 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Fidelity Generative Audio Compression at 0.275kbps
Jan 31, 2026High-fidelity general audio compression at ultra-low bitrates is crucial for applications ranging from low-bandwidth communication to generative audio-language modeling. Traditional audio compression methods and contemporary neural codecs are fundamentally designed for waveform reconstruction. As a result, when operating at ultra-low bitrates, these methods degrade rapidly and often fail to preserve essential information, leading to severe acoustic artifacts and pronounced semantic distortion. To overcome these limitations, we introduce Generative Audio Compression (GAC), a novel paradigm shift from signal fidelity to task-oriented effectiveness. Implemented within the AI Flow framework, GAC is theoretically grounded in the Law of Information Capacity. These foundations posit that abundant computational power can be leveraged at the receiver to offset extreme communication bottlenecks--exemplifying the More Computation, Less Bandwidth philosophy. By integrating semantic understanding at the transmitter with scalable generative synthesis at the receiver, GAC offloads the information burden to powerful model priors. Our 1.8B-parameter model achieves high-fidelity reconstruction of 32kHz general audio at an unprecedented bitrate of 0.275kbps. Even at 0.175kbps, it still preserves a strong intelligible audio transmission capability, which represents an about 3000x compression ratio, significantly outperforming current state-of-the-art neural codecs in maintaining both perceptual quality and semantic consistency.
Rare Word Recognition and Translation Without Fine-Tuning via Task Vector in Speech Models
Dec 26, 2025Rare words remain a critical bottleneck for speech-to-text systems. While direct fine-tuning improves recognition of target words, it often incurs high cost, catastrophic forgetting, and limited scalability. To address these challenges, we propose a training-free paradigm based on task vectors for rare word recognition and translation. By defining task vectors as parameter differences and introducing word-level task vector arithmetic, our approach enables flexible composition of rare-word capabilities, greatly enhancing scalability and reusability. Extensive experiments across multiple domains show that the proposed method matches or surpasses fine-tuned models on target words, improves general performance by about 5 BLEU, and mitigates catastrophic forgetting.
YuE: Scaling Open Foundation Models for Long-Form Music Generation
Mar 11, 2025We tackle the task of long-form music generation--particularly the challenging \textbf{lyrics-to-song} problem--by introducing YuE, a family of open foundation models based on the LLaMA2 architecture. Specifically, YuE scales to trillions of tokens and generates up to five minutes of music while maintaining lyrical alignment, coherent musical structure, and engaging vocal melodies with appropriate accompaniment. It achieves this through (1) track-decoupled next-token prediction to overcome dense mixture signals, (2) structural progressive conditioning for long-context lyrical alignment, and (3) a multitask, multiphase pre-training recipe to converge and generalize. In addition, we redesign the in-context learning technique for music generation, enabling versatile style transfer (e.g., converting Japanese city pop into an English rap while preserving the original accompaniment) and bidirectional generation. Through extensive evaluation, we demonstrate that YuE matches or even surpasses some of the proprietary systems in musicality and vocal agility. In addition, fine-tuning YuE enables additional controls and enhanced support for tail languages. Furthermore, beyond generation, we show that YuE's learned representations can perform well on music understanding tasks, where the results of YuE match or exceed state-of-the-art methods on the MARBLE benchmark. Keywords: lyrics2song, song generation, long-form, foundation model, music generation
MuMu-LLaMA: Multi-modal Music Understanding and Generation via Large Language Models
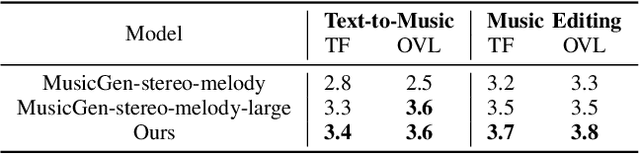
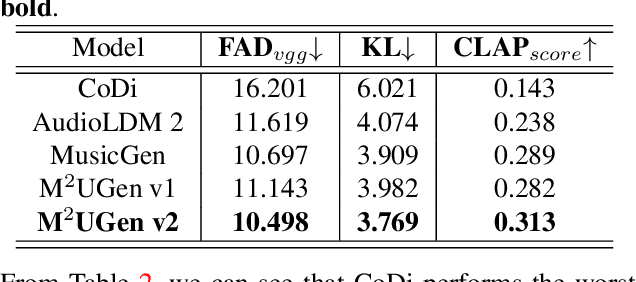
Dec 09, 2024Research on large language models has advanced significantly across text, speech, images, and videos. However, multi-modal music understanding and generation remain underexplored due to the lack of well-annotated datasets. To address this, we introduce a dataset with 167.69 hours of multi-modal data, including text, images, videos, and music annotations. Based on this dataset, we propose MuMu-LLaMA, a model that leverages pre-trained encoders for music, images, and videos. For music generation, we integrate AudioLDM 2 and MusicGen. Our evaluation across four tasks--music understanding, text-to-music generation, prompt-based music editing, and multi-modal music generation--demonstrates that MuMu-LLaMA outperforms state-of-the-art models, showing its potential for multi-modal music applications.
Editing Music with Melody and Text: Using ControlNet for Diffusion Transformer
Oct 07, 2024

Despite the significant progress in controllable music generation and editing, challenges remain in the quality and length of generated music due to the use of Mel-spectrogram representations and UNet-based model structures. To address these limitations, we propose a novel approach using a Diffusion Transformer (DiT) augmented with an additional control branch using ControlNet. This allows for long-form and variable-length music generation and editing controlled by text and melody prompts. For more precise and fine-grained melody control, we introduce a novel top-$k$ constant-Q Transform representation as the melody prompt, reducing ambiguity compared to previous representations (e.g., chroma), particularly for music with multiple tracks or a wide range of pitch values. To effectively balance the control signals from text and melody prompts, we adopt a curriculum learning strategy that progressively masks the melody prompt, resulting in a more stable training process. Experiments have been performed on text-to-music generation and music-style transfer tasks using open-source instrumental recording data. The results demonstrate that by extending StableAudio, a pre-trained text-controlled DiT model, our approach enables superior melody-controlled editing while retaining good text-to-music generation performance. These results outperform a strong MusicGen baseline in terms of both text-based generation and melody preservation for editing. Audio examples can be found at https://stable-audio-control.github.io/web/.
M$^{2}$UGen: Multi-modal Music Understanding and Generation with the Power of Large Language Models
Nov 28, 2023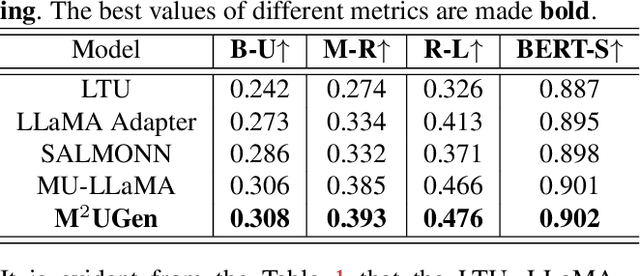


The current landscape of research leveraging large language models (LLMs) is experiencing a surge. Many works harness the powerful reasoning capabilities of these models to comprehend various modalities, such as text, speech, images, videos, etc. They also utilize LLMs to understand human intention and generate desired outputs like images, videos, and music. However, research that combines both understanding and generation using LLMs is still limited and in its nascent stage. To address this gap, we introduce a Multi-modal Music Understanding and Generation (M$^{2}$UGen) framework that integrates LLM's abilities to comprehend and generate music for different modalities. The M$^{2}$UGen framework is purpose-built to unlock creative potential from diverse sources of inspiration, encompassing music, image, and video through the use of pretrained MERT, ViT, and ViViT models, respectively. To enable music generation, we explore the use of AudioLDM 2 and MusicGen. Bridging multi-modal understanding and music generation is accomplished through the integration of the LLaMA 2 model. Furthermore, we make use of the MU-LLaMA model to generate extensive datasets that support text/image/video-to-music generation, facilitating the training of our M$^{2}$UGen framework. We conduct a thorough evaluation of our proposed framework. The experimental results demonstrate that our model achieves or surpasses the performance of the current state-of-the-art models.
HumTrans: A Novel Open-Source Dataset for Humming Melody Transcription and Beyond
Sep 18, 2023



This paper introduces the HumTrans dataset, which is publicly available and primarily designed for humming melody transcription. The dataset can also serve as a foundation for downstream tasks such as humming melody based music generation. It consists of 500 musical compositions of different genres and languages, with each composition divided into multiple segments. In total, the dataset comprises 1000 music segments. To collect this humming dataset, we employed 10 college students, all of whom are either music majors or proficient in playing at least one musical instrument. Each of them hummed every segment twice using the web recording interface provided by our designed website. The humming recordings were sampled at a frequency of 44,100 Hz. During the humming session, the main interface provides a musical score for students to reference, with the melody audio playing simultaneously to aid in capturing both melody and rhythm. The dataset encompasses approximately 56.22 hours of audio, making it the largest known humming dataset to date. The dataset will be released on Hugging Face, and we will provide a GitHub repository containing baseline results and evaluation codes.
Music Understanding LLaMA: Advancing Text-to-Music Generation with Question Answering and Captioning
Aug 22, 2023Text-to-music generation (T2M-Gen) faces a major obstacle due to the scarcity of large-scale publicly available music datasets with natural language captions. To address this, we propose the Music Understanding LLaMA (MU-LLaMA), capable of answering music-related questions and generating captions for music files. Our model utilizes audio representations from a pretrained MERT model to extract music features. However, obtaining a suitable dataset for training the MU-LLaMA model remains challenging, as existing publicly accessible audio question answering datasets lack the necessary depth for open-ended music question answering. To fill this gap, we present a methodology for generating question-answer pairs from existing audio captioning datasets and introduce the MusicQA Dataset designed for answering open-ended music-related questions. The experiments demonstrate that the proposed MU-LLaMA model, trained on our designed MusicQA dataset, achieves outstanding performance in both music question answering and music caption generation across various metrics, outperforming current state-of-the-art (SOTA) models in both fields and offering a promising advancement in the T2M-Gen research field.
A Hierarchical Speaker Representation Framework for One-shot Singing Voice Conversion
Jul 06, 2022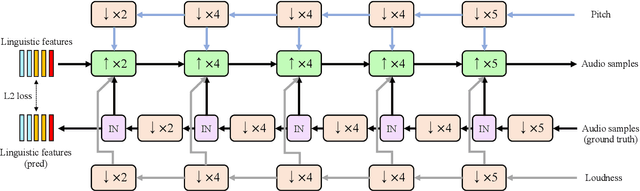
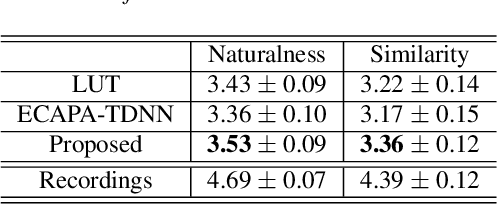
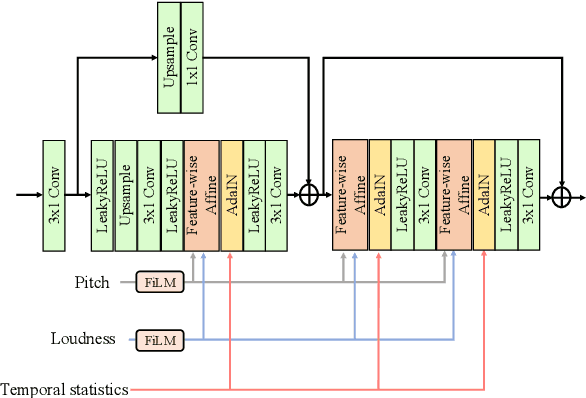

Typically, singing voice conversion (SVC) depends on an embedding vector, extracted from either a speaker lookup table (LUT) or a speaker recognition network (SRN), to model speaker identity. However, singing contains more expressive speaker characteristics than conversational speech. It is suspected that a single embedding vector may only capture averaged and coarse-grained speaker characteristics, which is insufficient for the SVC task. To this end, this work proposes a novel hierarchical speaker representation framework for SVC, which can capture fine-grained speaker characteristics at different granularity. It consists of an up-sampling stream and three down-sampling streams. The up-sampling stream transforms the linguistic features into audio samples, while one down-sampling stream of the three operates in the reverse direction. It is expected that the temporal statistics of each down-sampling block can represent speaker characteristics at different granularity, which will be engaged in the up-sampling blocks to enhance the speaker modeling. Experiment results verify that the proposed method outperforms both the LUT and SRN based SVC systems. Moreover, the proposed system supports the one-shot SVC with only a few seconds of reference audio.
Exploiting Cross Domain Acoustic-to-articulatory Inverted Features For Disordered Speech Recognition
Mar 19, 2022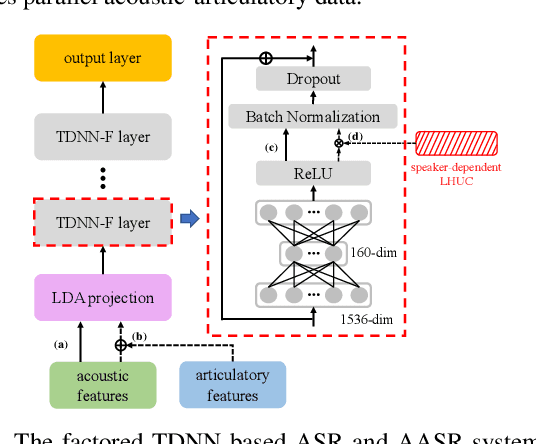
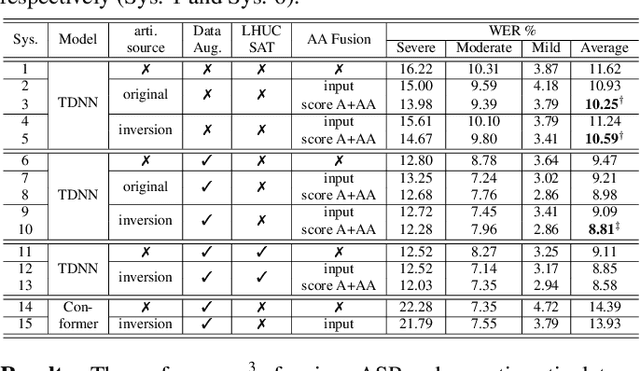
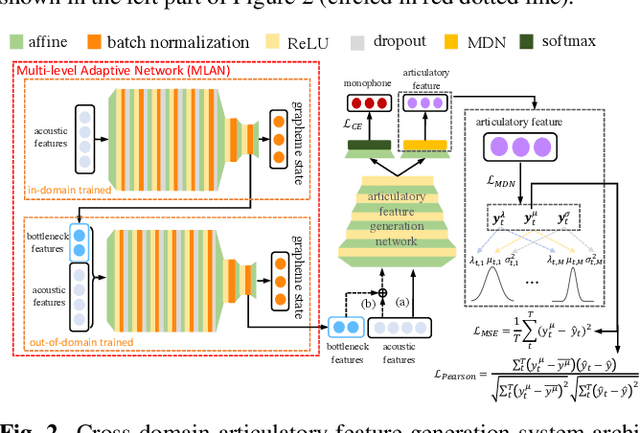
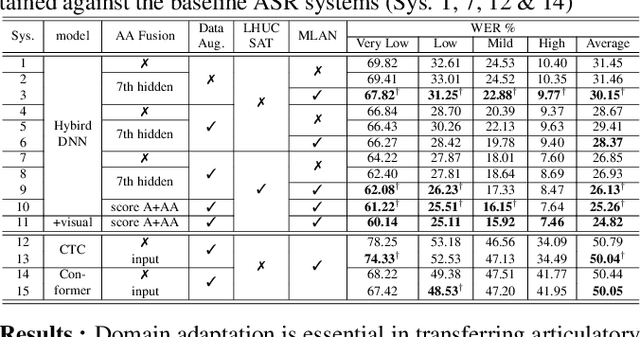
Articulatory features are inherently invariant to acoustic signal distortion and have been successfully incorporated into automatic speech recognition (ASR) systems for normal speech. Their practical application to disordered speech recognition is often limited by the difficulty in collecting such specialist data from impaired speakers. This paper presents a cross-domain acoustic-to-articulatory (A2A) inversion approach that utilizes the parallel acoustic-articulatory data of the 15-hour TORGO corpus in model training before being cross-domain adapted to the 102.7-hour UASpeech corpus and to produce articulatory features. Mixture density networks based neural A2A inversion models were used. A cross-domain feature adaptation network was also used to reduce the acoustic mismatch between the TORGO and UASpeech data. On both tasks, incorporating the A2A generated articulatory features consistently outperformed the baseline hybrid DNN/TDNN, CTC and Conformer based end-to-end systems constructed using acoustic features only. The best multi-modal system incorporating video modality and the cross-domain articulatory features as well as data augmentation and learning hidden unit contributions (LHUC) speaker adaptation produced the lowest published word error rate (WER) of 24.82% on the 16 dysarthric speakers of the benchmark UASpeech task.