 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-as-RNN: A Recurrent Language Model for Memory Updates and Sequence Prediction
Jan 19, 2026Large language models are strong sequence predictors, yet standard inference relies on immutable context histories. After making an error at generation step t, the model lacks an updatable memory mechanism that improves predictions for step t+1. We propose LLM-as-RNN, an inference-only framework that turns a frozen LLM into a recurrent predictor by representing its hidden state as natural-language memory. This state, implemented as a structured system-prompt summary, is updated at each timestep via feedback-driven text rewrites, enabling learning without parameter updates. Under a fixed token budget, LLM-as-RNN corrects errors and retains task-relevant patterns, effectively performing online learning through language. We evaluate the method on three sequential benchmarks in healthcare, meteorology, and finance across Llama, Gemma, and GPT model families. LLM-as-RNN significantly outperforms zero-shot, full-history, and MemPrompt baselines, improving predictive accuracy by 6.5% on average, while producing interpretable, human-readable learning traces absent in standard context accumulation.
Robust CAPTCHA Using Audio Illusions in the Era of Large Language Models: from Evaluation to Advances
Jan 13, 2026CAPTCHAs are widely used by websites to block bots and spam by presenting challenges that are easy for humans but difficult for automated programs to solve. To improve accessibility, audio CAPTCHAs are designed to complement visual ones. However, the robustness of audio CAPTCHAs against advanced Large Audio Language Models (LALMs) and Automatic Speech Recognition (ASR) models remains unclear. In this paper, we introduce AI-CAPTCHA, a unified framework that offers (i) an evaluation framework, ACEval, which includes advanced LALM- and ASR-based solvers, and (ii) a novel audio CAPTCHA approach, IllusionAudio, leveraging audio illusions. Through extensive evaluations of seven widely deployed audio CAPTCHAs, we show that most existing methods can be solved with high success rates by advanced LALMs and ASR models, exposing critical security weaknesses. To address these vulnerabilities, we design a new audio CAPTCHA approach, IllusionAudio, which exploits perceptual illusion cues rooted in human auditory mechanisms. Extensive experiments demonstrate that our method defeats all tested LALM- and ASR-based attacks while achieving a 100% human pass rate, significantly outperforming existing audio CAPTCHA methods.
AMS-IO-Bench and AMS-IO-Agent: Benchmarking and Structured Reasoning for Analog and Mixed-Signal Integrated Circuit Input/Output Design
Dec 25, 2025In this paper, we propose AMS-IO-Agent, a domain-specialized LLM-based agent for structure-aware input/output (I/O) subsystem generation in analog and mixed-signal (AMS) integrated circuits (ICs). The central contribution of this work is a framework that connects natural language design intent with industrial-level AMS IC design deliverables. AMS-IO-Agent integrates two key capabilities: (1) a structured domain knowledge base that captures reusable constraints and design conventions; (2) design intent structuring, which converts ambiguous user intent into verifiable logic steps using JSON and Python as intermediate formats. We further introduce AMS-IO-Bench, a benchmark for wirebond-packaged AMS I/O ring automation. On this benchmark, AMS-IO-Agent achieves over 70\% DRC+LVS pass rate and reduces design turnaround time from hours to minutes, outperforming the baseline LLM. Furthermore, an agent-generated I/O ring was fabricated and validated in a 28 nm CMOS tape-out, demonstrating the practical effectiveness of the approach in real AMS IC design flows. To our knowledge, this is the first reported human-agent collaborative AMS IC design in which an LLM-based agent completes a nontrivial subtask with outputs directly used in silicon.
CollabVLA: Self-Reflective Vision-Language-Action Model Dreaming Together with Human
Sep 18, 2025
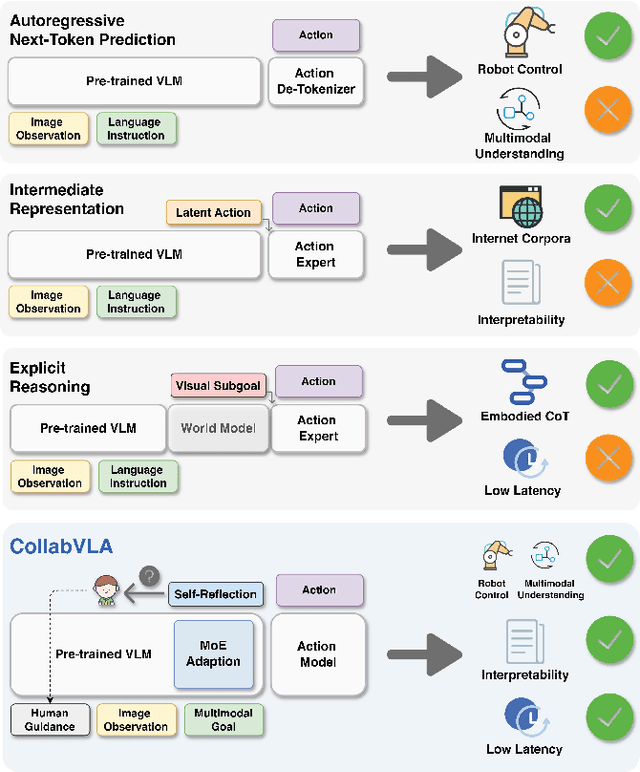

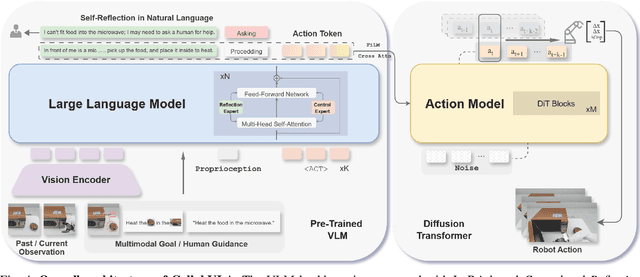
In this work, we present CollabVLA, a self-reflective vision-language-action framework that transforms a standard visuomotor policy into a collaborative assistant. CollabVLA tackles key limitations of prior VLAs, including domain overfitting, non-interpretable reasoning, and the high latency of auxiliary generative models, by integrating VLM-based reflective reasoning with diffusion-based action generation under a mixture-of-experts design. Through a two-stage training recipe of action grounding and reflection tuning, it supports explicit self-reflection and proactively solicits human guidance when confronted with uncertainty or repeated failure. It cuts normalized Time by ~2x and Dream counts by ~4x vs. generative agents, achieving higher success rates, improved interpretability, and balanced low latency compared with existing methods. This work takes a pioneering step toward shifting VLAs from opaque controllers to genuinely assistive agents capable of reasoning, acting, and collaborating with humans.
TED-LaST: Towards Robust Backdoor Defense Against Adaptive Attacks
Jun 12, 2025Deep Neural Networks (DNNs) are vulnerable to backdoor attacks, where attackers implant hidden triggers during training to maliciously control model behavior. Topological Evolution Dynamics (TED) has recently emerged as a powerful tool for detecting backdoor attacks in DNNs. However, TED can be vulnerable to backdoor attacks that adaptively distort topological representation distributions across network layers. To address this limitation, we propose TED-LaST (Topological Evolution Dynamics against Laundry, Slow release, and Target mapping attack strategies), a novel defense strategy that enhances TED's robustness against adaptive attacks. TED-LaST introduces two key innovations: label-supervised dynamics tracking and adaptive layer emphasis. These enhancements enable the identification of stealthy threats that evade traditional TED-based defenses, even in cases of inseparability in topological space and subtle topological perturbations. We review and classify data poisoning tricks in state-of-the-art adaptive attacks and propose enhanced adaptive attack with target mapping, which can dynamically shift malicious tasks and fully leverage the stealthiness that adaptive attacks possess. Our comprehensive experiments on multiple datasets (CIFAR-10, GTSRB, and ImageNet100) and model architectures (ResNet20, ResNet101) show that TED-LaST effectively counteracts sophisticated backdoors like Adap-Blend, Adapt-Patch, and the proposed enhanced adaptive attack. TED-LaST sets a new benchmark for robust backdoor detection, substantially enhancing DNN security against evolving threats.
Evidential Spectrum-Aware Contrastive Learning for OOD Detection in Dynamic Graphs
Jun 09, 2025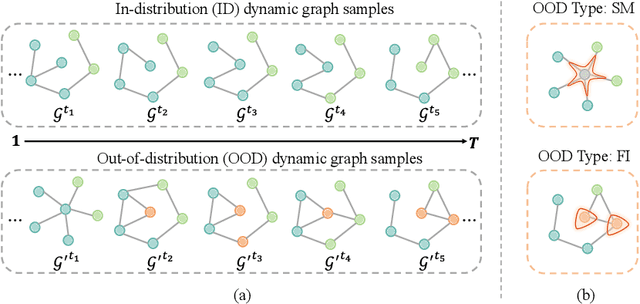
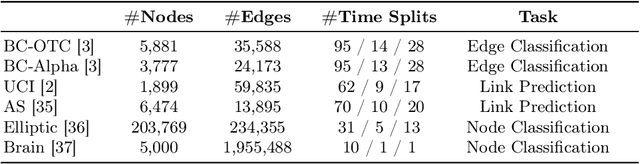
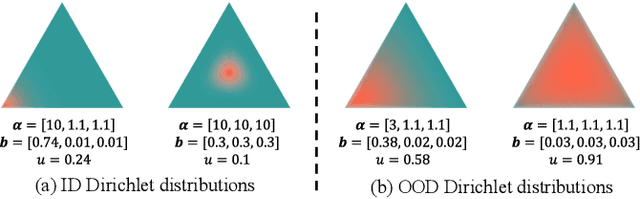
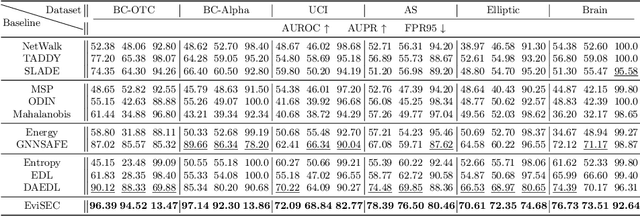
Recently, Out-of-distribution (OOD) detection in dynamic graphs, which aims to identify whether incoming data deviates from the distribution of the in-distribution (ID) training set, has garnered considerable attention in security-sensitive fields. Current OOD detection paradigms primarily focus on static graphs and confront two critical challenges: i) high bias and high variance caused by single-point estimation, which makes the predictions sensitive to randomness in the data; ii) score homogenization resulting from the lack of OOD training data, where the model only learns ID-specific patterns, resulting in overall low OOD scores and a narrow score gap between ID and OOD data. To tackle these issues, we first investigate OOD detection in dynamic graphs through the lens of Evidential Deep Learning (EDL). Specifically, we propose EviSEC, an innovative and effective OOD detector via Evidential Spectrum-awarE Contrastive Learning. We design an evidential neural network to redefine the output as the posterior Dirichlet distribution, explaining the randomness of inputs through the uncertainty of distribution, which is overlooked by single-point estimation. Moreover, spectrum-aware augmentation module generates OOD approximations to identify patterns with high OOD scores, thereby widening the score gap between ID and OOD data and mitigating score homogenization. Extensive experiments on real-world datasets demonstrate that EviSAC effectively detects OOD samples in dynamic graphs.
END$^2$: Robust Dual-Decoder Watermarking Framework Against Non-Differentiable Distortions
Dec 13, 2024DNN-based watermarking methods have rapidly advanced, with the ``Encoder-Noise Layer-Decoder'' (END) framework being the most widely used. To ensure end-to-end training, the noise layer in the framework must be differentiable. However, real-world distortions are often non-differentiable, leading to challenges in end-to-end training. Existing solutions only treat the distortion perturbation as additive noise, which does not fully integrate the effect of distortion in training. To better incorporate non-differentiable distortions into training, we propose a novel dual-decoder architecture (END$^2$). Unlike conventional END architecture, our method employs two structurally identical decoders: the Teacher Decoder, processing pure watermarked images, and the Student Decoder, handling distortion-perturbed images. The gradient is backpropagated only through the Teacher Decoder branch to optimize the encoder thus bypassing the problem of non-differentiability. To ensure resistance to arbitrary distortions, we enforce alignment of the two decoders' feature representations by maximizing the cosine similarity between their intermediate vectors on a hypersphere. Extensive experiments demonstrate that our scheme outperforms state-of-the-art algorithms under various non-differentiable distortions. Moreover, even without the differentiability constraint, our method surpasses baselines with a differentiable noise layer. Our approach is effective and easily implementable across all END architectures, enhancing practicality and generalizability.
From Principles to Practice: A Deep Dive into AI Ethics and Regulations
Dec 06, 2024
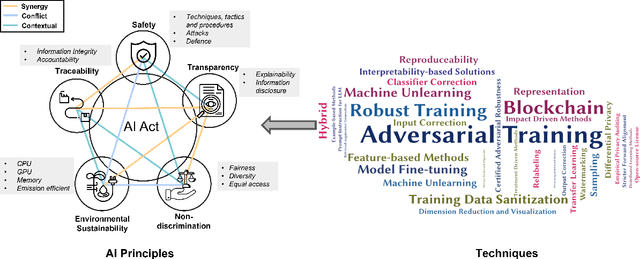

In the rapidly evolving domain of Artificial Intelligence (AI), the complex interaction between innovation and regulation has become an emerging focus of our society. Despite tremendous advancements in AI's capabilities to excel in specific tasks and contribute to diverse sectors, establishing a high degree of trust in AI-generated outputs and decisions necessitates meticulous caution and continuous oversight. A broad spectrum of stakeholders, including governmental bodies, private sector corporations, academic institutions, and individuals, have launched significant initiatives. These efforts include developing ethical guidelines for AI and engaging in vibrant discussions on AI ethics, both among AI practitioners and within the broader society. This article thoroughly analyzes the ground-breaking AI regulatory framework proposed by the European Union. It delves into the fundamental ethical principles of safety, transparency, non-discrimination, traceability, and environmental sustainability for AI developments and deployments. Considering the technical efforts and strategies undertaken by academics and industry to uphold these principles, we explore the synergies and conflicts among the five ethical principles. Through this lens, work presents a forward-looking perspective on the future of AI regulations, advocating for a harmonized approach that safeguards societal values while encouraging technological advancement.
AssistantX: An LLM-Powered Proactive Assistant in Collaborative Human-Populated Environment
Sep 26, 2024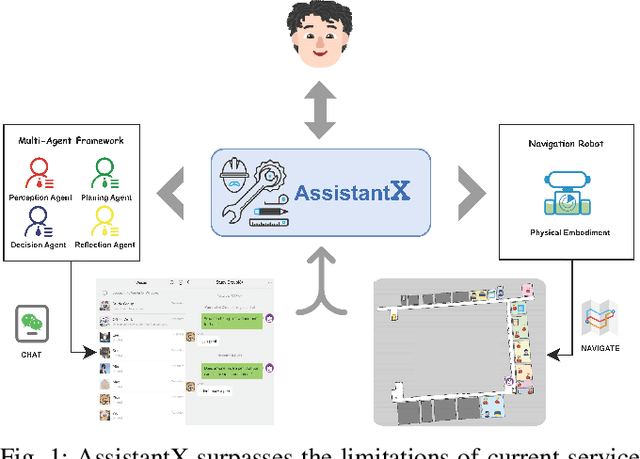
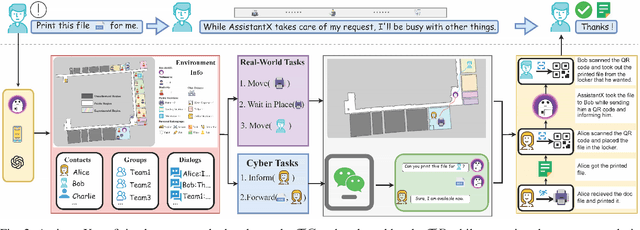
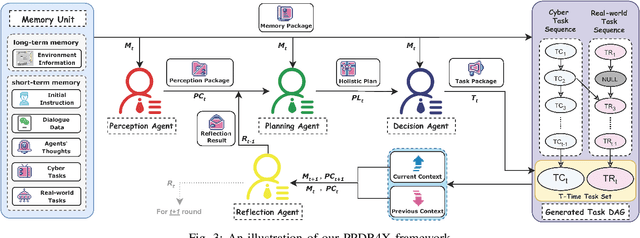
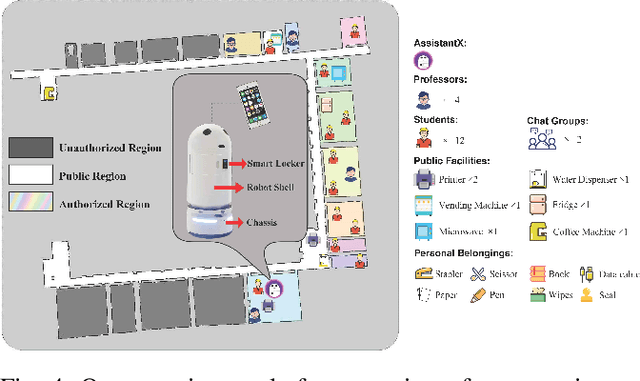
The increasing demand for intelligent assistants in human-populated environments has motivated significant research in autonomous robotic systems. Traditional service robots and virtual assistants, however, struggle with real-world task execution due to their limited capacity for dynamic reasoning and interaction, particularly when human collaboration is required. Recent developments in Large Language Models have opened new avenues for improving these systems, enabling more sophisticated reasoning and natural interaction capabilities. In this paper, we introduce AssistantX, an LLM-powered proactive assistant designed to operate autonomously in a physical office environment. Unlike conventional service robots, AssistantX leverages a novel multi-agent architecture, PPDR4X, which provides advanced inference capabilities and comprehensive collaboration awareness. By effectively bridging the gap between virtual operations and physical interactions, AssistantX demonstrates robust performance in managing complex real-world scenarios. Our evaluation highlights the architecture's effectiveness, showing that AssistantX can respond to clear instructions, actively retrieve supplementary information from memory, and proactively seek collaboration from team members to ensure successful task completion. More details and videos can be found at https://assistantx-agent.github.io/AssistantX/.
Picking watermarks from noise (PWFN): an improved robust watermarking model against intensive distortions
May 08, 2024
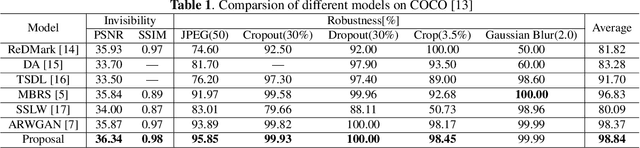
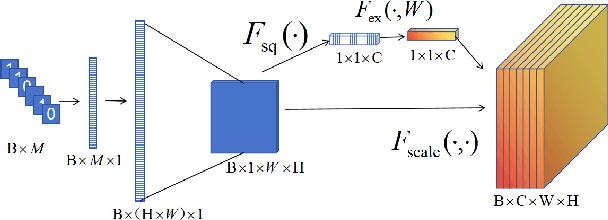

Digital watermarking is the process of embedding secret information by altering images in a way that is undetectable to the human eye. To increase the robustness of the model, many deep learning-based watermarking methods use the encoder-decoder architecture by adding different noises to the noise layer. The decoder then extracts the watermarked information from the distorted image. However, this method can only resist weak noise attacks. To improve the robustness of the algorithm against stronger noise, this paper proposes to introduce a denoise module between the noise layer and the decoder. The module is aimed at reducing noise and recovering some of the information lost during an attack. Additionally, the paper introduces the SE module to fuse the watermarking information pixel-wise and channel dimensions-wise, improving the encoder's efficiency. Experimental results show that our proposed method is comparable to existing models and outperforms state-of-the-art under different noise intensities. In addition, ablation experiments show the superiority of our proposed module.