 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigation of Data Augmentation Techniques for Disordered Speech Recognition
Paper and Code
Jan 14, 2022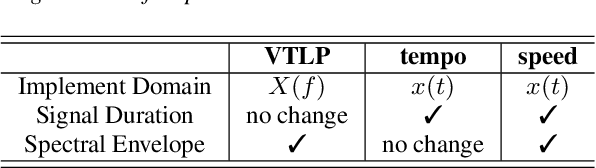
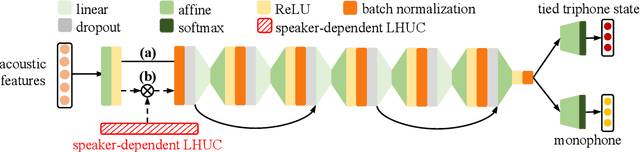
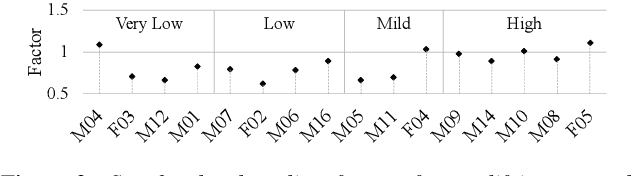
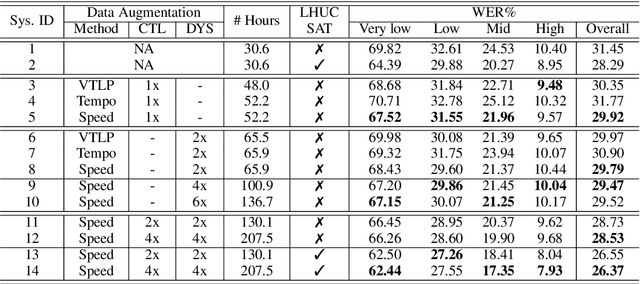
Disordered speech recognition is a highly challenging task. The underlying neuro-motor conditions of people with speech disorders, often compounded with co-occurring physical disabilities, lead to the difficulty in collecting large quantities of speech required for system development. This paper investigates a set of data augmentation techniques for disordered speech recognition, including vocal tract length perturbation (VTLP), tempo perturbation and speed perturbation. Both normal and disordered speech were exploited in the augmentation process. Variability among impaired speakers in both the original and augmented data was modeled using learning hidden unit contributions (LHUC) based speaker adaptive training. The final speaker adapted system constructed using the UASpeech corpus and the best augmentation approach based on speed perturbation produced up to 2.92% absolute (9.3% relative) word error rate (WER) reduction over the baseline system without data augmentation, and gave an overall WER of 26.37% on the test set containing 16 dysarthric speakers.