 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevling into Adversarial Transferability on Image Classification: Review, Benchmark, and Evaluation
Feb 26, 2026Adversarial transferability refers to the capacity of adversarial examples generated on the surrogate model to deceive alternate, unexposed victim models. This property eliminates the need for direct access to the victim model during an attack, thereby raising considerable security concerns in practical applications and attracting substantial research attention recently. In this work, we discern a lack of a standardized framework and criteria for evaluating transfer-based attacks, leading to potentially biased assessments of existing approaches. To rectify this gap, we have conducted an exhaustive review of hundreds of related works, organizing various transfer-based attacks into six distinct categories. Subsequently, we propose a comprehensive framework designed to serve as a benchmark for evaluating these attacks. In addition, we delineate common strategies that enhance adversarial transferability and highlight prevalent issues that could lead to unfair comparisons. Finally, we provide a brief review of transfer-based attacks beyond image classification.
Adversarial Attacks on Both Face Recognition and Face Anti-spoofing Models
May 27, 2024

Adversarial attacks on Face Recognition (FR) systems have proven highly effective in compromising pure FR models, yet adversarial examples may be ineffective to the complete FR systems as Face Anti-Spoofing (FAS) models are often incorporated and can detect a significant number of them. To address this under-explored and essential problem, we propose a novel setting of adversarially attacking both FR and FAS models simultaneously, aiming to enhance the practicability of adversarial attacks on FR systems. In particular, we introduce a new attack method, namely Style-aligned Distribution Biasing (SDB), to improve the capacity of black-box attacks on both FR and FAS models. Specifically, our SDB framework consists of three key components. Firstly, to enhance the transferability of FAS models, we design a Distribution-aware Score Biasing module to optimize adversarial face examples away from the distribution of spoof images utilizing scores. Secondly, to mitigate the substantial style differences between live images and adversarial examples initialized with spoof images, we introduce an Instance Style Alignment module that aligns the style of adversarial examples with live images. In addition, to alleviate the conflicts between the gradients of FR and FAS models, we propose a Gradient Consistency Maintenance module to minimize disparities between the gradients using Hessian approximation. Extensive experiments showcase the superiority of our proposed attack method to state-of-the-art adversarial attacks.
Improving the JPEG-resistance of Adversarial Attacks on Face Recognition by Interpolation Smoothing
Feb 26, 2024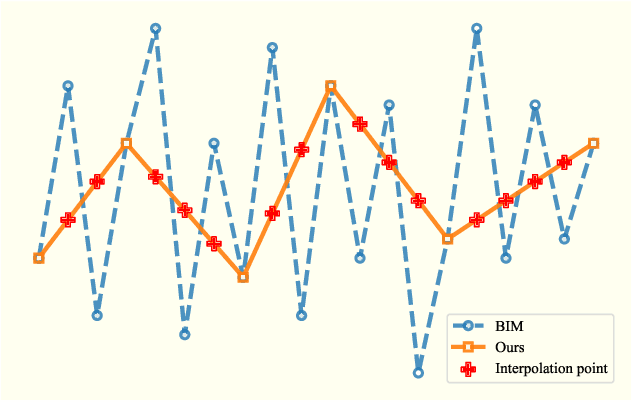



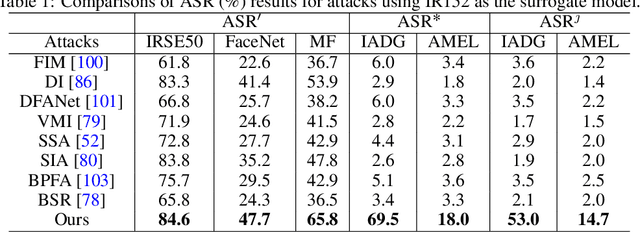
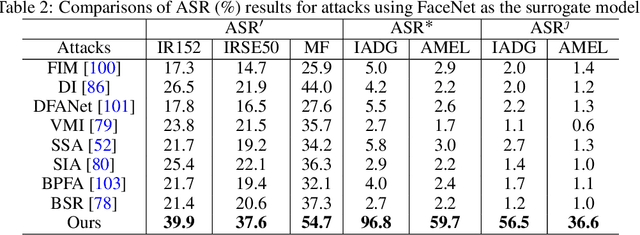
JPEG compression can significantly impair the performance of adversarial face examples, which previous adversarial attacks on face recognition (FR) have not adequately addressed. Considering this challenge, we propose a novel adversarial attack on FR that aims to improve the resistance of adversarial examples against JPEG compression. Specifically, during the iterative process of generating adversarial face examples, we interpolate the adversarial face examples into a smaller size. Then we utilize these interpolated adversarial face examples to create the adversarial examples in the next iteration. Subsequently, we restore the adversarial face examples to their original size by interpolating. Throughout the entire process, our proposed method can smooth the adversarial perturbations, effectively mitigating the presence of high-frequency signals in the crafted adversarial face examples that are typically eliminated by JPEG compression. Our experimental results demonstrate the effectiveness of our proposed method in improving the JPEG-resistance of adversarial face examples.
PPR: Enhancing Dodging Attacks while Maintaining Impersonation Attacks on Face Recognition Systems
Jan 17, 2024Adversarial Attacks on Face Recognition (FR) encompass two types: impersonation attacks and evasion attacks. We observe that achieving a successful impersonation attack on FR does not necessarily ensure a successful dodging attack on FR in the black-box setting. Introducing a novel attack method named Pre-training Pruning Restoration Attack (PPR), we aim to enhance the performance of dodging attacks whilst avoiding the degradation of impersonation attacks. Our method employs adversarial example pruning, enabling a portion of adversarial perturbations to be set to zero, while tending to maintain the attack performance. By utilizing adversarial example pruning, we can prune the pre-trained adversarial examples and selectively free up certain adversarial perturbations. Thereafter, we embed adversarial perturbations in the pruned area, which enhances the dodging performance of the adversarial face examples. The effectiveness of our proposed attack method is demonstrated through our experimental results, showcasing its superior performance.
Improving Visual Quality and Transferability of Adversarial Attacks on Face Recognition Simultaneously with Adversarial Restoration
Sep 13, 2023Adversarial face examples possess two critical properties: Visual Quality and Transferability. However, existing approaches rarely address these properties simultaneously, leading to subpar results. To address this issue, we propose a novel adversarial attack technique known as Adversarial Restoration (AdvRestore), which enhances both visual quality and transferability of adversarial face examples by leveraging a face restoration prior. In our approach, we initially train a Restoration Latent Diffusion Model (RLDM) designed for face restoration. Subsequently, we employ the inference process of RLDM to generate adversarial face examples. The adversarial perturbations are applied to the intermediate features of RLDM. Additionally, by treating RLDM face restoration as a sibling task, the transferability of the generated adversarial face examples is further improved. Our experimental results validate the effectiveness of the proposed attack method.
Improving Transferability of Adversarial Examples on Face Recognition with Beneficial Perturbation Feature Augmentation
Oct 28, 2022Face recognition (FR) models can be easily fooled by adversarial examples, which are crafted by adding imperceptible perturbations on benign face images. To improve the transferability of adversarial examples on FR models, we propose a novel attack method called Beneficial Perturbation Feature Augmentation Attack (BPFA), which reduces the overfitting of the adversarial examples to surrogate FR models by the adversarial strategy. Specifically, in the backpropagation step, BPFA records the gradients on pre-selected features and uses the gradient on the input image to craft adversarial perturbation to be added on the input image. In the next forward propagation step, BPFA leverages the recorded gradients to add perturbations(i.e., beneficial perturbations) that can be pitted against the adversarial perturbation added on the input image on their corresponding features. The above two steps are repeated until the last backpropagation step before the maximum number of iterations is reached. The optimization process of the adversarial perturbation added on the input image and the optimization process of the beneficial perturbations added on the features correspond to a minimax two-player game. Extensive experiments demonstrate that BPFA outperforms the state-of-the-art gradient-based adversarial attacks on FR.