 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Adversarial Data via Perturbation Forgery
May 25, 2024

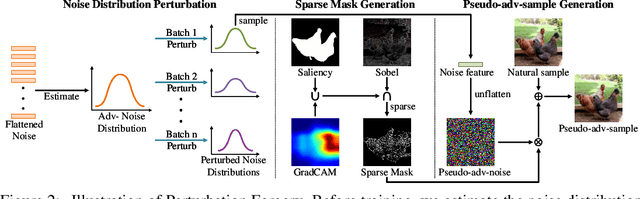
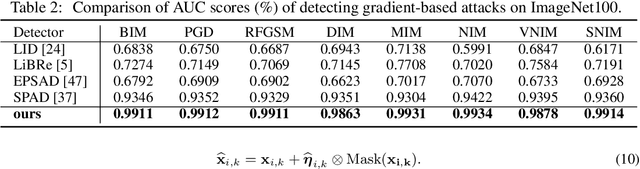
As a defense strategy against adversarial attacks, adversarial detection aims to identify and filter out adversarial data from the data flow based on discrepancies in distribution and noise patterns between natural and adversarial data. Although previous detection methods achieve high performance in detecting gradient-based adversarial attacks, new attacks based on generative models with imbalanced and anisotropic noise patterns evade detection. Even worse, existing techniques either necessitate access to attack data before deploying a defense or incur a significant time cost for inference, rendering them impractical for defending against newly emerging attacks that are unseen by defenders. In this paper, we explore the proximity relationship between adversarial noise distributions and demonstrate the existence of an open covering for them. By learning to distinguish this open covering from the distribution of natural data, we can develop a detector with strong generalization capabilities against all types of adversarial attacks. Based on this insight, we heuristically propose Perturbation Forgery, which includes noise distribution perturbation, sparse mask generation, and pseudo-adversarial data production, to train an adversarial detector capable of detecting unseen gradient-based, generative-model-based, and physical adversarial attacks, while remaining agnostic to any specific models. Comprehensive experiments conducted on multiple general and facial datasets, with a wide spectrum of attacks, validate the strong generalization of our method.
DBDH: A Dual-Branch Dual-Head Neural Network for Invisible Embedded Regions Localization
May 06, 2024



Embedding invisible hyperlinks or hidden codes in images to replace QR codes has become a hot topic recently. This technology requires first localizing the embedded region in the captured photos before decoding. Existing methods that train models to find the invisible embedded region struggle to obtain accurate localization results, leading to degraded decoding accuracy. This limitation is primarily because the CNN network is sensitive to low-frequency signals, while the embedded signal is typically in the high-frequency form. Based on this, this paper proposes a Dual-Branch Dual-Head (DBDH) neural network tailored for the precise localization of invisible embedded regions. Specifically, DBDH uses a low-level texture branch containing 62 high-pass filters to capture the high-frequency signals induced by embedding. A high-level context branch is used to extract discriminative features between the embedded and normal regions. DBDH employs a detection head to directly detect the four vertices of the embedding region. In addition, we introduce an extra segmentation head to segment the mask of the embedding region during training. The segmentation head provides pixel-level supervision for model learning, facilitating better learning of the embedded signals. Based on two state-of-the-art invisible offline-to-online messaging methods, we construct two datasets and augmentation strategies for training and testing localization models. Extensive experiments demonstrate the superior performance of the proposed DBDH over existing methods.
Continual Adversarial Defense
Dec 15, 2023



In response to the rapidly evolving nature of adversarial attacks on a monthly basis, numerous defenses have been proposed to generalize against as many known attacks as possible. However, designing a defense method that can generalize to all types of attacks, including unseen ones, is not realistic because the environment in which defense systems operate is dynamic and comprises various unique attacks used by many attackers. The defense system needs to upgrade itself by utilizing few-shot defense feedback and efficient memory. Therefore, we propose the first continual adversarial defense (CAD) framework that adapts to any attacks in a dynamic scenario, where various attacks emerge stage by stage. In practice, CAD is modeled under four principles: (1) continual adaptation to new attacks without catastrophic forgetting, (2) few-shot adaptation, (3) memory-efficient adaptation, and (4) high accuracy on both clean and adversarial images. We leverage cutting-edge continual learning, few-shot learning, and ensemble learning techniques to qualify the principles. Experiments conducted on CIFAR-10 and ImageNet-100 validate the effectiveness of our approach against multiple stages of 10 modern adversarial attacks and significant improvements over 10 baseline methods. In particular, CAD is capable of quickly adapting with minimal feedback and a low cost of defense failure, while maintaining good performance against old attacks. Our research sheds light on a brand-new paradigm for continual defense adaptation against dynamic and evolving attacks.
Improving Visual Quality and Transferability of Adversarial Attacks on Face Recognition Simultaneously with Adversarial Restoration
Sep 13, 2023Adversarial face examples possess two critical properties: Visual Quality and Transferability. However, existing approaches rarely address these properties simultaneously, leading to subpar results. To address this issue, we propose a novel adversarial attack technique known as Adversarial Restoration (AdvRestore), which enhances both visual quality and transferability of adversarial face examples by leveraging a face restoration prior. In our approach, we initially train a Restoration Latent Diffusion Model (RLDM) designed for face restoration. Subsequently, we employ the inference process of RLDM to generate adversarial face examples. The adversarial perturbations are applied to the intermediate features of RLDM. Additionally, by treating RLDM face restoration as a sibling task, the transferability of the generated adversarial face examples is further improved. Our experimental results validate the effectiveness of the proposed attack method.
Detecting Adversarial Faces Using Only Real Face Self-Perturbations
May 04, 2023



Adversarial attacks aim to disturb the functionality of a target system by adding specific noise to the input samples, bringing potential threats to security and robustness when applied to facial recognition systems. Although existing defense techniques achieve high accuracy in detecting some specific adversarial faces (adv-faces), new attack methods especially GAN-based attacks with completely different noise patterns circumvent them and reach a higher attack success rate. Even worse, existing techniques require attack data before implementing the defense, making it impractical to defend newly emerging attacks that are unseen to defenders. In this paper, we investigate the intrinsic generality of adv-faces and propose to generate pseudo adv-faces by perturbing real faces with three heuristically designed noise patterns. We are the first to train an adv-face detector using only real faces and their self-perturbations, agnostic to victim facial recognition systems, and agnostic to unseen attacks. By regarding adv-faces as out-of-distribution data, we then naturally introduce a novel cascaded system for adv-face detection, which consists of training data self-perturbations, decision boundary regularization, and a max-pooling-based binary classifier focusing on abnormal local color aberrations. Experiments conducted on LFW and CelebA-HQ datasets with eight gradient-based and two GAN-based attacks validate that our method generalizes to a variety of unseen adversarial attacks.
Improving Transferability of Adversarial Examples on Face Recognition with Beneficial Perturbation Feature Augmentation
Oct 28, 2022Face recognition (FR) models can be easily fooled by adversarial examples, which are crafted by adding imperceptible perturbations on benign face images. To improve the transferability of adversarial examples on FR models, we propose a novel attack method called Beneficial Perturbation Feature Augmentation Attack (BPFA), which reduces the overfitting of the adversarial examples to surrogate FR models by the adversarial strategy. Specifically, in the backpropagation step, BPFA records the gradients on pre-selected features and uses the gradient on the input image to craft adversarial perturbation to be added on the input image. In the next forward propagation step, BPFA leverages the recorded gradients to add perturbations(i.e., beneficial perturbations) that can be pitted against the adversarial perturbation added on the input image on their corresponding features. The above two steps are repeated until the last backpropagation step before the maximum number of iterations is reached. The optimization process of the adversarial perturbation added on the input image and the optimization process of the beneficial perturbations added on the features correspond to a minimax two-player game. Extensive experiments demonstrate that BPFA outperforms the state-of-the-art gradient-based adversarial attacks on FR.