 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking the Potential of Linear Networks for Irregular Multivariate Time Series Forecasting
May 01, 2025Time series forecasting holds significant importance across various industries, including finance, transportation, energy, healthcare, and climate. Despite the widespread use of linear networks due to their low computational cost and effectiveness in modeling temporal dependencies, most existing research has concentrated on regularly sampled and fully observed multivariate time series. However, in practice, we frequently encounter irregular multivariate time series characterized by variable sampling intervals and missing values. The inherent intra-series inconsistency and inter-series asynchrony in such data hinder effective modeling and forecasting with traditional linear networks relying on static weights. To tackle these challenges, this paper introduces a novel model named AiT. AiT utilizes an adaptive linear network capable of dynamically adjusting weights according to observation time points to address intra-series inconsistency, thereby enhancing the accuracy of temporal dependencies modeling. Furthermore, by incorporating the Transformer module on variable semantics embeddings, AiT efficiently captures variable correlations, avoiding the challenge of inter-series asynchrony. Comprehensive experiments across four benchmark datasets demonstrate the superiority of AiT, improving prediction accuracy by 11% and decreasing runtime by 52% compared to existing state-of-the-art methods.
MergeQuant: Accurate 4-bit Static Quantization of Large Language Models by Channel-wise Calibration
Mar 07, 2025Quantization has been widely used to compress and accelerate inference of large language models (LLMs). Existing methods focus on exploring the per-token dynamic calibration to ensure both inference acceleration and model accuracy under 4-bit quantization. However, in autoregressive generation inference of long sequences, the overhead of repeated dynamic quantization and dequantization steps becomes considerably expensive. In this work, we propose MergeQuant, an accurate and efficient per-channel static quantization framework. MergeQuant integrates the per-channel quantization steps with the corresponding scalings and linear mappings through a Quantization Step Migration (QSM) method, thereby eliminating the quantization overheads before and after matrix multiplication. Furthermore, in view of the significant differences between the different channel ranges, we propose dimensional reconstruction and adaptive clipping to address the non-uniformity of quantization scale factors and redistribute the channel variations to the subsequent modules to balance the parameter distribution under QSM. Within the static quantization setting of W4A4, MergeQuant reduces the accuracy gap on zero-shot tasks compared to FP16 baseline to 1.3 points on Llama-2-70B model. On Llama-2-7B model, MergeQuant achieves up to 1.77x speedup in decoding, and up to 2.06x speedup in end-to-end compared to FP16 baseline.
OIPR: Evaluation for Time-series Anomaly Detection Inspired by Operator Interest
Mar 03, 2025



With the growing adoption of time-series anomaly detection (TAD) technology, numerous studies have employed deep learning-based detectors for analyzing time-series data in the fields of Internet services, industrial systems, and sensors. The selection and optimization of anomaly detectors strongly rely on the availability of an effective performance evaluation method for TAD. Since anomalies in time-series data often manifest as a sequence of points, conventional metrics that solely consider the detection of individual point are inadequate. Existing evaluation methods for TAD typically employ point-based or event-based metrics to capture the temporal context. However, point-based metrics tend to overestimate detectors that excel only in detecting long anomalies, while event-based metrics are susceptible to being misled by fragmented detection results. To address these limitations, we propose OIPR, a novel set of TAD evaluation metrics. It models the process of operators receiving detector alarms and handling faults, utilizing area under the operator interest curve to evaluate the performance of TAD algorithms. Furthermore, we build a special scenario dataset to compare the characteristics of different evaluation methods. Through experiments conducted on the special scenario dataset and five real-world datasets, we demonstrate the remarkable performance of OIPR in extreme and complex scenarios. It achieves a balance between point and event perspectives, overcoming their primary limitations and offering applicability to broader situations.
ChatTime: A Unified Multimodal Time Series Foundation Model Bridging Numerical and Textual Data
Dec 16, 2024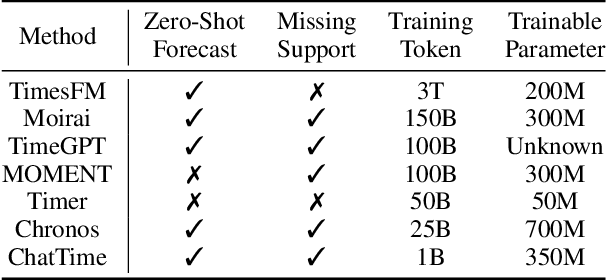
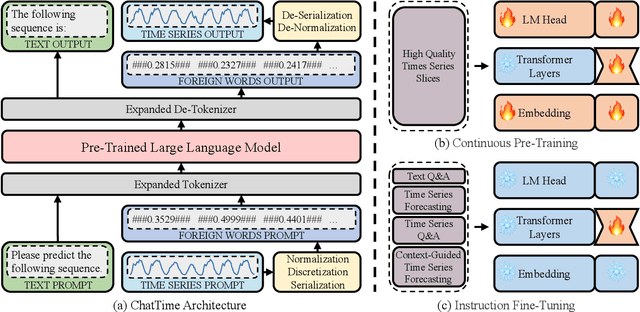

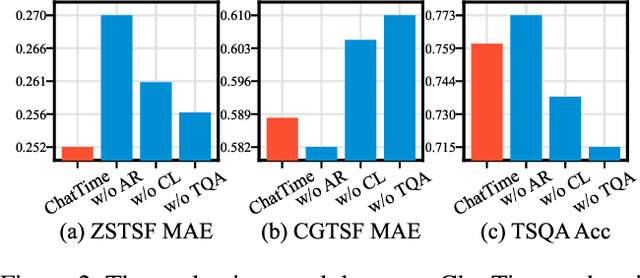
Human experts typically integrate numerical and textual multimodal information to analyze time series. However, most traditional deep learning predictors rely solely on unimodal numerical data, using a fixed-length window for training and prediction on a single dataset, and cannot adapt to different scenarios. The powered pre-trained large language model has introduced new opportunities for time series analysis. Yet, existing methods are either inefficient in training, incapable of handling textual information, or lack zero-shot forecasting capability. In this paper, we innovatively model time series as a foreign language and construct ChatTime, a unified framework for time series and text processing. As an out-of-the-box multimodal time series foundation model, ChatTime provides zero-shot forecasting capability and supports bimodal input/output for both time series and text. We design a series of experiments to verify the superior performance of ChatTime across multiple tasks and scenarios, and create four multimodal datasets to address data gaps. The experimental results demonstrate the potential and utility of ChatTime.
Interdependency Matters: Graph Alignment for Multivariate Time Series Anomaly Detection
Oct 11, 2024


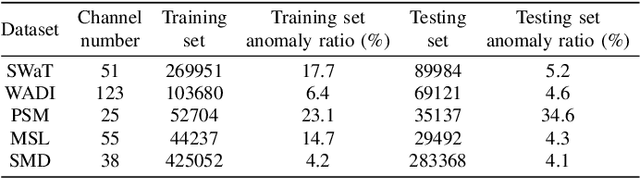
Anomaly detection in multivariate time series (MTS) is crucial for various applications in data mining and industry. Current industrial methods typically approach anomaly detection as an unsupervised learning task, aiming to identify deviations by estimating the normal distribution in noisy, label-free datasets. These methods increasingly incorporate interdependencies between channels through graph structures to enhance accuracy. However, the role of interdependencies is more critical than previously understood, as shifts in interdependencies between MTS channels from normal to anomalous data are significant. This observation suggests that \textit{anomalies could be detected by changes in these interdependency graph series}. To capitalize on this insight, we introduce MADGA (MTS Anomaly Detection via Graph Alignment), which redefines anomaly detection as a graph alignment (GA) problem that explicitly utilizes interdependencies for anomaly detection. MADGA dynamically transforms subsequences into graphs to capture the evolving interdependencies, and Graph alignment is performed between these graphs, optimizing an alignment plan that minimizes cost, effectively minimizing the distance for normal data and maximizing it for anomalous data. Uniquely, our GA approach involves explicit alignment of both nodes and edges, employing Wasserstein distance for nodes and Gromov-Wasserstein distance for edges. To our knowledge, this is the first application of GA to MTS anomaly detection that explicitly leverages interdependency for this purpose. Extensive experiments on diverse real-world datasets validate the effectiveness of MADGA, demonstrating its capability to detect anomalies and differentiate interdependencies, consistently achieving state-of-the-art across various scenarios.
Rethinking the Power of Timestamps for Robust Time Series Forecasting: A Global-Local Fusion Perspective
Sep 27, 2024



Time series forecasting has played a pivotal role across various industries, including finance, transportation, energy, healthcare, and climate. Due to the abundant seasonal information they contain, timestamps possess the potential to offer robust global guidance for forecasting techniques. However, existing works primarily focus on local observations, with timestamps being treated merely as an optional supplement that remains underutilized. When data gathered from the real world is polluted, the absence of global information will damage the robust prediction capability of these algorithms. To address these problems, we propose a novel framework named GLAFF. Within this framework, the timestamps are modeled individually to capture the global dependencies. Working as a plugin, GLAFF adaptively adjusts the combined weights for global and local information, enabling seamless collaboration with any time series forecasting backbone. Extensive experiments conducted on nine real-world datasets demonstrate that GLAFF significantly enhances the average performance of widely used mainstream forecasting models by 12.5%, surpassing the previous state-of-the-art method by 5.5%.
OutlierTune: Efficient Channel-Wise Quantization for Large Language Models
Jun 27, 2024



Quantizing the activations of large language models (LLMs) has been a significant challenge due to the presence of structured outliers. Most existing methods focus on the per-token or per-tensor quantization of activations, making it difficult to achieve both accuracy and hardware efficiency. To address this problem, we propose OutlierTune, an efficient per-channel post-training quantization (PTQ) method for the activations of LLMs. OutlierTune consists of two components: pre-execution of dequantization and symmetrization. The pre-execution of dequantization updates the model weights by the activation scaling factors, avoiding the internal scaling and costly additional computational overheads brought by the per-channel activation quantization. The symmetrization further reduces the quantization differences arising from the weight updates by ensuring the balanced numerical ranges across different activation channels. OutlierTune is easy to implement and hardware-efficient, introducing almost no additional computational overheads during the inference. Extensive experiments show that the proposed framework outperforms existing methods across multiple different tasks. Demonstrating better generalization, this framework improves the Int6 quantization of the instruction-tuning LLMs, such as OPT-IML, to the same level as half-precision (FP16). Moreover, we have shown that the proposed framework is 1.48x faster than the FP16 implementation while reducing approximately 2x memory usage.
Understanding and Guiding Weakly Supervised Entity Alignment with Potential Isomorphism Propagation
Feb 05, 2024



Weakly Supervised Entity Alignment (EA) is the task of identifying equivalent entities across diverse knowledge graphs (KGs) using only a limited number of seed alignments. Despite substantial advances in aggregation-based weakly supervised EA, the underlying mechanisms in this setting remain unexplored. In this paper, we present a propagation perspective to analyze weakly supervised EA and explain the existing aggregation-based EA models. Our theoretical analysis reveals that these models essentially seek propagation operators for pairwise entity similarities. We further prove that, despite the structural heterogeneity of different KGs, the potentially aligned entities within aggregation-based EA models have isomorphic subgraphs, which is the core premise of EA but has not been investigated. Leveraging this insight, we introduce a potential isomorphism propagation operator to enhance the propagation of neighborhood information across KGs. We develop a general EA framework, PipEA, incorporating this operator to improve the accuracy of every type of aggregation-based model without altering the learning process. Extensive experiments substantiate our theoretical findings and demonstrate PipEA's significant performance gains over state-of-the-art weakly supervised EA methods. Our work not only advances the field but also enhances our comprehension of aggregation-based weakly supervised EA.