 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Value of AI-Generated Metadata for UGC Platforms: Evidence from a Large-scale Field Experiment
Dec 24, 2024



AI-generated content (AIGC), such as advertisement copy, product descriptions, and social media posts, is becoming ubiquitous in business practices. However, the value of AI-generated metadata, such as titles, remains unclear on user-generated content (UGC) platforms. To address this gap, we conducted a large-scale field experiment on a leading short-video platform in Asia to provide about 1 million users access to AI-generated titles for their uploaded videos. Our findings show that the provision of AI-generated titles significantly boosted content consumption, increasing valid watches by 1.6% and watch duration by 0.9%. When producers adopted these titles, these increases jumped to 7.1% and 4.1%, respectively. This viewership-boost effect was largely attributed to the use of this generative AI (GAI) tool increasing the likelihood of videos having a title by 41.4%. The effect was more pronounced for groups more affected by metadata sparsity. Mechanism analysis revealed that AI-generated metadata improved user-video matching accuracy in the platform's recommender system. Interestingly, for a video for which the producer would have posted a title anyway, adopting the AI-generated title decreased its viewership on average, implying that AI-generated titles may be of lower quality than human-generated ones. However, when producers chose to co-create with GAI and significantly revised the AI-generated titles, the videos outperformed their counterparts with either fully AI-generated or human-generated titles, showcasing the benefits of human-AI co-creation. This study highlights the value of AI-generated metadata and human-AI metadata co-creation in enhancing user-content matching and content consumption for UGC platforms.
MuMu-LLaMA: Multi-modal Music Understanding and Generation via Large Language Models
Dec 09, 2024Research on large language models has advanced significantly across text, speech, images, and videos. However, multi-modal music understanding and generation remain underexplored due to the lack of well-annotated datasets. To address this, we introduce a dataset with 167.69 hours of multi-modal data, including text, images, videos, and music annotations. Based on this dataset, we propose MuMu-LLaMA, a model that leverages pre-trained encoders for music, images, and videos. For music generation, we integrate AudioLDM 2 and MusicGen. Our evaluation across four tasks--music understanding, text-to-music generation, prompt-based music editing, and multi-modal music generation--demonstrates that MuMu-LLaMA outperforms state-of-the-art models, showing its potential for multi-modal music applications.
M$^{2}$UGen: Multi-modal Music Understanding and Generation with the Power of Large Language Models
Nov 28, 2023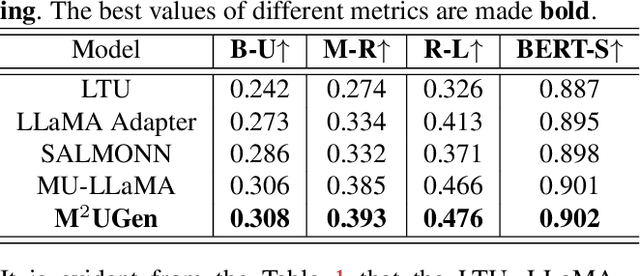

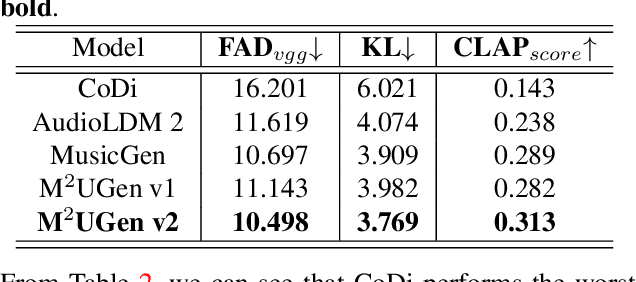

The current landscape of research leveraging large language models (LLMs) is experiencing a surge. Many works harness the powerful reasoning capabilities of these models to comprehend various modalities, such as text, speech, images, videos, etc. They also utilize LLMs to understand human intention and generate desired outputs like images, videos, and music. However, research that combines both understanding and generation using LLMs is still limited and in its nascent stage. To address this gap, we introduce a Multi-modal Music Understanding and Generation (M$^{2}$UGen) framework that integrates LLM's abilities to comprehend and generate music for different modalities. The M$^{2}$UGen framework is purpose-built to unlock creative potential from diverse sources of inspiration, encompassing music, image, and video through the use of pretrained MERT, ViT, and ViViT models, respectively. To enable music generation, we explore the use of AudioLDM 2 and MusicGen. Bridging multi-modal understanding and music generation is accomplished through the integration of the LLaMA 2 model. Furthermore, we make use of the MU-LLaMA model to generate extensive datasets that support text/image/video-to-music generation, facilitating the training of our M$^{2}$UGen framework. We conduct a thorough evaluation of our proposed framework. The experimental results demonstrate that our model achieves or surpasses the performance of the current state-of-the-art models.
Music Understanding LLaMA: Advancing Text-to-Music Generation with Question Answering and Captioning
Aug 22, 2023Text-to-music generation (T2M-Gen) faces a major obstacle due to the scarcity of large-scale publicly available music datasets with natural language captions. To address this, we propose the Music Understanding LLaMA (MU-LLaMA), capable of answering music-related questions and generating captions for music files. Our model utilizes audio representations from a pretrained MERT model to extract music features. However, obtaining a suitable dataset for training the MU-LLaMA model remains challenging, as existing publicly accessible audio question answering datasets lack the necessary depth for open-ended music question answering. To fill this gap, we present a methodology for generating question-answer pairs from existing audio captioning datasets and introduce the MusicQA Dataset designed for answering open-ended music-related questions. The experiments demonstrate that the proposed MU-LLaMA model, trained on our designed MusicQA dataset, achieves outstanding performance in both music question answering and music caption generation across various metrics, outperforming current state-of-the-art (SOTA) models in both fields and offering a promising advancement in the T2M-Gen research field.