts the MLLM to generate multiple embeddings focusing on different dimensions of semantic information, which are then adaptively and smoothly aggregated. Furthermore, we adapt AGFF-Embed with the Explicit Gradient Amplification (EGA) technique to achieve in-batch hard negatives enhancement without requiring fine-grained editing of the dataset. Evaluation on the MMEB and MMVP-VLM benchmarks shows that AGFF-Embed comprehensively achieves state-of-the-art performance in both general and fine-grained understanding compared to other multimodal embedding models.
Concise Geometric Description as a Bridge: Unleashing the Potential of LLM for Plane Geometry Problem Solving
Jan 29, 2026Plane Geometry Problem Solving (PGPS) is a multimodal reasoning task that aims to solve a plane geometric problem based on a geometric diagram and problem textual descriptions. Although Large Language Models (LLMs) possess strong reasoning skills, their direct application to PGPS is hindered by their inability to process visual diagrams. Existing works typically fine-tune Multimodal LLMs (MLLMs) end-to-end on large-scale PGPS data to enhance visual understanding and reasoning simultaneously. However, such joint optimization may compromise base LLMs' inherent reasoning capability. In this work, we observe that LLM itself is potentially a powerful PGPS solver when appropriately formulating visual information as textual descriptions. We propose to train a MLLM Interpreter to generate geometric descriptions for the visual diagram, and an off-the-shelf LLM is utilized to perform reasoning. Specifically, we choose Conditional Declaration Language (CDL) as the geometric description as its conciseness eases the MLLM Interpreter training. The MLLM Interpreter is fine-tuned via CoT (Chain-of-Thought)-augmented SFT followed by GRPO to generate CDL. Instead of using a conventional solution-based reward that compares the reasoning result with the ground-truth answer, we design CDL matching rewards to facilitate more effective GRPO training, which provides more direct and denser guidance for CDL generation. To support training, we construct a new dataset, Formalgeo7k-Rec-CoT, by manually reviewing Formalgeo7k v2 and incorporating CoT annotations. Extensive experiments on Formalgeo7k-Rec-CoT, Unigeo, and MathVista show our method (finetuned on only 5.5k data) performs favorably against leading open-source and closed-source MLLMs.
Learning to Pose Problems: Reasoning-Driven and Solver-Adaptive Data Synthesis for Large Reasoning Models
Nov 13, 2025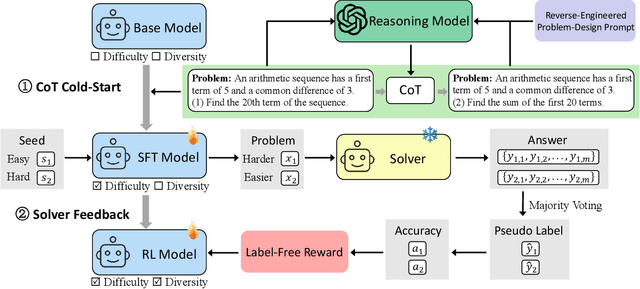
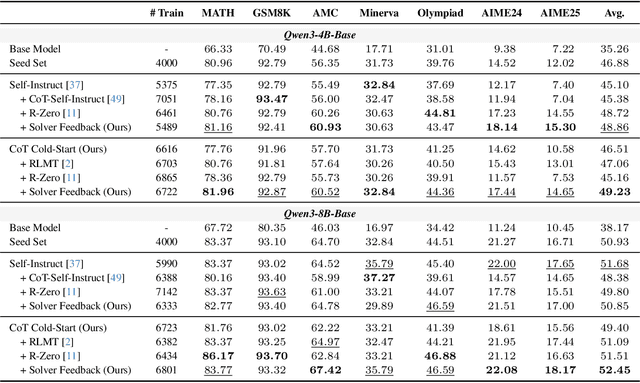

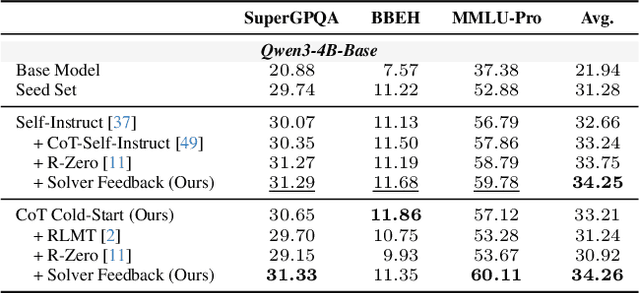
Data synthesis for training large reasoning models offers a scalable alternative to limited, human-curated datasets, enabling the creation of high-quality data. However, existing approaches face several challenges: (i) indiscriminate generation that ignores the solver's ability and yields low-value problems, or reliance on complex data pipelines to balance problem difficulty; and (ii) a lack of reasoning in problem generation, leading to shallow problem variants. In this paper, we develop a problem generator that reasons explicitly to plan problem directions before synthesis and adapts difficulty to the solver's ability. Specifically, we construct related problem pairs and augment them with intermediate problem-design CoT produced by a reasoning model. These data bootstrap problem-design strategies from the generator. Then, we treat the solver's feedback on synthetic problems as a reward signal, enabling the generator to calibrate difficulty and produce complementary problems near the edge of the solver's competence. Extensive experiments on 10 mathematical and general reasoning benchmarks show that our method achieves an average improvement of 2.5% and generalizes to both language and vision-language models. Moreover, a solver trained on the synthesized data provides improved rewards for continued generator training, enabling co-evolution and yielding a further 0.7% performance gain. Our code will be made publicly available here.
Fact-R1: Towards Explainable Video Misinformation Detection with Deep Reasoning
May 22, 2025The rapid spread of multimodal misinformation on social media has raised growing concerns, while research on video misinformation detection remains limited due to the lack of large-scale, diverse datasets. Existing methods often overfit to rigid templates and lack deep reasoning over deceptive content. To address these challenges, we introduce FakeVV, a large-scale benchmark comprising over 100,000 video-text pairs with fine-grained, interpretable annotations. In addition, we further propose Fact-R1, a novel framework that integrates deep reasoning with collaborative rule-based reinforcement learning. Fact-R1 is trained through a three-stage process: (1) misinformation long-Chain-of-Thought (CoT) instruction tuning, (2) preference alignment via Direct Preference Optimization (DPO), and (3) Group Relative Policy Optimization (GRPO) using a novel verifiable reward function. This enables Fact-R1 to exhibit emergent reasoning behaviors comparable to those observed in advanced text-based reinforcement learning systems, but in the more complex multimodal misinformation setting. Our work establishes a new paradigm for misinformation detection, bridging large-scale video understanding, reasoning-guided alignment, and interpretable verification.
Critique Before Thinking: Mitigating Hallucination through Rationale-Augmented Instruction Tuning
May 12, 2025Despite significant advancements in multimodal reasoning tasks, existing Large Vision-Language Models (LVLMs) are prone to producing visually ungrounded responses when interpreting associated images. In contrast, when humans embark on learning new knowledge, they often rely on a set of fundamental pre-study principles: reviewing outlines to grasp core concepts, summarizing key points to guide their focus and enhance understanding. However, such preparatory actions are notably absent in the current instruction tuning processes. This paper presents Re-Critic, an easily scalable rationale-augmented framework designed to incorporate fundamental rules and chain-of-thought (CoT) as a bridge to enhance reasoning abilities. Specifically, Re-Critic develops a visual rationale synthesizer that scalably augments raw instructions with rationale explanation. To probe more contextually grounded responses, Re-Critic employs an in-context self-critic mechanism to select response pairs for preference tuning. Experiments demonstrate that models fine-tuned with our rationale-augmented dataset yield gains that extend beyond hallucination-specific tasks to broader multimodal reasoning tasks.
Adaptive Subsampling and Learned Model Improve Spatiotemporal Resolution of Tactile Skin
Oct 17, 2024



High-speed tactile arrays are essential for real-time robotic control in unstructured environments, but high pixel counts limit readout rates of most large tactile arrays to below 100Hz. We introduce ACTS - adaptive compressive tactile subsampling - a method that efficiently samples tactile matrices and reconstructs interactions using sparse recovery and a learned tactile dictionary. Tested on a 1024-pixel sensor array (32x32), ACTS increased frame rates by 18X compared to raster scanning, with minimal error. For the first time in large-area tactile skin, we demonstrate rapid object classification within 20ms of contact, high-speed projectile detection, ricochet angle estimation, and deformation tracking through enhanced spatiotemporal resolution. Our method can be implemented in firmware, upgrading existing low-cost, flexible, and robust tactile arrays into high-resolution systems for large-area spatiotemporal touch sensing.
Innovative Thinking, Infinite Humor: Humor Research of Large Language Models through Structured Thought Leaps
Oct 14, 2024



Humor is a culturally nuanced aspect of human language that presents challenges for understanding and generation, requiring participants to possess good creativity and strong associative thinking. Similar to reasoning tasks like solving math problems, humor generation requires continuous reflection and revision to foster creative thinking, rather than relying on a sudden flash of inspiration like Creative Leap-of-Thought (CLoT) paradigm. Although CLoT can realize the ability of remote association generation, this paradigm fails to generate humor content. Therefore, in this paper, we propose a systematic way of thinking about generating humor and based on it, we built Creative Leap of Structured Thought (CLoST) frame. First, a reward model is necessary achieve the purpose of being able to correct errors, since there is currently no expert model of humor and a usable rule to determine whether a piece of content is humorous. Judgement-oriented instructions are designed to improve the capability of a model, and we also propose an open-domain instruction evolutionary method to fully unleash the potential. Then, through reinforcement learning, the model learns to hone its rationales of the thought chain and refine the strategies it uses. Thus, it learns to recognize and correct its mistakes, and finally generate the most humorous and creative answer. These findings deepen our understanding of the creative capabilities of LLMs and provide ways to enhance LLMs' creative abilities for cross-domain innovative applications.
Chip-Tuning: Classify Before Language Models Say
Oct 09, 2024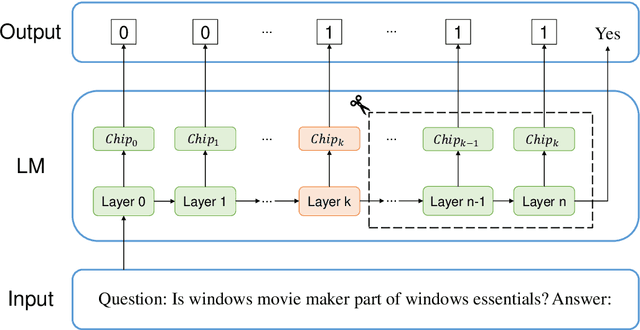
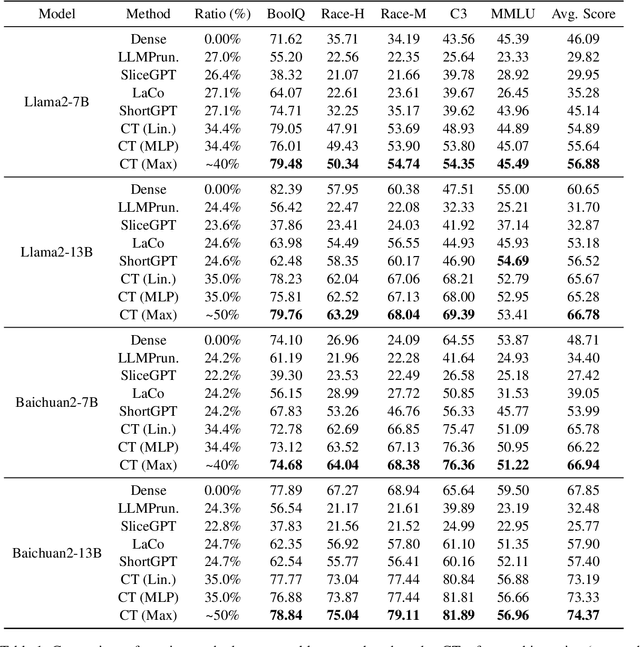
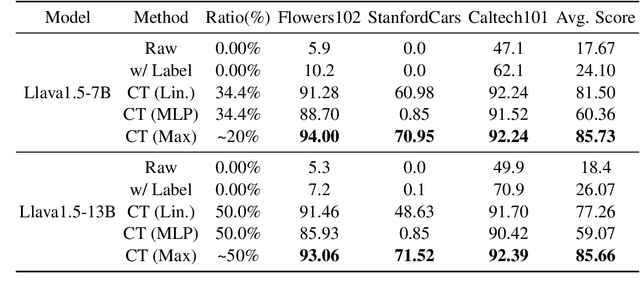
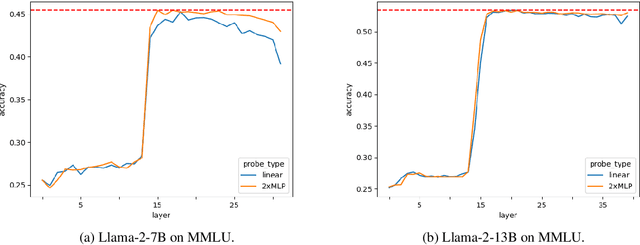
The rapid development in the performance of large language models (LLMs) is accompanied by the escalation of model size, leading to the increasing cost of model training and inference. Previous research has discovered that certain layers in LLMs exhibit redundancy, and removing these layers brings only marginal loss in model performance. In this paper, we adopt the probing technique to explain the layer redundancy in LLMs and demonstrate that language models can be effectively pruned with probing classifiers. We propose chip-tuning, a simple and effective structured pruning framework specialized for classification problems. Chip-tuning attaches tiny probing classifiers named chips to different layers of LLMs, and trains chips with the backbone model frozen. After selecting a chip for classification, all layers subsequent to the attached layer could be removed with marginal performance loss. Experimental results on various LLMs and datasets demonstrate that chip-tuning significantly outperforms previous state-of-the-art baselines in both accuracy and pruning ratio, achieving a pruning ratio of up to 50%. We also find that chip-tuning could be applied on multimodal models, and could be combined with model finetuning, proving its excellent compatibility.