 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhone-purity Guided Discrete Tokens for Dysarthric Speech Recognition
Jan 08, 2025



Discrete tokens extracted provide efficient and domain adaptable speech features. Their application to disordered speech that exhibits articulation imprecision and large mismatch against normal voice remains unexplored. To improve their phonetic discrimination that is weakened during unsupervised K-means or vector quantization of continuous features, this paper proposes novel phone-purity guided (PPG) discrete tokens for dysarthric speech recognition. Phonetic label supervision is used to regularize maximum likelihood and reconstruction error costs used in standard K-means and VAE-VQ based discrete token extraction. Experiments conducted on the UASpeech corpus suggest that the proposed PPG discrete token features extracted from HuBERT consistently outperform hybrid TDNN and End-to-End (E2E) Conformer systems using non-PPG based K-means or VAE-VQ tokens across varying codebook sizes by statistically significant word error rate (WER) reductions up to 0.99\% and 1.77\% absolute (3.21\% and 4.82\% relative) respectively on the UASpeech test set of 16 dysarthric speakers. The lowest WER of 23.25\% was obtained by combining systems using different token features. Consistent improvements on the phone purity metric were also achieved. T-SNE visualization further demonstrates sharper decision boundaries were produced between K-means/VAE-VQ clusters after introducing phone-purity guidance.
Effective and Efficient Mixed Precision Quantization of Speech Foundation Models
Jan 07, 2025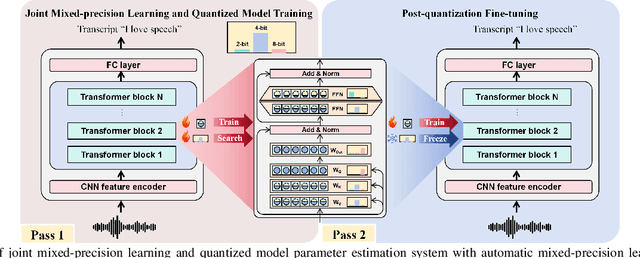
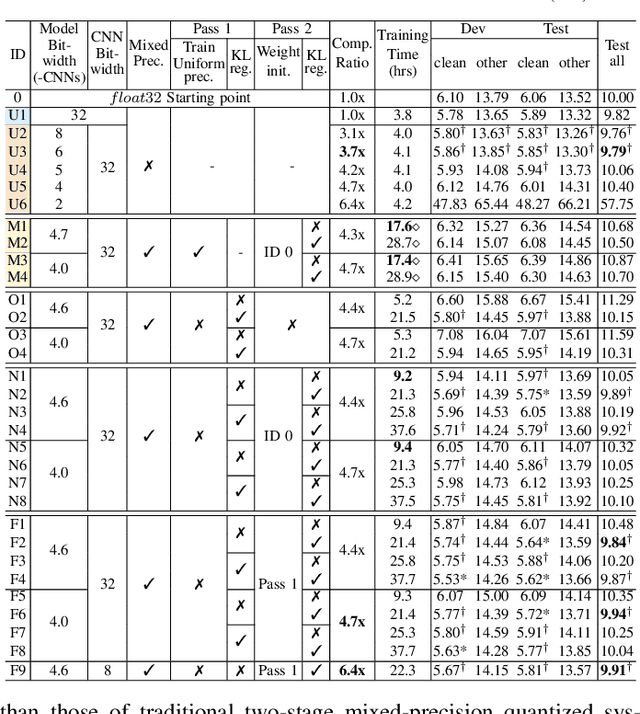
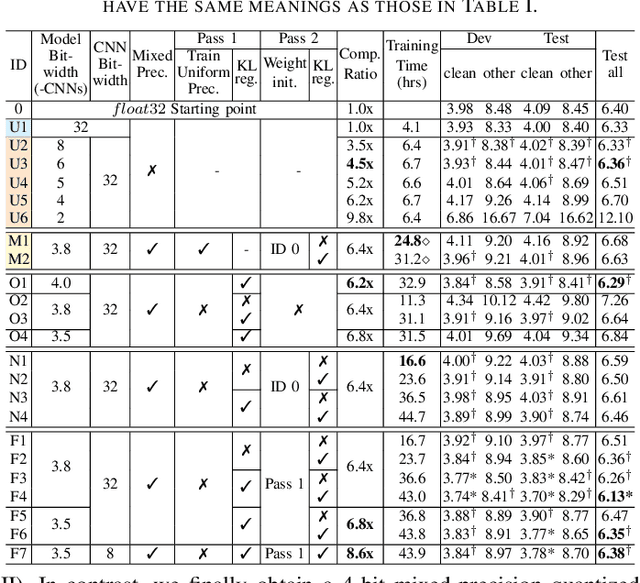
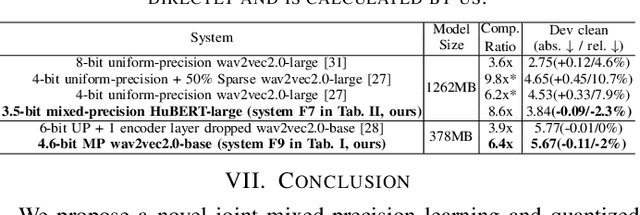
This paper presents a novel mixed-precision quantization approach for speech foundation models that tightly integrates mixed-precision learning and quantized model parameter estimation into one single model compression stage. Experiments conducted on LibriSpeech dataset with fine-tuned wav2vec2.0-base and HuBERT-large models suggest the resulting mixed-precision quantized models increased the lossless compression ratio by factors up to 1.7x and 1.9x over the respective uniform-precision and two-stage mixed-precision quantized baselines that perform precision learning and model parameters quantization in separate and disjointed stages, while incurring no statistically word error rate (WER) increase over the 32-bit full-precision models. The system compression time of wav2vec2.0-base and HuBERT-large models is reduced by up to 1.9 and 1.5 times over the two-stage mixed-precision baselines, while both produce lower WERs. The best-performing 3.5-bit mixed-precision quantized HuBERT-large model produces a lossless compression ratio of 8.6x over the 32-bit full-precision system.
Next Token Prediction Towards Multimodal Intelligence: A Comprehensive Survey
Dec 30, 2024



Building on the foundations of language modeling in natural language processing, Next Token Prediction (NTP) has evolved into a versatile training objective for machine learning tasks across various modalities, achieving considerable success. As Large Language Models (LLMs) have advanced to unify understanding and generation tasks within the textual modality, recent research has shown that tasks from different modalities can also be effectively encapsulated within the NTP framework, transforming the multimodal information into tokens and predict the next one given the context. This survey introduces a comprehensive taxonomy that unifies both understanding and generation within multimodal learning through the lens of NTP. The proposed taxonomy covers five key aspects: Multimodal tokenization, MMNTP model architectures, unified task representation, datasets \& evaluation, and open challenges. This new taxonomy aims to aid researchers in their exploration of multimodal intelligence. An associated GitHub repository collecting the latest papers and repos is available at https://github.com/LMM101/Awesome-Multimodal-Next-Token-Prediction
Structured Speaker-Deficiency Adaptation of Foundation Models for Dysarthric and Elderly Speech Recognition
Dec 25, 2024Data-intensive fine-tuning of speech foundation models (SFMs) to scarce and diverse dysarthric and elderly speech leads to data bias and poor generalization to unseen speakers. This paper proposes novel structured speaker-deficiency adaptation approaches for SSL pre-trained SFMs on such data. Speaker and speech deficiency invariant SFMs were constructed in their supervised adaptive fine-tuning stage to reduce undue bias to training data speakers, and serves as a more neutral and robust starting point for test time unsupervised adaptation. Speech variability attributed to speaker identity and speech impairment severity, or aging induced neurocognitive decline, are modelled using separate adapters that can be combined together to model any seen or unseen speaker. Experiments on the UASpeech dysarthric and DementiaBank Pitt elderly speech corpora suggest structured speaker-deficiency adaptation of HuBERT and Wav2vec2-conformer models consistently outperforms baseline SFMs using either: a) no adapters; b) global adapters shared among all speakers; or c) single attribute adapters modelling speaker or deficiency labels alone by statistically significant WER reductions up to 3.01% and 1.50% absolute (10.86% and 6.94% relative) on the two tasks respectively. The lowest published WER of 19.45% (49.34% on very low intelligibility, 33.17% on unseen words) is obtained on the UASpeech test set of 16 dysarthric speakers.
ARLON: Boosting Diffusion Transformers with Autoregressive Models for Long Video Generation
Oct 27, 2024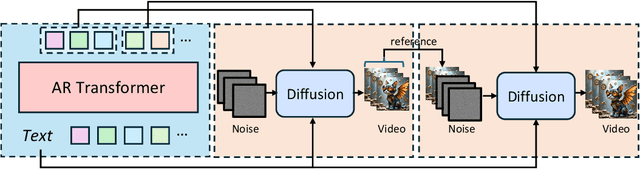
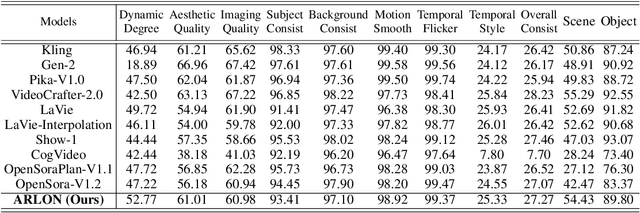
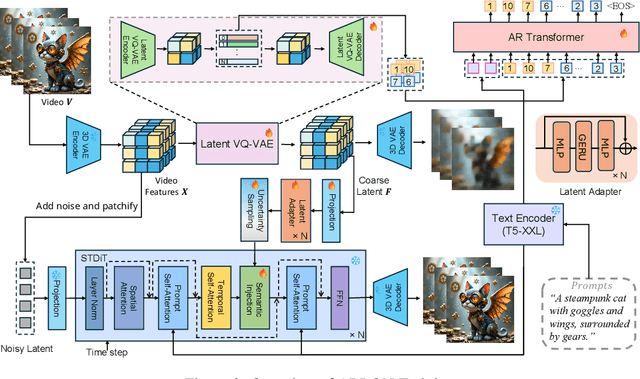
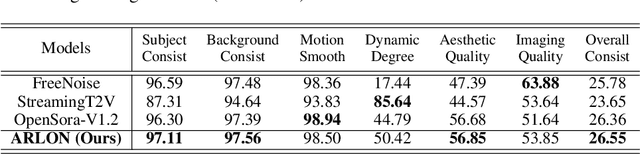
Text-to-video models have recently undergone rapid and substantial advancements. Nevertheless, due to limitations in data and computational resources, achieving efficient generation of long videos with rich motion dynamics remains a significant challenge. To generate high-quality, dynamic, and temporally consistent long videos, this paper presents ARLON, a novel framework that boosts diffusion Transformers with autoregressive models for long video generation, by integrating the coarse spatial and long-range temporal information provided by the AR model to guide the DiT model. Specifically, ARLON incorporates several key innovations: 1) A latent Vector Quantized Variational Autoencoder (VQ-VAE) compresses the input latent space of the DiT model into compact visual tokens, bridging the AR and DiT models and balancing the learning complexity and information density; 2) An adaptive norm-based semantic injection module integrates the coarse discrete visual units from the AR model into the DiT model, ensuring effective guidance during video generation; 3) To enhance the tolerance capability of noise introduced from the AR inference, the DiT model is trained with coarser visual latent tokens incorporated with an uncertainty sampling module. Experimental results demonstrate that ARLON significantly outperforms the baseline OpenSora-V1.2 on eight out of eleven metrics selected from VBench, with notable improvements in dynamic degree and aesthetic quality, while delivering competitive results on the remaining three and simultaneously accelerating the generation process. In addition, ARLON achieves state-of-the-art performance in long video generation. Detailed analyses of the improvements in inference efficiency are presented, alongside a practical application that demonstrates the generation of long videos using progressive text prompts. See demos of ARLON at \url{http://aka.ms/arlon}.
Large Language Model Can Transcribe Speech in Multi-Talker Scenarios with Versatile Instructions
Sep 13, 2024



Recent advancements in large language models (LLMs) have revolutionized various domains, bringing significant progress and new opportunities. Despite progress in speech-related tasks, LLMs have not been sufficiently explored in multi-talker scenarios. In this work, we present a pioneering effort to investigate the capability of LLMs in transcribing speech in multi-talker environments, following versatile instructions related to multi-talker automatic speech recognition (ASR), target talker ASR, and ASR based on specific talker attributes such as sex, occurrence order, language, and keyword spoken. Our approach utilizes WavLM and Whisper encoder to extract multi-faceted speech representations that are sensitive to speaker characteristics and semantic context. These representations are then fed into an LLM fine-tuned using LoRA, enabling the capabilities for speech comprehension and transcription. Comprehensive experiments reveal the promising performance of our proposed system, MT-LLM, in cocktail party scenarios, highlighting the potential of LLM to handle speech-related tasks based on user instructions in such complex settings.
Exploring SSL Discrete Speech Features for Zipformer-based Contextual ASR
Sep 13, 2024



Self-supervised learning (SSL) based discrete speech representations are highly compact and domain adaptable. In this paper, SSL discrete speech features extracted from WavLM models are used as additional cross-utterance acoustic context features in Zipformer-Transducer ASR systems. The efficacy of replacing Fbank features with discrete token features for modelling either cross-utterance contexts (from preceding and future segments), or current utterance's internal contexts alone, or both at the same time, are demonstrated thoroughly on the Gigaspeech 1000-hr corpus. The best Zipformer-Transducer system using discrete tokens based cross-utterance context features outperforms the baseline using utterance internal context only with statistically significant word error rate (WER) reductions of 0.32% to 0.41% absolute (2.78% to 3.54% relative) on the dev and test data. The lowest published WER of 11.15% and 11.14% were obtained on the dev and test sets. Our work is open-source and publicly available at https://github.com/open-creator/icefall/tree/master/egs/gigaspeech/Context\_ASR.
Autoregressive Speech Synthesis without Vector Quantization
Jul 11, 2024We present MELLE, a novel continuous-valued tokens based language modeling approach for text to speech synthesis (TTS). MELLE autoregressively generates continuous mel-spectrogram frames directly from text condition, bypassing the need for vector quantization, which are originally designed for audio compression and sacrifice fidelity compared to mel-spectrograms. Specifically, (i) instead of cross-entropy loss, we apply regression loss with a proposed spectrogram flux loss function to model the probability distribution of the continuous-valued tokens. (ii) we have incorporated variational inference into MELLE to facilitate sampling mechanisms, thereby enhancing the output diversity and model robustness. Experiments demonstrate that, compared to the two-stage codec language models VALL-E and its variants, the single-stage MELLE mitigates robustness issues by avoiding the inherent flaws of sampling discrete codes, achieves superior performance across multiple metrics, and, most importantly, offers a more streamlined paradigm. See https://aka.ms/melle for demos of our work.
Homogeneous Speaker Features for On-the-Fly Dysarthric and Elderly Speaker Adaptation
Jul 08, 2024
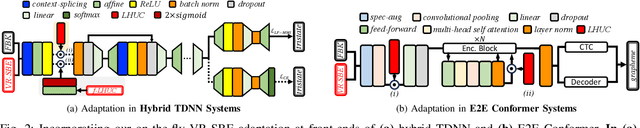


The application of data-intensive automatic speech recognition (ASR) technologies to dysarthric and elderly adult speech is confronted by their mismatch against healthy and nonaged voices, data scarcity and large speaker-level variability. To this end, this paper proposes two novel data-efficient methods to learn homogeneous dysarthric and elderly speaker-level features for rapid, on-the-fly test-time adaptation of DNN/TDNN and Conformer ASR models. These include: 1) speaker-level variance-regularized spectral basis embedding (VR-SBE) features that exploit a special regularization term to enforce homogeneity of speaker features in adaptation; and 2) feature-based learning hidden unit contributions (f-LHUC) transforms that are conditioned on VR-SBE features. Experiments are conducted on four tasks across two languages: the English UASpeech and TORGO dysarthric speech datasets, the English DementiaBank Pitt and Cantonese JCCOCC MoCA elderly speech corpora. The proposed on-the-fly speaker adaptation techniques consistently outperform baseline iVector and xVector adaptation by statistically significant word or character error rate reductions up to 5.32% absolute (18.57% relative) and batch-mode LHUC speaker adaptation by 2.24% absolute (9.20% relative), while operating with real-time factors speeding up to 33.6 times against xVectors during adaptation. The efficacy of the proposed adaptation techniques is demonstrated in a comparison against current ASR technologies including SSL pre-trained systems on UASpeech, where our best system produces a state-of-the-art WER of 23.33%. Analyses show VR-SBE features and f-LHUC transforms are insensitive to speaker-level data quantity in testtime adaptation. T-SNE visualization reveals they have stronger speaker-level homogeneity than baseline iVectors, xVectors and batch-mode LHUC transforms.
Towards Effective and Efficient Non-autoregressive Decoding Using Block-based Attention Mask
Jun 14, 2024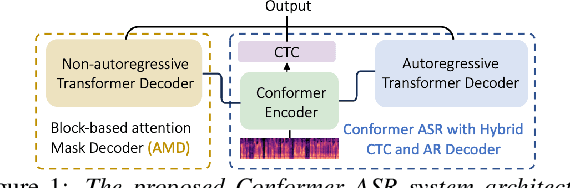
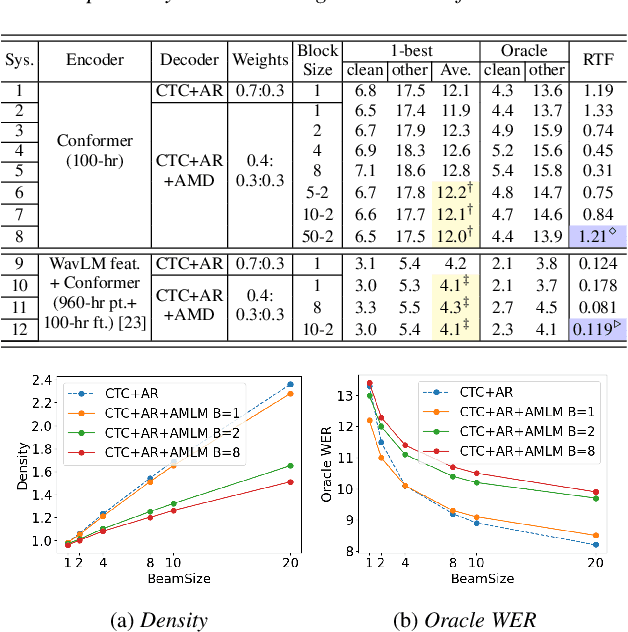
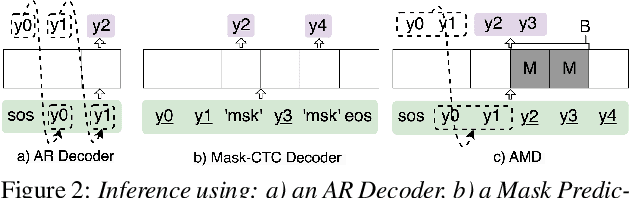
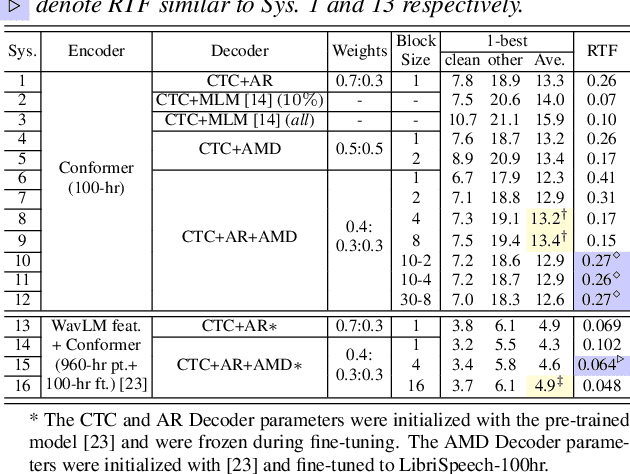
This paper proposes a novel non-autoregressive (NAR) block-based Attention Mask Decoder (AMD) that flexibly balances performance-efficiency trade-offs for Conformer ASR systems. AMD performs parallel NAR inference within contiguous blocks of output labels that are concealed using attention masks, while conducting left-to-right AR prediction and history context amalgamation between blocks. A beam search algorithm is designed to leverage a dynamic fusion of CTC, AR Decoder, and AMD probabilities. Experiments on the LibriSpeech-100hr corpus suggest the tripartite Decoder incorporating the AMD module produces a maximum decoding speed-up ratio of 1.73x over the baseline CTC+AR decoding, while incurring no statistically significant word error rate (WER) increase on the test sets. When operating with the same decoding real time factors, statistically significant WER reductions of up to 0.7% and 0.3% absolute (5.3% and 6.1% relative) were obtained over the CTC+AR baseline.