 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvanced Reasoning and Transformation Engine for Multi-Step Insight Synthesis in Data Analytics with Large Language Models
Dec 18, 2024This paper presents the Advanced Reasoning and Transformation Engine for Multi-Step Insight Synthesis in Data Analytics (ARTEMIS-DA), a novel framework designed to augment Large Language Models (LLMs) for solving complex, multi-step data analytics tasks. ARTEMIS-DA integrates three core components: the Planner, which dissects complex user queries into structured, sequential instructions encompassing data preprocessing, transformation, predictive modeling, and visualization; the Coder, which dynamically generates and executes Python code to implement these instructions; and the Grapher, which interprets generated visualizations to derive actionable insights. By orchestrating the collaboration between these components, ARTEMIS-DA effectively manages sophisticated analytical workflows involving advanced reasoning, multi-step transformations, and synthesis across diverse data modalities. The framework achieves state-of-the-art (SOTA) performance on benchmarks such as WikiTableQuestions and TabFact, demonstrating its ability to tackle intricate analytical tasks with precision and adaptability. By combining the reasoning capabilities of LLMs with automated code generation and execution and visual analysis, ARTEMIS-DA offers a robust, scalable solution for multi-step insight synthesis, addressing a wide range of challenges in data analytics.
MuMu-LLaMA: Multi-modal Music Understanding and Generation via Large Language Models
Dec 09, 2024Research on large language models has advanced significantly across text, speech, images, and videos. However, multi-modal music understanding and generation remain underexplored due to the lack of well-annotated datasets. To address this, we introduce a dataset with 167.69 hours of multi-modal data, including text, images, videos, and music annotations. Based on this dataset, we propose MuMu-LLaMA, a model that leverages pre-trained encoders for music, images, and videos. For music generation, we integrate AudioLDM 2 and MusicGen. Our evaluation across four tasks--music understanding, text-to-music generation, prompt-based music editing, and multi-modal music generation--demonstrates that MuMu-LLaMA outperforms state-of-the-art models, showing its potential for multi-modal music applications.
Large Language Models for Judicial Entity Extraction: A Comparative Study
Jul 08, 2024Domain-specific Entity Recognition holds significant importance in legal contexts, serving as a fundamental task that supports various applications such as question-answering systems, text summarization, machine translation, sentiment analysis, and information retrieval specifically within case law documents. Recent advancements have highlighted the efficacy of Large Language Models in natural language processing tasks, demonstrating their capability to accurately detect and classify domain-specific facts (entities) from specialized texts like clinical and financial documents. This research investigates the application of Large Language Models in identifying domain-specific entities (e.g., courts, petitioner, judge, lawyer, respondents, FIR nos.) within case law documents, with a specific focus on their aptitude for handling domain-specific language complexity and contextual variations. The study evaluates the performance of state-of-the-art Large Language Model architectures, including Large Language Model Meta AI 3, Mistral, and Gemma, in the context of extracting judicial facts tailored to Indian judicial texts. Mistral and Gemma emerged as the top-performing models, showcasing balanced precision and recall crucial for accurate entity identification. These findings confirm the value of Large Language Models in judicial documents and demonstrate how they can facilitate and quicken scientific research by producing precise, organised data outputs that are appropriate for in-depth examination.
M$^{2}$UGen: Multi-modal Music Understanding and Generation with the Power of Large Language Models
Nov 28, 2023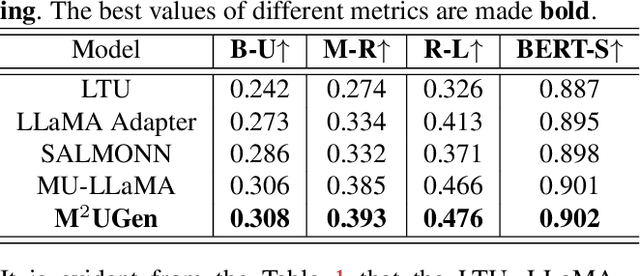

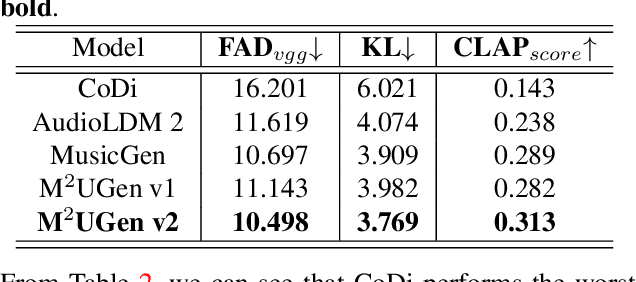

The current landscape of research leveraging large language models (LLMs) is experiencing a surge. Many works harness the powerful reasoning capabilities of these models to comprehend various modalities, such as text, speech, images, videos, etc. They also utilize LLMs to understand human intention and generate desired outputs like images, videos, and music. However, research that combines both understanding and generation using LLMs is still limited and in its nascent stage. To address this gap, we introduce a Multi-modal Music Understanding and Generation (M$^{2}$UGen) framework that integrates LLM's abilities to comprehend and generate music for different modalities. The M$^{2}$UGen framework is purpose-built to unlock creative potential from diverse sources of inspiration, encompassing music, image, and video through the use of pretrained MERT, ViT, and ViViT models, respectively. To enable music generation, we explore the use of AudioLDM 2 and MusicGen. Bridging multi-modal understanding and music generation is accomplished through the integration of the LLaMA 2 model. Furthermore, we make use of the MU-LLaMA model to generate extensive datasets that support text/image/video-to-music generation, facilitating the training of our M$^{2}$UGen framework. We conduct a thorough evaluation of our proposed framework. The experimental results demonstrate that our model achieves or surpasses the performance of the current state-of-the-art models.
Music Understanding LLaMA: Advancing Text-to-Music Generation with Question Answering and Captioning
Aug 22, 2023Text-to-music generation (T2M-Gen) faces a major obstacle due to the scarcity of large-scale publicly available music datasets with natural language captions. To address this, we propose the Music Understanding LLaMA (MU-LLaMA), capable of answering music-related questions and generating captions for music files. Our model utilizes audio representations from a pretrained MERT model to extract music features. However, obtaining a suitable dataset for training the MU-LLaMA model remains challenging, as existing publicly accessible audio question answering datasets lack the necessary depth for open-ended music question answering. To fill this gap, we present a methodology for generating question-answer pairs from existing audio captioning datasets and introduce the MusicQA Dataset designed for answering open-ended music-related questions. The experiments demonstrate that the proposed MU-LLaMA model, trained on our designed MusicQA dataset, achieves outstanding performance in both music question answering and music caption generation across various metrics, outperforming current state-of-the-art (SOTA) models in both fields and offering a promising advancement in the T2M-Gen research field.