 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsisFormer: Compute-Efficient Transformer for Wireless Foundation Models Based on Channel Consistency
Jun 18, 2026Wireless foundation models (WFMs) have recently emerged as a promising paradigm for AI-native 6G networks, enabling universal channel representations adaptable to diverse communication and sensing tasks. Existing WFMs are predominantly built upon the Transformer architecture, which delivers superior performance but incurs computational complexity proportional to the square of the input sequence length, posing a significant barrier to their deployment under stringent inference latency constraints. To address this issue, in this paper, we propose ConsisFormer, a compute-efficient Transformer design based on short-term consistency of wireless channels, as a WFM backbone. By utilizing the observation that adjacent time or frequency instances share similar clusters of scatterers and thus exhibit similar channel characteristics, we develop an adaptive token aggregation (ATA) module to dynamically merge neighboring channel state information (CSI) tokens, thereby reducing the length of the token sequence involved in self-attention calculations to lower the computational cost. Furthermore, we propose a feature sequence interpolation (FSI) method to recover the full CSI representation based on the sparse feature sequence outputted from the Transformer blocks, thus keeping the performance unaffected while ensuring low complexity. Moreover, we propose an aggregated auto-encoder (AAE) pre-training paradigm for WFMs, enabling robust channel representation learning from sparsified CSI tokens via compression and recovery. Simulation results show that the proposed design reduces the computational complexity of WFM by over $83\%$ with negligible performance loss on various tasks including channel prediction, LoS/NLOS classification, beam prediction, and localization.
A Unified Adaptive Feature Composition Framework for Multi-Task Generalization in Wireless Foundation Models
Jun 09, 2026Though wireless foundation models (WFMs) have shown strong potential in learning universal channel representations, their adaptation to various downstream tasks remains constrained by existing paradigms. Fine-tuning strategies introduces substantial computational and storage overhead, while frozen feature extraction leads to sub-optimal performance across diverse downstream tasks. To address this issue, we propose a unified adaptive feature composition framework for multitask generalization in WFMs, where the key component is the Routing Adapter for Feature Composition (RAFC). Instead of extracting only the final-layer output, this router treats the hidden states from different Transformer depths as a reusable pool of multi-level hidden features, and employs a lightweight task-driven feature composition network to generate layer-wise aggregation weights, then adaptively combine hierarchical representations through weighted summation. This design enables each downstream task to access suitable mixture of low-, mid-, and high-level wireless features without modifying the pretrained backbone. Extensive experiments on four representative wireless tasks demonstrate that RAFC consistently outperforms conventional adaptation baselines while introducing fewer than 50K additional parameters. Moreover, the learned routing weights provide interpretable evidence of task-specific layer preferences, making the proposed framework a low-complexity, scalable, and explainable interface for adapting WFMs to diverse downstream scenarios.
SpikeWFM: Spiking-Aided Wireless Foundation Model for Robust Channel Prediction
May 28, 2026This paper proposes SpikeWFM, a novel hybrid architecture that integrates spiking neural networks (SNNs) with conventional artificial neural network (ANN)-based transformers for wireless foundation models (WFMs). Inspired by the noise-robust and energy-efficient information processing in the human brain, SpikeWFM aims to enhance the resilience of WFMs against noise and interference while maintaining strong generalization capabilities across diverse wireless scenarios. Drawing from the success of large language models, WFMs leverage self-supervised pre-training on large-scale datasets spanning various wireless environments to learn a unified embedding that supports a wide range of downstream tasks, including channel prediction, channel estimation, beam predition, positioning and etc. Such models typically outperform task-specific designs and exhibit superior adaptability to unseen conditions. However, existing WFMs remain vulnerable to realistic noise and interference in practical wireless systems. To address this limitation, we incorporate spiking neurons into the transformer-based WFM architecture. We provide a brief theoretical analysis demonstrating how the SNN-ANN hybrid effectively mitigates noise and interference through temporal sparsity and event-driven processing. Experimental results show that SpikeWFM consistently outperforms conventional ANN-based WFMs in both pre-training convergence and channel prediction accuracy. Additional results on communication and sensing tasks will be presented in the full journal version of this work.
The MiniMax-M2 Series: Mini Activations Unleashing Max Real-World Intelligence
May 26, 2026We introduce the MiniMax-M2 series, a family of Mixture-of-Experts language models built around the principle that mini activations can unleash maximum real-world intelligence. The flagship M2 contains 229.9B total parameters with only 9.8B activated per token. Designed end-to-end for agentic deployment, the M2 series rests on three components: (i) agent-driven data pipelines producing large-scale, verifiable trajectories across agentic coding and agentic cowork, each grounded in an executable workspace and an artifact-aligned reward; (ii) Forge, a scalable agent-native RL system that adapts to long-horizon agent trajectories, paired with windowed-FIFO scheduling, prefix-tree merging, inference optimization, and a clean training-inference-agent decoupling that supports both white-box and black-box agents; (iii) the latest M2.7 checkpoint takes an early step toward self-evolution -- autonomously debugging training runs and modifying its own scaffold. Across M2 through M2.7, this combination translates a mini-activation footprint into frontier-tier performance on agentic coding, deep search, office-task, and reasoning benchmarks.
SpecFed: Accelerating Federated LLM Inference with Speculative Decoding and Compressed Transmission
Apr 28, 2026Federated inference enhances LLM performance in edge computing through weighted averaging of distributed model predictions. However, autoregressive LLM inference requires frequent full-model forward passes across workers, severely limiting decoding throughput. Distributed deployment further aggravates this due to a communication bottleneck: each worker must transmit full token probability distributions per draft token, dominating end-to-end latency. To address these challenges, we introduce speculative decoding to enable parallel LLM processing and propose a top-K compressed transmission scheme with two server-side reconstruction strategies. We theoretically analyze the robustness of our method in terms of local reconstruction error, aggregation bias, and acceptance-rate bias, and derive corresponding bounds. Experiments demonstrate that our scheme achieves high generation fidelity while significantly reducing communication overhead.
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Jun 16, 2025



We introduce MiniMax-M1, the world's first open-weight, large-scale hybrid-attention reasoning model. MiniMax-M1 is powered by a hybrid Mixture-of-Experts (MoE) architecture combined with a lightning attention mechanism. The model is developed based on our previous MiniMax-Text-01 model, which contains a total of 456 billion parameters with 45.9 billion parameters activated per token. The M1 model natively supports a context length of 1 million tokens, 8x the context size of DeepSeek R1. Furthermore, the lightning attention mechanism in MiniMax-M1 enables efficient scaling of test-time compute. These properties make M1 particularly suitable for complex tasks that require processing long inputs and thinking extensively. MiniMax-M1 is trained using large-scale reinforcement learning (RL) on diverse problems including sandbox-based, real-world software engineering environments. In addition to M1's inherent efficiency advantage for RL training, we propose CISPO, a novel RL algorithm to further enhance RL efficiency. CISPO clips importance sampling weights rather than token updates, outperforming other competitive RL variants. Combining hybrid-attention and CISPO enables MiniMax-M1's full RL training on 512 H800 GPUs to complete in only three weeks, with a rental cost of just $534,700. We release two versions of MiniMax-M1 models with 40K and 80K thinking budgets respectively, where the 40K model represents an intermediate phase of the 80K training. Experiments on standard benchmarks show that our models are comparable or superior to strong open-weight models such as the original DeepSeek-R1 and Qwen3-235B, with particular strengths in complex software engineering, tool utilization, and long-context tasks. We publicly release MiniMax-M1 at https://github.com/MiniMax-AI/MiniMax-M1.
WVSC: Wireless Video Semantic Communication with Multi-frame Compensation
Mar 27, 2025Existing wireless video transmission schemes directly conduct video coding in pixel level, while neglecting the inner semantics contained in videos. In this paper, we propose a wireless video semantic communication framework, abbreviated as WVSC, which integrates the idea of semantic communication into wireless video transmission scenarios. WVSC first encodes original video frames as semantic frames and then conducts video coding based on such compact representations, enabling the video coding in semantic level rather than pixel level. Moreover, to further reduce the communication overhead, a reference semantic frame is introduced to substitute motion vectors of each frame in common video coding methods. At the receiver, multi-frame compensation (MFC) is proposed to produce compensated current semantic frame with a multi-frame fusion attention module. With both the reference frame transmission and MFC, the bandwidth efficiency improves with satisfying video transmission performance. Experimental results verify the performance gain of WVSC over other DL-based methods e.g. DVSC about 1 dB and traditional schemes about 2 dB in terms of PSNR.
Learnable Residual-based Latent Denoising in Semantic Communication
Feb 11, 2025A latent denoising semantic communication (SemCom) framework is proposed for robust image transmission over noisy channels. By incorporating a learnable latent denoiser into the receiver, the received signals are preprocessed to effectively remove the channel noise and recover the semantic information, thereby enhancing the quality of the decoded images. Specifically, a latent denoising mapping is established by an iterative residual learning approach to improve the denoising efficiency while ensuring stable performance. Moreover, channel signal-to-noise ratio (SNR) is utilized to estimate and predict the latent similarity score (SS) for conditional denoising, where the number of denoising steps is adapted based on the predicted SS sequence, further reducing the communication latency. Finally, simulations demonstrate that the proposed framework can effectively and efficiently remove the channel noise at various levels and reconstruct visual-appealing images.
WirelessGPT: A Generative Pre-trained Multi-task Learning Framework for Wireless Communication
Feb 08, 2025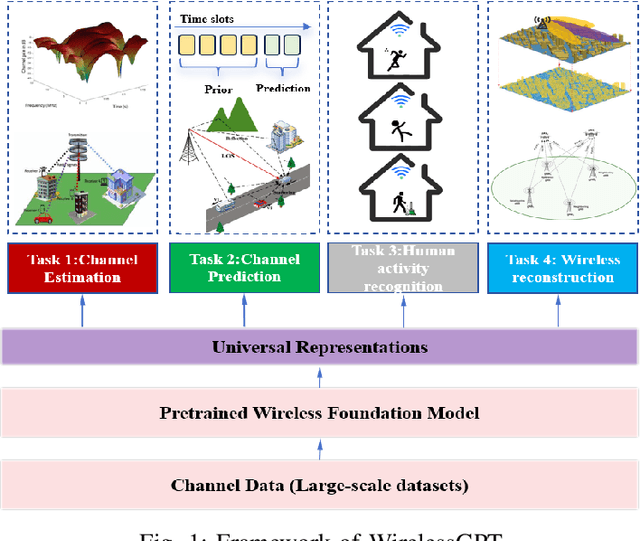
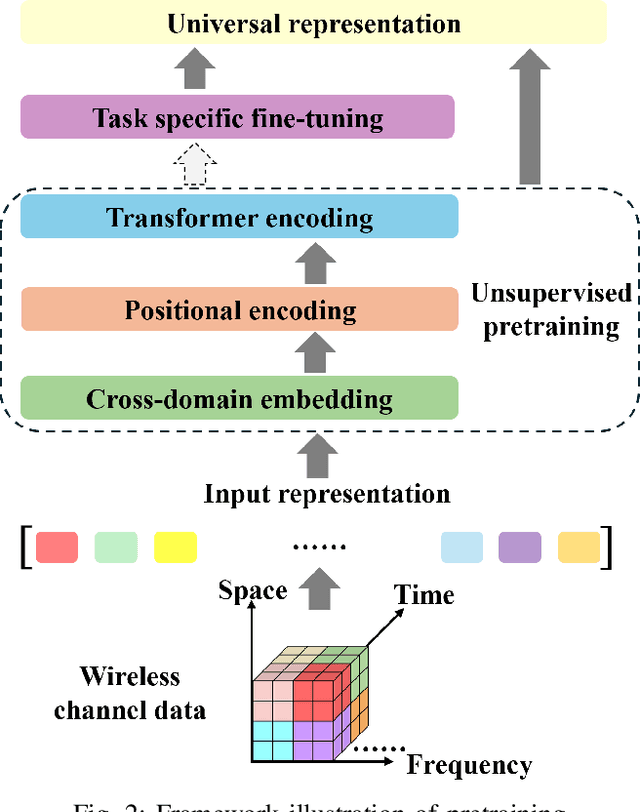
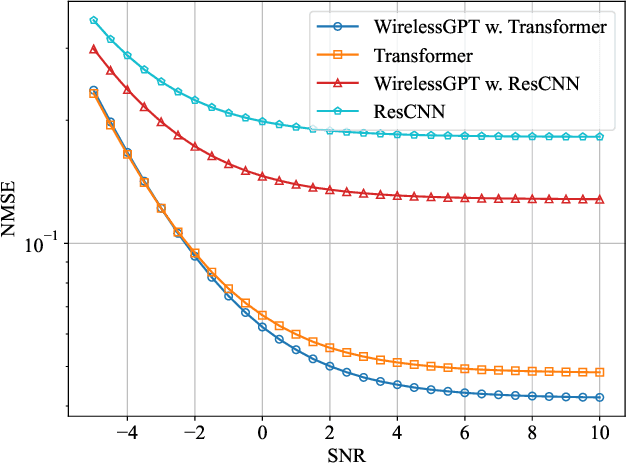
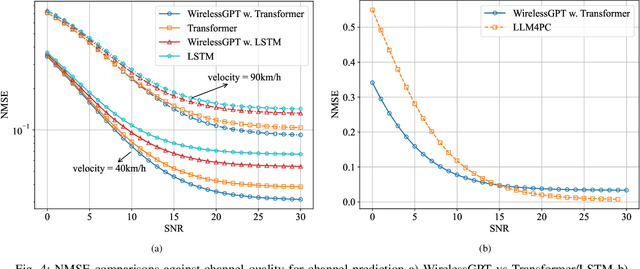
This paper introduces WirelessGPT, a pioneering foundation model specifically designed for multi-task learning in wireless communication and sensing. Specifically, WirelessGPT leverages large-scale wireless channel datasets for unsupervised pretraining and extracting universal channel representations, which captures complex spatiotemporal dependencies. In fact,this task-agnostic design adapts WirelessGPT seamlessly to a wide range of downstream tasks, using a unified representation with minimal fine-tuning. By unifying communication and sensing functionalities, WirelessGPT addresses the limitations of task-specific models, offering a scalable and efficient solution for integrated sensing and communication (ISAC). With an initial parameter size of around 80 million, WirelessGPT demonstrates significant improvements over conventional methods and smaller AI models, reducing reliance on large-scale labeled data. As the first foundation model capable of supporting diverse tasks across different domains, WirelessGPT establishes a new benchmark, paving the way for future advancements in multi-task wireless systems.
Reducing Fine-Tuning Memory Overhead by Approximate and Memory-Sharing Backpropagation
Jun 24, 2024



Fine-tuning pretrained large models to downstream tasks is an important problem, which however suffers from huge memory overhead due to large-scale parameters. This work strives to reduce memory overhead in fine-tuning from perspectives of activation function and layer normalization. To this end, we propose the Approximate Backpropagation (Approx-BP) theory, which provides the theoretical feasibility of decoupling the forward and backward passes. We apply our Approx-BP theory to backpropagation training and derive memory-efficient alternatives of GELU and SiLU activation functions, which use derivative functions of ReLUs in the backward pass while keeping their forward pass unchanged. In addition, we introduce a Memory-Sharing Backpropagation strategy, which enables the activation memory to be shared by two adjacent layers, thereby removing activation memory usage redundancy. Our method neither induces extra computation nor reduces training efficiency. We conduct extensive experiments with pretrained vision and language models, and the results demonstrate that our proposal can reduce up to $\sim$$30\%$ of the peak memory usage. Our code is released at https://github.com/yyyyychen/LowMemoryBP.