 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEND$^2$: Robust Dual-Decoder Watermarking Framework Against Non-Differentiable Distortions
Dec 13, 2024



DNN-based watermarking methods have rapidly advanced, with the ``Encoder-Noise Layer-Decoder'' (END) framework being the most widely used. To ensure end-to-end training, the noise layer in the framework must be differentiable. However, real-world distortions are often non-differentiable, leading to challenges in end-to-end training. Existing solutions only treat the distortion perturbation as additive noise, which does not fully integrate the effect of distortion in training. To better incorporate non-differentiable distortions into training, we propose a novel dual-decoder architecture (END$^2$). Unlike conventional END architecture, our method employs two structurally identical decoders: the Teacher Decoder, processing pure watermarked images, and the Student Decoder, handling distortion-perturbed images. The gradient is backpropagated only through the Teacher Decoder branch to optimize the encoder thus bypassing the problem of non-differentiability. To ensure resistance to arbitrary distortions, we enforce alignment of the two decoders' feature representations by maximizing the cosine similarity between their intermediate vectors on a hypersphere. Extensive experiments demonstrate that our scheme outperforms state-of-the-art algorithms under various non-differentiable distortions. Moreover, even without the differentiability constraint, our method surpasses baselines with a differentiable noise layer. Our approach is effective and easily implementable across all END architectures, enhancing practicality and generalizability.
Picking watermarks from noise (PWFN): an improved robust watermarking model against intensive distortions
May 08, 2024
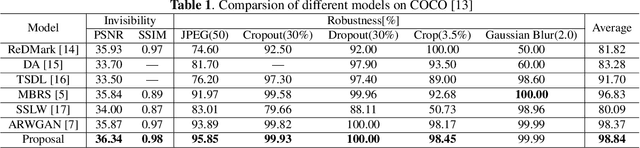
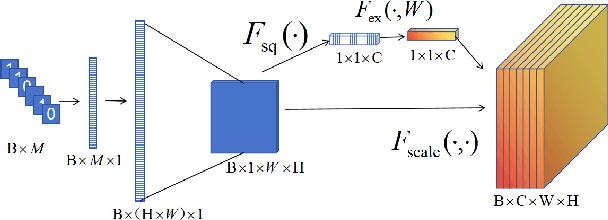

Digital watermarking is the process of embedding secret information by altering images in a way that is undetectable to the human eye. To increase the robustness of the model, many deep learning-based watermarking methods use the encoder-decoder architecture by adding different noises to the noise layer. The decoder then extracts the watermarked information from the distorted image. However, this method can only resist weak noise attacks. To improve the robustness of the algorithm against stronger noise, this paper proposes to introduce a denoise module between the noise layer and the decoder. The module is aimed at reducing noise and recovering some of the information lost during an attack. Additionally, the paper introduces the SE module to fuse the watermarking information pixel-wise and channel dimensions-wise, improving the encoder's efficiency. Experimental results show that our proposed method is comparable to existing models and outperforms state-of-the-art under different noise intensities. In addition, ablation experiments show the superiority of our proposed module.
DBDH: A Dual-Branch Dual-Head Neural Network for Invisible Embedded Regions Localization
May 06, 2024



Embedding invisible hyperlinks or hidden codes in images to replace QR codes has become a hot topic recently. This technology requires first localizing the embedded region in the captured photos before decoding. Existing methods that train models to find the invisible embedded region struggle to obtain accurate localization results, leading to degraded decoding accuracy. This limitation is primarily because the CNN network is sensitive to low-frequency signals, while the embedded signal is typically in the high-frequency form. Based on this, this paper proposes a Dual-Branch Dual-Head (DBDH) neural network tailored for the precise localization of invisible embedded regions. Specifically, DBDH uses a low-level texture branch containing 62 high-pass filters to capture the high-frequency signals induced by embedding. A high-level context branch is used to extract discriminative features between the embedded and normal regions. DBDH employs a detection head to directly detect the four vertices of the embedding region. In addition, we introduce an extra segmentation head to segment the mask of the embedding region during training. The segmentation head provides pixel-level supervision for model learning, facilitating better learning of the embedded signals. Based on two state-of-the-art invisible offline-to-online messaging methods, we construct two datasets and augmentation strategies for training and testing localization models. Extensive experiments demonstrate the superior performance of the proposed DBDH over existing methods.
SSyncOA: Self-synchronizing Object-aligned Watermarking to Resist Cropping-paste Attacks
May 06, 2024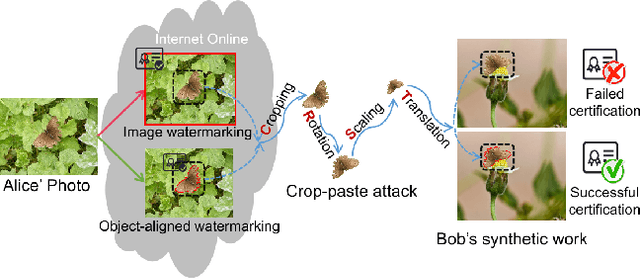

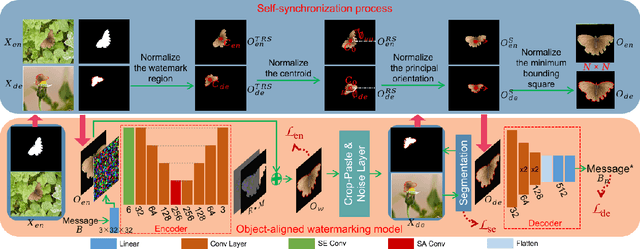

Modern image processing tools have made it easy for attackers to crop the region or object of interest in images and paste it into other images. The challenge this cropping-paste attack poses to the watermarking technology is that it breaks the synchronization of the image watermark, introducing multiple superimposed desynchronization distortions, such as rotation, scaling, and translation. However, current watermarking methods can only resist a single type of desynchronization and cannot be applied to protect the object's copyright under the cropping-paste attack. With the finding that the key to resisting the cropping-paste attack lies in robust features of the object to protect, this paper proposes a self-synchronizing object-aligned watermarking method, called SSyncOA. Specifically, we first constrain the watermarked region to be aligned with the protected object, and then synchronize the watermark's translation, rotation, and scaling distortions by normalizing the object invariant features, i.e., its centroid, principal orientation, and minimum bounding square, respectively. To make the watermark embedded in the protected object, we introduce the object-aligned watermarking model, which incorporates the real cropping-paste attack into the encoder-noise layer-decoder pipeline and is optimized end-to-end. Besides, we illustrate the effect of different desynchronization distortions on the watermark training, which confirms the necessity of the self-synchronization process. Extensive experiments demonstrate the superiority of our method over other SOTAs.