 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsisFormer: Compute-Efficient Transformer for Wireless Foundation Models Based on Channel Consistency
Jun 18, 2026Wireless foundation models (WFMs) have recently emerged as a promising paradigm for AI-native 6G networks, enabling universal channel representations adaptable to diverse communication and sensing tasks. Existing WFMs are predominantly built upon the Transformer architecture, which delivers superior performance but incurs computational complexity proportional to the square of the input sequence length, posing a significant barrier to their deployment under stringent inference latency constraints. To address this issue, in this paper, we propose ConsisFormer, a compute-efficient Transformer design based on short-term consistency of wireless channels, as a WFM backbone. By utilizing the observation that adjacent time or frequency instances share similar clusters of scatterers and thus exhibit similar channel characteristics, we develop an adaptive token aggregation (ATA) module to dynamically merge neighboring channel state information (CSI) tokens, thereby reducing the length of the token sequence involved in self-attention calculations to lower the computational cost. Furthermore, we propose a feature sequence interpolation (FSI) method to recover the full CSI representation based on the sparse feature sequence outputted from the Transformer blocks, thus keeping the performance unaffected while ensuring low complexity. Moreover, we propose an aggregated auto-encoder (AAE) pre-training paradigm for WFMs, enabling robust channel representation learning from sparsified CSI tokens via compression and recovery. Simulation results show that the proposed design reduces the computational complexity of WFM by over $83\%$ with negligible performance loss on various tasks including channel prediction, LoS/NLOS classification, beam prediction, and localization.
ChatPlanner: A Large Language Model Framework for Personalized Public Transit Routing
Jun 13, 2026Personalized public transit routing in public transit systems remains challenging due to the difficulty of capturing and integrating diverse user preferences into routing algorithms. This paper presents ChatPlanner, a novel framework that leverages Large Language Models (LLMs) to enable preference aware public transit routing. Our approach employs fine-tuned LLMs with Retrieval-Augmented Generation (RAG) to extract routing parameters and interpret nuanced user preferences from natural language queries, subsequently integrating these preferences into the objective function of a public transit routing algorithm. This study designs preference aware datasets incorporating eight personas and five contexts to establish scoring standards for both fine-tuning and RAG. This work conducted three experiments to validate the solutions' feasibility, extraction of routing information and preferences, and solution set quality and completeness. Results demonstrate that ChatPlanner generates feasible solutions reliably. Fine-tuning enforces the required output structure and learns general preference patterns, while RAG provides query-specific context to resolve imprecise or conversational expressions and calibrate continuous scores. The combination of both achieves the highest accuracy in routing information extraction and user preference interpretation. Results based on selected case studies show that by capturing user preferences, ChatPlanner identifies valuable solutions across different dimensions that existing route planners overlook, generating more valuable route alternatives. This research establishes a new paradigm for integrating natural language understanding into transportation optimization.
A Unified Adaptive Feature Composition Framework for Multi-Task Generalization in Wireless Foundation Models
Jun 09, 2026Though wireless foundation models (WFMs) have shown strong potential in learning universal channel representations, their adaptation to various downstream tasks remains constrained by existing paradigms. Fine-tuning strategies introduces substantial computational and storage overhead, while frozen feature extraction leads to sub-optimal performance across diverse downstream tasks. To address this issue, we propose a unified adaptive feature composition framework for multitask generalization in WFMs, where the key component is the Routing Adapter for Feature Composition (RAFC). Instead of extracting only the final-layer output, this router treats the hidden states from different Transformer depths as a reusable pool of multi-level hidden features, and employs a lightweight task-driven feature composition network to generate layer-wise aggregation weights, then adaptively combine hierarchical representations through weighted summation. This design enables each downstream task to access suitable mixture of low-, mid-, and high-level wireless features without modifying the pretrained backbone. Extensive experiments on four representative wireless tasks demonstrate that RAFC consistently outperforms conventional adaptation baselines while introducing fewer than 50K additional parameters. Moreover, the learned routing weights provide interpretable evidence of task-specific layer preferences, making the proposed framework a low-complexity, scalable, and explainable interface for adapting WFMs to diverse downstream scenarios.
SpikeWFM: Spiking-Aided Wireless Foundation Model for Robust Channel Prediction
May 28, 2026This paper proposes SpikeWFM, a novel hybrid architecture that integrates spiking neural networks (SNNs) with conventional artificial neural network (ANN)-based transformers for wireless foundation models (WFMs). Inspired by the noise-robust and energy-efficient information processing in the human brain, SpikeWFM aims to enhance the resilience of WFMs against noise and interference while maintaining strong generalization capabilities across diverse wireless scenarios. Drawing from the success of large language models, WFMs leverage self-supervised pre-training on large-scale datasets spanning various wireless environments to learn a unified embedding that supports a wide range of downstream tasks, including channel prediction, channel estimation, beam predition, positioning and etc. Such models typically outperform task-specific designs and exhibit superior adaptability to unseen conditions. However, existing WFMs remain vulnerable to realistic noise and interference in practical wireless systems. To address this limitation, we incorporate spiking neurons into the transformer-based WFM architecture. We provide a brief theoretical analysis demonstrating how the SNN-ANN hybrid effectively mitigates noise and interference through temporal sparsity and event-driven processing. Experimental results show that SpikeWFM consistently outperforms conventional ANN-based WFMs in both pre-training convergence and channel prediction accuracy. Additional results on communication and sensing tasks will be presented in the full journal version of this work.
SpecFed: Accelerating Federated LLM Inference with Speculative Decoding and Compressed Transmission
Apr 28, 2026Federated inference enhances LLM performance in edge computing through weighted averaging of distributed model predictions. However, autoregressive LLM inference requires frequent full-model forward passes across workers, severely limiting decoding throughput. Distributed deployment further aggravates this due to a communication bottleneck: each worker must transmit full token probability distributions per draft token, dominating end-to-end latency. To address these challenges, we introduce speculative decoding to enable parallel LLM processing and propose a top-K compressed transmission scheme with two server-side reconstruction strategies. We theoretically analyze the robustness of our method in terms of local reconstruction error, aggregation bias, and acceptance-rate bias, and derive corresponding bounds. Experiments demonstrate that our scheme achieves high generation fidelity while significantly reducing communication overhead.
From Specialist to Large Models: A Paradigm Evolution Towards Semantic-Aware MIMO
Feb 25, 2026The sixth generation (6G) network is expected to deploy larger multiple-input multiple-output (MIMO) arrays to support massive connectivity, which will increase overhead and latency at the physical layer. Meanwhile, emerging 6G demands such as immersive communications and environmental sensing pose challenges to traditional signal processing. To address these issues, we propose the ``semantic-aware MIMO'' paradigm, which leverages specialist models and large models to perceive, utilize, and fuse the inherent semantics of channels and sources for improved performance. Moreover, for representative MIMO physical-layer tasks, e.g., random access activity detection, channel feedback, and precoding, we design specialist models that exploit channel and source semantics for better performance. Additionally, in view of the more diversified functions of 6G MIMO, we further explore large models as a scalable solution for multi-task semantic-aware MIMO and review recent advances along with their advantages and limitations. Finally, we discuss the challenges, insights, and prospects of the evolution of specialist models and large models empowered semantic-aware MIMO paradigms.
Wireless Channel Foundation Model with Embedded Noise-Plus-Interference Suppression Structure
Sep 19, 2025Wireless channel foundation model (WCFM) is a task-agnostic AI model that is pretrained on large-scale wireless channel datasets to learn a universal channel feature representation that can be used for a wide range of downstream tasks related to communications and sensing. While existing works on WCFM have demonstrated its great potentials in various tasks including beam prediction, channel prediction, localization, etc, the models are all trained using perfect (i.e., error-free and complete) channel information state (CSI) data which are generated with simulation tools. However, in practical systems where the WCFM is deployed, perfect CSI is not available. Instead, channel estimation needs to be first performed based on pilot signals over a subset of the resource elements (REs) to acquire a noisy version of the CSI (termed as degraded CSI), which significantly differs from the perfect CSI in some real-world environments with severe noise and interference. As a result, the feature representation generated by the WCFM is unable to reflect the characteristics of the true channel, yielding performance degradation in downstream tasks. To address this issue, in this paper we propose an enhanced wireless channel foundation model architecture with noise-plus-interference (NPI) suppression capability. In our approach, coarse estimates of the CSIs are first obtained. With these information, two projection matrices are computed to extract the NPI terms in the received signals, which are further processed by a NPI estimation and subtraction module. Finally, the resultant signal is passed through a CSI completion network to get a clean version of the CSI, which is used for feature extraction. Simulation results demonstrated that compared to the state-of-the-art solutions, WCFM with NPI suppression structure achieves improved performance on channel prediction task.
Communication-Efficient Collaborative LLM Inference via Distributed Speculative Decoding
Sep 04, 2025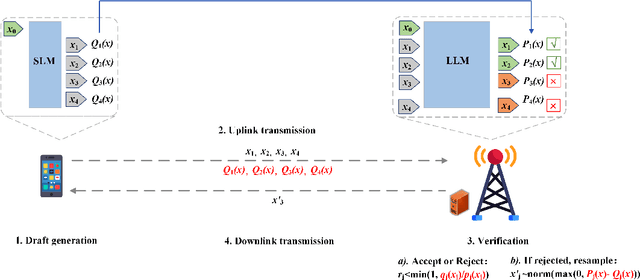
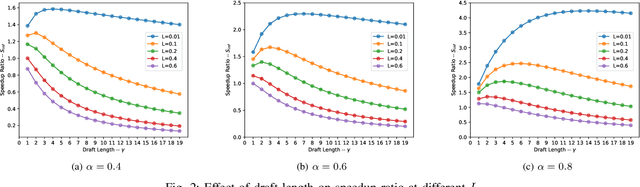
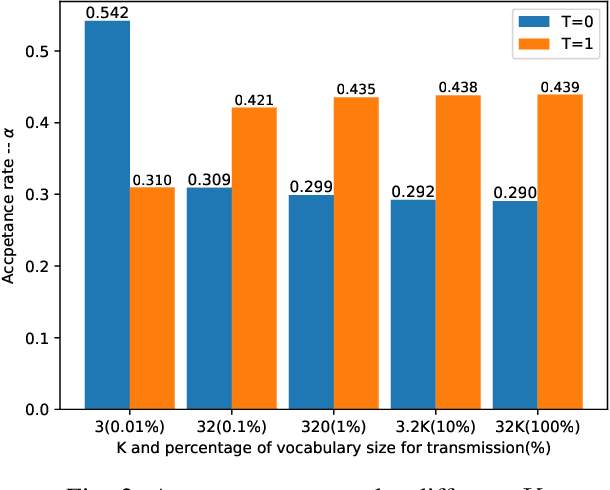
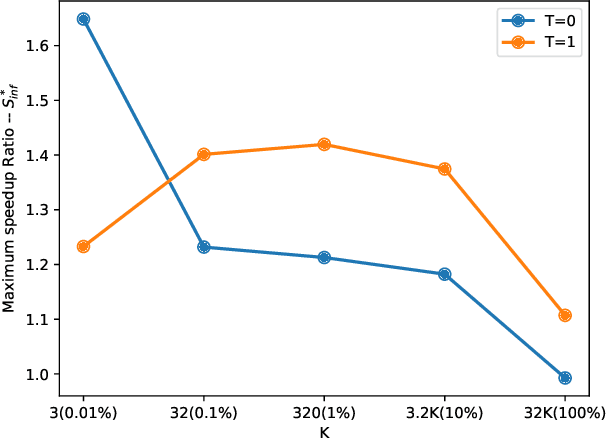
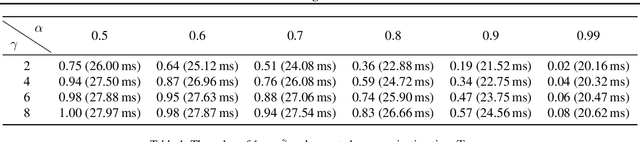
Speculative decoding is an emerging technique that accelerates large language model (LLM) inference by allowing a smaller draft model to predict multiple tokens in advance, which are then verified or corrected by a larger target model. In AI-native radio access networks (AI-RAN), this paradigm is well-suited for collaborative inference between resource-constrained end devices and more capable edge servers or base stations (BSs). However, existing distributed speculative decoding requires transmitting the full vocabulary probability distribution from the draft model on the device to the target model at the BS, which leads to prohibitive uplink communication overhead. To address this issue, we propose a ``Top-K Sparse Logits Transmission (TK-SLT)`` scheme, where the draft model transmits only the top-K token raw probabilities and the corresponding token indices instead of the entire distribution. This approach significantly reduces bandwidth consumption while maintaining inference performance. We further derive an analytical expression for the optimal draft length that maximizes inference throughput, and provide a theoretical analysis of the achievable speedup ratio under TK-SLT. Experimental results validate both the efficiency and effectiveness of the proposed method.
DSSD: Efficient Edge-Device Deployment and Collaborative Inference via Distributed Split Speculative Decoding
Jul 16, 2025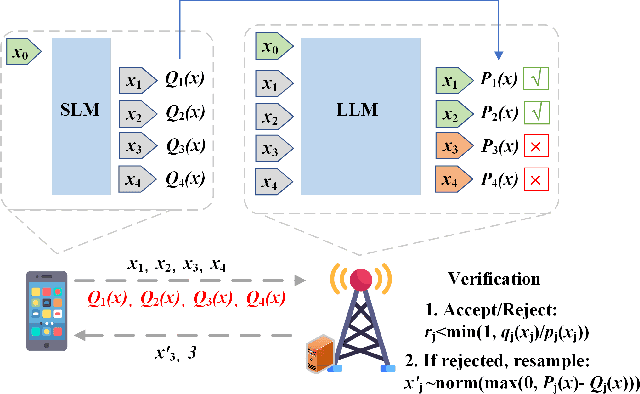
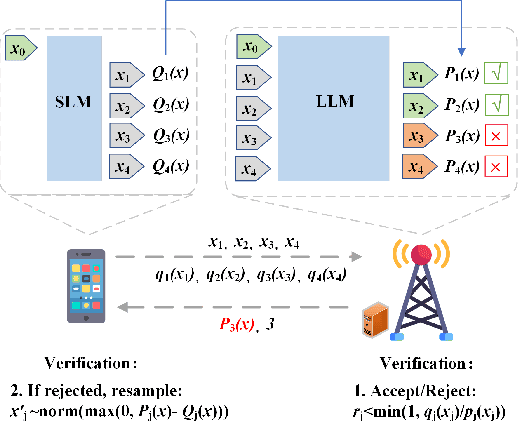
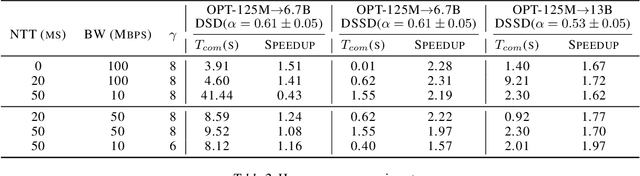
Large language models (LLMs) have transformed natural language processing but face critical deployment challenges in device-edge systems due to resource limitations and communication overhead. To address these issues, collaborative frameworks have emerged that combine small language models (SLMs) on devices with LLMs at the edge, using speculative decoding (SD) to improve efficiency. However, existing solutions often trade inference accuracy for latency or suffer from high uplink transmission costs when verifying candidate tokens. In this paper, we propose Distributed Split Speculative Decoding (DSSD), a novel architecture that not only preserves the SLM-LLM split but also partitions the verification phase between the device and edge. In this way, DSSD replaces the uplink transmission of multiple vocabulary distributions with a single downlink transmission, significantly reducing communication latency while maintaining inference quality. Experiments show that our solution outperforms current methods, and codes are at: https://github.com/JasonNing96/DSSD-Efficient-Edge-Computing
Wireless Large AI Model: Shaping the AI-Native Future of 6G and Beyond
Apr 20, 2025The emergence of sixth-generation and beyond communication systems is expected to fundamentally transform digital experiences through introducing unparalleled levels of intelligence, efficiency, and connectivity. A promising technology poised to enable this revolutionary vision is the wireless large AI model (WLAM), characterized by its exceptional capabilities in data processing, inference, and decision-making. In light of these remarkable capabilities, this paper provides a comprehensive survey of WLAM, elucidating its fundamental principles, diverse applications, critical challenges, and future research opportunities. We begin by introducing the background of WLAM and analyzing the key synergies with wireless networks, emphasizing the mutual benefits. Subsequently, we explore the foundational characteristics of WLAM, delving into their unique relevance in wireless environments. Then, the role of WLAM in optimizing wireless communication systems across various use cases and the reciprocal benefits are systematically investigated. Furthermore, we discuss the integration of WLAM with emerging technologies, highlighting their potential to enable transformative capabilities and breakthroughs in wireless communication. Finally, we thoroughly examine the high-level challenges hindering the practical implementation of WLAM and discuss pivotal future research directions.