 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEND$^2$: Robust Dual-Decoder Watermarking Framework Against Non-Differentiable Distortions
Dec 13, 2024



DNN-based watermarking methods have rapidly advanced, with the ``Encoder-Noise Layer-Decoder'' (END) framework being the most widely used. To ensure end-to-end training, the noise layer in the framework must be differentiable. However, real-world distortions are often non-differentiable, leading to challenges in end-to-end training. Existing solutions only treat the distortion perturbation as additive noise, which does not fully integrate the effect of distortion in training. To better incorporate non-differentiable distortions into training, we propose a novel dual-decoder architecture (END$^2$). Unlike conventional END architecture, our method employs two structurally identical decoders: the Teacher Decoder, processing pure watermarked images, and the Student Decoder, handling distortion-perturbed images. The gradient is backpropagated only through the Teacher Decoder branch to optimize the encoder thus bypassing the problem of non-differentiability. To ensure resistance to arbitrary distortions, we enforce alignment of the two decoders' feature representations by maximizing the cosine similarity between their intermediate vectors on a hypersphere. Extensive experiments demonstrate that our scheme outperforms state-of-the-art algorithms under various non-differentiable distortions. Moreover, even without the differentiability constraint, our method surpasses baselines with a differentiable noise layer. Our approach is effective and easily implementable across all END architectures, enhancing practicality and generalizability.
ARLON: Boosting Diffusion Transformers with Autoregressive Models for Long Video Generation
Oct 27, 2024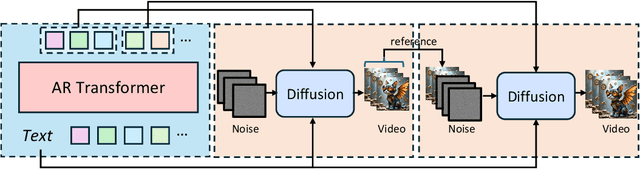
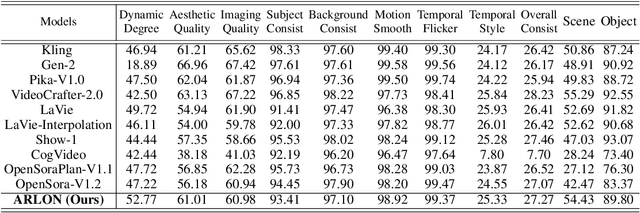
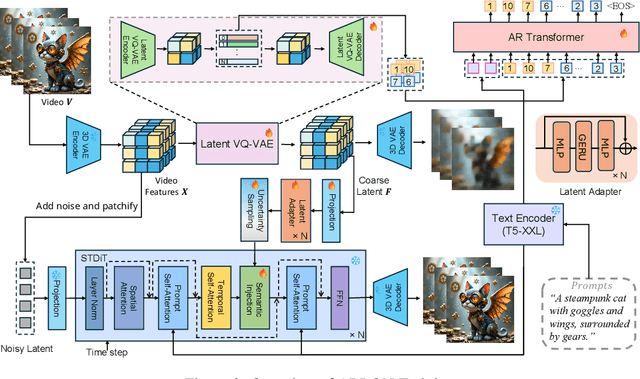
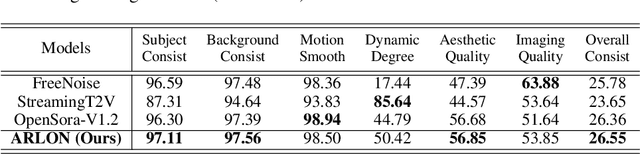
Text-to-video models have recently undergone rapid and substantial advancements. Nevertheless, due to limitations in data and computational resources, achieving efficient generation of long videos with rich motion dynamics remains a significant challenge. To generate high-quality, dynamic, and temporally consistent long videos, this paper presents ARLON, a novel framework that boosts diffusion Transformers with autoregressive models for long video generation, by integrating the coarse spatial and long-range temporal information provided by the AR model to guide the DiT model. Specifically, ARLON incorporates several key innovations: 1) A latent Vector Quantized Variational Autoencoder (VQ-VAE) compresses the input latent space of the DiT model into compact visual tokens, bridging the AR and DiT models and balancing the learning complexity and information density; 2) An adaptive norm-based semantic injection module integrates the coarse discrete visual units from the AR model into the DiT model, ensuring effective guidance during video generation; 3) To enhance the tolerance capability of noise introduced from the AR inference, the DiT model is trained with coarser visual latent tokens incorporated with an uncertainty sampling module. Experimental results demonstrate that ARLON significantly outperforms the baseline OpenSora-V1.2 on eight out of eleven metrics selected from VBench, with notable improvements in dynamic degree and aesthetic quality, while delivering competitive results on the remaining three and simultaneously accelerating the generation process. In addition, ARLON achieves state-of-the-art performance in long video generation. Detailed analyses of the improvements in inference efficiency are presented, alongside a practical application that demonstrates the generation of long videos using progressive text prompts. See demos of ARLON at \url{http://aka.ms/arlon}.
Adversarial Attacks on Both Face Recognition and Face Anti-spoofing Models
May 27, 2024
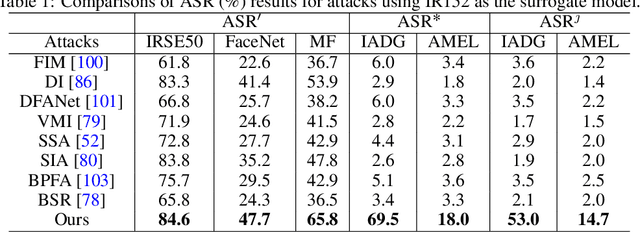

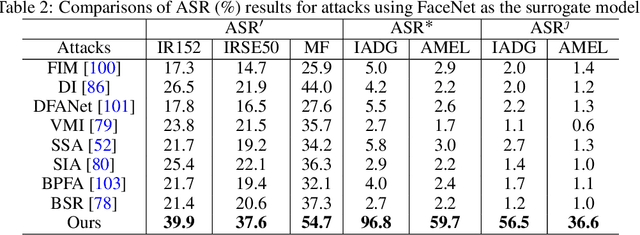
Adversarial attacks on Face Recognition (FR) systems have proven highly effective in compromising pure FR models, yet adversarial examples may be ineffective to the complete FR systems as Face Anti-Spoofing (FAS) models are often incorporated and can detect a significant number of them. To address this under-explored and essential problem, we propose a novel setting of adversarially attacking both FR and FAS models simultaneously, aiming to enhance the practicability of adversarial attacks on FR systems. In particular, we introduce a new attack method, namely Style-aligned Distribution Biasing (SDB), to improve the capacity of black-box attacks on both FR and FAS models. Specifically, our SDB framework consists of three key components. Firstly, to enhance the transferability of FAS models, we design a Distribution-aware Score Biasing module to optimize adversarial face examples away from the distribution of spoof images utilizing scores. Secondly, to mitigate the substantial style differences between live images and adversarial examples initialized with spoof images, we introduce an Instance Style Alignment module that aligns the style of adversarial examples with live images. In addition, to alleviate the conflicts between the gradients of FR and FAS models, we propose a Gradient Consistency Maintenance module to minimize disparities between the gradients using Hessian approximation. Extensive experiments showcase the superiority of our proposed attack method to state-of-the-art adversarial attacks.
Detecting Adversarial Data via Perturbation Forgery
May 25, 2024

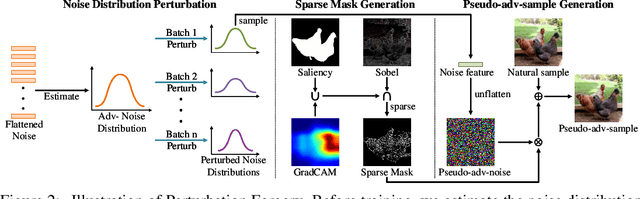
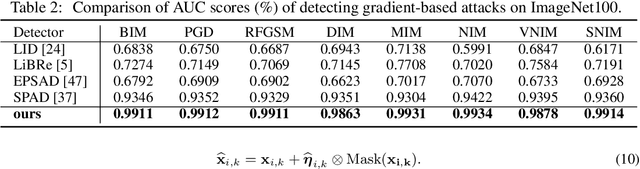
As a defense strategy against adversarial attacks, adversarial detection aims to identify and filter out adversarial data from the data flow based on discrepancies in distribution and noise patterns between natural and adversarial data. Although previous detection methods achieve high performance in detecting gradient-based adversarial attacks, new attacks based on generative models with imbalanced and anisotropic noise patterns evade detection. Even worse, existing techniques either necessitate access to attack data before deploying a defense or incur a significant time cost for inference, rendering them impractical for defending against newly emerging attacks that are unseen by defenders. In this paper, we explore the proximity relationship between adversarial noise distributions and demonstrate the existence of an open covering for them. By learning to distinguish this open covering from the distribution of natural data, we can develop a detector with strong generalization capabilities against all types of adversarial attacks. Based on this insight, we heuristically propose Perturbation Forgery, which includes noise distribution perturbation, sparse mask generation, and pseudo-adversarial data production, to train an adversarial detector capable of detecting unseen gradient-based, generative-model-based, and physical adversarial attacks, while remaining agnostic to any specific models. Comprehensive experiments conducted on multiple general and facial datasets, with a wide spectrum of attacks, validate the strong generalization of our method.
Picking watermarks from noise (PWFN): an improved robust watermarking model against intensive distortions
May 08, 2024
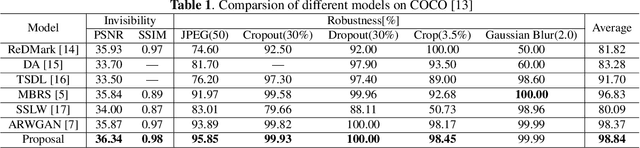
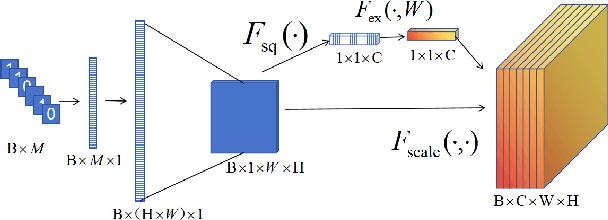

Digital watermarking is the process of embedding secret information by altering images in a way that is undetectable to the human eye. To increase the robustness of the model, many deep learning-based watermarking methods use the encoder-decoder architecture by adding different noises to the noise layer. The decoder then extracts the watermarked information from the distorted image. However, this method can only resist weak noise attacks. To improve the robustness of the algorithm against stronger noise, this paper proposes to introduce a denoise module between the noise layer and the decoder. The module is aimed at reducing noise and recovering some of the information lost during an attack. Additionally, the paper introduces the SE module to fuse the watermarking information pixel-wise and channel dimensions-wise, improving the encoder's efficiency. Experimental results show that our proposed method is comparable to existing models and outperforms state-of-the-art under different noise intensities. In addition, ablation experiments show the superiority of our proposed module.
DBDH: A Dual-Branch Dual-Head Neural Network for Invisible Embedded Regions Localization
May 06, 2024



Embedding invisible hyperlinks or hidden codes in images to replace QR codes has become a hot topic recently. This technology requires first localizing the embedded region in the captured photos before decoding. Existing methods that train models to find the invisible embedded region struggle to obtain accurate localization results, leading to degraded decoding accuracy. This limitation is primarily because the CNN network is sensitive to low-frequency signals, while the embedded signal is typically in the high-frequency form. Based on this, this paper proposes a Dual-Branch Dual-Head (DBDH) neural network tailored for the precise localization of invisible embedded regions. Specifically, DBDH uses a low-level texture branch containing 62 high-pass filters to capture the high-frequency signals induced by embedding. A high-level context branch is used to extract discriminative features between the embedded and normal regions. DBDH employs a detection head to directly detect the four vertices of the embedding region. In addition, we introduce an extra segmentation head to segment the mask of the embedding region during training. The segmentation head provides pixel-level supervision for model learning, facilitating better learning of the embedded signals. Based on two state-of-the-art invisible offline-to-online messaging methods, we construct two datasets and augmentation strategies for training and testing localization models. Extensive experiments demonstrate the superior performance of the proposed DBDH over existing methods.
SSyncOA: Self-synchronizing Object-aligned Watermarking to Resist Cropping-paste Attacks
May 06, 2024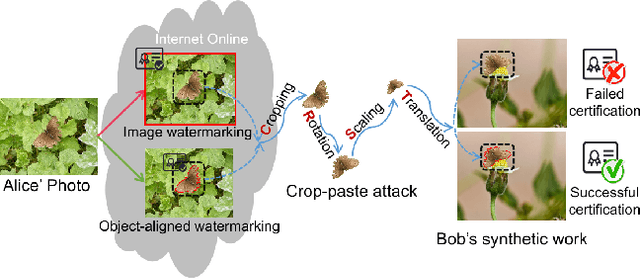

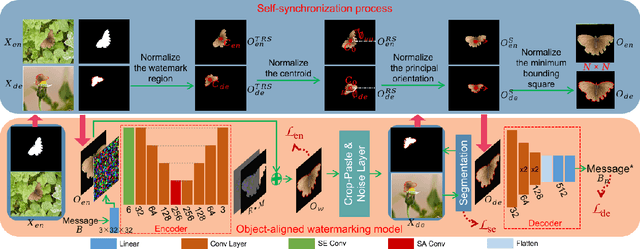

Modern image processing tools have made it easy for attackers to crop the region or object of interest in images and paste it into other images. The challenge this cropping-paste attack poses to the watermarking technology is that it breaks the synchronization of the image watermark, introducing multiple superimposed desynchronization distortions, such as rotation, scaling, and translation. However, current watermarking methods can only resist a single type of desynchronization and cannot be applied to protect the object's copyright under the cropping-paste attack. With the finding that the key to resisting the cropping-paste attack lies in robust features of the object to protect, this paper proposes a self-synchronizing object-aligned watermarking method, called SSyncOA. Specifically, we first constrain the watermarked region to be aligned with the protected object, and then synchronize the watermark's translation, rotation, and scaling distortions by normalizing the object invariant features, i.e., its centroid, principal orientation, and minimum bounding square, respectively. To make the watermark embedded in the protected object, we introduce the object-aligned watermarking model, which incorporates the real cropping-paste attack into the encoder-noise layer-decoder pipeline and is optimized end-to-end. Besides, we illustrate the effect of different desynchronization distortions on the watermark training, which confirms the necessity of the self-synchronization process. Extensive experiments demonstrate the superiority of our method over other SOTAs.
Improving the JPEG-resistance of Adversarial Attacks on Face Recognition by Interpolation Smoothing
Feb 26, 2024



JPEG compression can significantly impair the performance of adversarial face examples, which previous adversarial attacks on face recognition (FR) have not adequately addressed. Considering this challenge, we propose a novel adversarial attack on FR that aims to improve the resistance of adversarial examples against JPEG compression. Specifically, during the iterative process of generating adversarial face examples, we interpolate the adversarial face examples into a smaller size. Then we utilize these interpolated adversarial face examples to create the adversarial examples in the next iteration. Subsequently, we restore the adversarial face examples to their original size by interpolating. Throughout the entire process, our proposed method can smooth the adversarial perturbations, effectively mitigating the presence of high-frequency signals in the crafted adversarial face examples that are typically eliminated by JPEG compression. Our experimental results demonstrate the effectiveness of our proposed method in improving the JPEG-resistance of adversarial face examples.
Continual Adversarial Defense
Dec 15, 2023



In response to the rapidly evolving nature of adversarial attacks on a monthly basis, numerous defenses have been proposed to generalize against as many known attacks as possible. However, designing a defense method that can generalize to all types of attacks, including unseen ones, is not realistic because the environment in which defense systems operate is dynamic and comprises various unique attacks used by many attackers. The defense system needs to upgrade itself by utilizing few-shot defense feedback and efficient memory. Therefore, we propose the first continual adversarial defense (CAD) framework that adapts to any attacks in a dynamic scenario, where various attacks emerge stage by stage. In practice, CAD is modeled under four principles: (1) continual adaptation to new attacks without catastrophic forgetting, (2) few-shot adaptation, (3) memory-efficient adaptation, and (4) high accuracy on both clean and adversarial images. We leverage cutting-edge continual learning, few-shot learning, and ensemble learning techniques to qualify the principles. Experiments conducted on CIFAR-10 and ImageNet-100 validate the effectiveness of our approach against multiple stages of 10 modern adversarial attacks and significant improvements over 10 baseline methods. In particular, CAD is capable of quickly adapting with minimal feedback and a low cost of defense failure, while maintaining good performance against old attacks. Our research sheds light on a brand-new paradigm for continual defense adaptation against dynamic and evolving attacks.
Improving Visual Quality and Transferability of Adversarial Attacks on Face Recognition Simultaneously with Adversarial Restoration
Sep 13, 2023Adversarial face examples possess two critical properties: Visual Quality and Transferability. However, existing approaches rarely address these properties simultaneously, leading to subpar results. To address this issue, we propose a novel adversarial attack technique known as Adversarial Restoration (AdvRestore), which enhances both visual quality and transferability of adversarial face examples by leveraging a face restoration prior. In our approach, we initially train a Restoration Latent Diffusion Model (RLDM) designed for face restoration. Subsequently, we employ the inference process of RLDM to generate adversarial face examples. The adversarial perturbations are applied to the intermediate features of RLDM. Additionally, by treating RLDM face restoration as a sibling task, the transferability of the generated adversarial face examples is further improved. Our experimental results validate the effectiveness of the proposed attack method.