 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEditing Music with Melody and Text: Using ControlNet for Diffusion Transformer
Oct 07, 2024

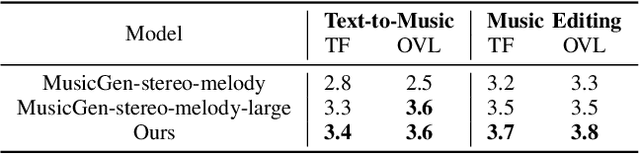
Despite the significant progress in controllable music generation and editing, challenges remain in the quality and length of generated music due to the use of Mel-spectrogram representations and UNet-based model structures. To address these limitations, we propose a novel approach using a Diffusion Transformer (DiT) augmented with an additional control branch using ControlNet. This allows for long-form and variable-length music generation and editing controlled by text and melody prompts. For more precise and fine-grained melody control, we introduce a novel top-$k$ constant-Q Transform representation as the melody prompt, reducing ambiguity compared to previous representations (e.g., chroma), particularly for music with multiple tracks or a wide range of pitch values. To effectively balance the control signals from text and melody prompts, we adopt a curriculum learning strategy that progressively masks the melody prompt, resulting in a more stable training process. Experiments have been performed on text-to-music generation and music-style transfer tasks using open-source instrumental recording data. The results demonstrate that by extending StableAudio, a pre-trained text-controlled DiT model, our approach enables superior melody-controlled editing while retaining good text-to-music generation performance. These results outperform a strong MusicGen baseline in terms of both text-based generation and melody preservation for editing. Audio examples can be found at https://stable-audio-control.github.io/web/.