 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFluxMem: Adaptive Hierarchical Memory for Streaming Video Understanding
Mar 02, 2026This paper presents FluxMem, a training-free framework for efficient streaming video understanding. FluxMem adaptively compresses redundant visual memory through a hierarchical, two-stage design: (1) a Temporal Adjacency Selection (TAS) module removes redundant visual tokens across adjacent frames, and (2) a Spatial Domain Consolidation (SDC) module further merges spatially repetitive regions within each frame into compact representations. To adapt effectively to dynamic scenes, we introduce a self-adaptive token compression mechanism in both TAS and SDC, which automatically determines the compression rate based on intrinsic scene statistics rather than manual tuning. Extensive experiments demonstrate that FluxMem achieves new state-of-the-art results on existing online video benchmarks, reaching 76.4 on StreamingBench and 67.2 on OVO-Bench under real-time settings, while reducing latency by 69.9% and peak GPU memory by 34.5% on OVO-Bench. Furthermore, it maintains strong offline performance, achieving 73.1 on MLVU while using 65% fewer visual tokens.
VideoLoom: A Video Large Language Model for Joint Spatial-Temporal Understanding
Jan 12, 2026This paper presents VideoLoom, a unified Video Large Language Model (Video LLM) for joint spatial-temporal understanding. To facilitate the development of fine-grained spatial and temporal localization capabilities, we curate LoomData-8.7k, a human-centric video dataset with temporally grounded and spatially localized captions. With this, VideoLoom achieves state-of-the-art or highly competitive performance across a variety of spatial and temporal benchmarks (e.g., 63.1 J&F on ReVOS for referring video object segmentation, and 48.3 R1@0.7 on Charades-STA for temporal grounding). In addition, we introduce LoomBench, a novel benchmark consisting of temporal, spatial, and compositional video-question pairs, enabling a comprehensive evaluation of Video LLMs from diverse aspects. Collectively, these contributions offer a universal and effective suite for joint spatial-temporal video understanding, setting a new standard in multimodal intelligence.
OIPR: Evaluation for Time-series Anomaly Detection Inspired by Operator Interest
Mar 03, 2025



With the growing adoption of time-series anomaly detection (TAD) technology, numerous studies have employed deep learning-based detectors for analyzing time-series data in the fields of Internet services, industrial systems, and sensors. The selection and optimization of anomaly detectors strongly rely on the availability of an effective performance evaluation method for TAD. Since anomalies in time-series data often manifest as a sequence of points, conventional metrics that solely consider the detection of individual point are inadequate. Existing evaluation methods for TAD typically employ point-based or event-based metrics to capture the temporal context. However, point-based metrics tend to overestimate detectors that excel only in detecting long anomalies, while event-based metrics are susceptible to being misled by fragmented detection results. To address these limitations, we propose OIPR, a novel set of TAD evaluation metrics. It models the process of operators receiving detector alarms and handling faults, utilizing area under the operator interest curve to evaluate the performance of TAD algorithms. Furthermore, we build a special scenario dataset to compare the characteristics of different evaluation methods. Through experiments conducted on the special scenario dataset and five real-world datasets, we demonstrate the remarkable performance of OIPR in extreme and complex scenarios. It achieves a balance between point and event perspectives, overcoming their primary limitations and offering applicability to broader situations.
Pix2Cap-COCO: Advancing Visual Comprehension via Pixel-Level Captioning
Jan 23, 2025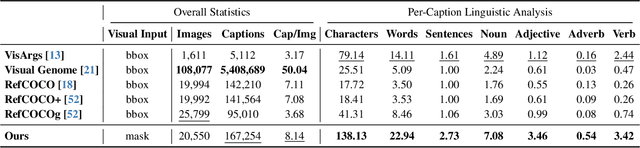
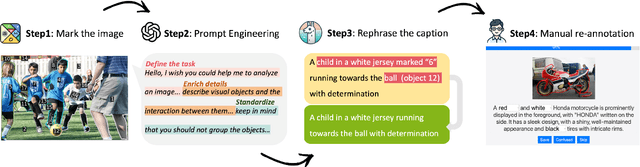

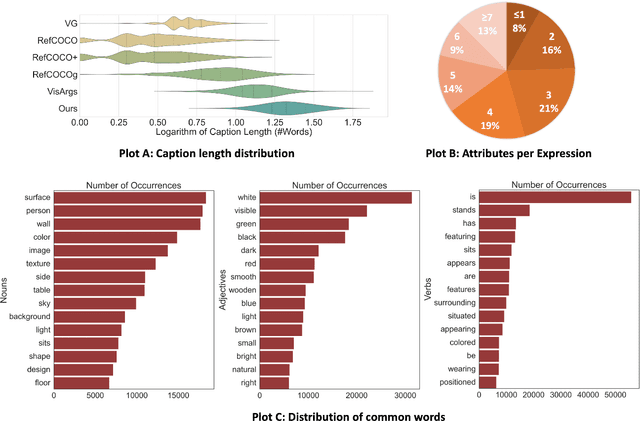
We present Pix2Cap-COCO, the first panoptic pixel-level caption dataset designed to advance fine-grained visual understanding. To achieve this, we carefully design an automated annotation pipeline that prompts GPT-4V to generate pixel-aligned, instance-specific captions for individual objects within images, enabling models to learn more granular relationships between objects and their contexts. This approach results in 167,254 detailed captions, with an average of 22.94 words per caption. Building on Pix2Cap-COCO, we introduce a novel task, panoptic segmentation-captioning, which challenges models to recognize instances in an image and provide detailed descriptions for each simultaneously. To benchmark this task, we design a robust baseline based on X-Decoder. The experimental results demonstrate that Pix2Cap-COCO is a particularly challenging dataset, as it requires models to excel in both fine-grained visual understanding and detailed language generation. Furthermore, we leverage Pix2Cap-COCO for Supervised Fine-Tuning (SFT) on large multimodal models (LMMs) to enhance their performance. For example, training with Pix2Cap-COCO significantly improves the performance of GPT4RoI, yielding gains in CIDEr +1.4%, ROUGE +0.4%, and SPICE +0.5% on Visual Genome dataset, and strengthens its region understanding ability on the ViP-BENCH, with an overall improvement of +5.1%, including notable increases in recognition accuracy +11.2% and language generation quality +22.2%.
Evaluating the Design Features of an Intelligent Tutoring System for Advanced Mathematics Learning
Dec 23, 2024Xiaomai is an intelligent tutoring system (ITS) designed to help Chinese college students in learning advanced mathematics and preparing for the graduate school math entrance exam. This study investigates two distinctive features within Xiaomai: the incorporation of free-response questions with automatic feedback and the metacognitive element of reflecting on self-made errors.
UMono: Physical Model Informed Hybrid CNN-Transformer Framework for Underwater Monocular Depth Estimation
Jul 25, 2024

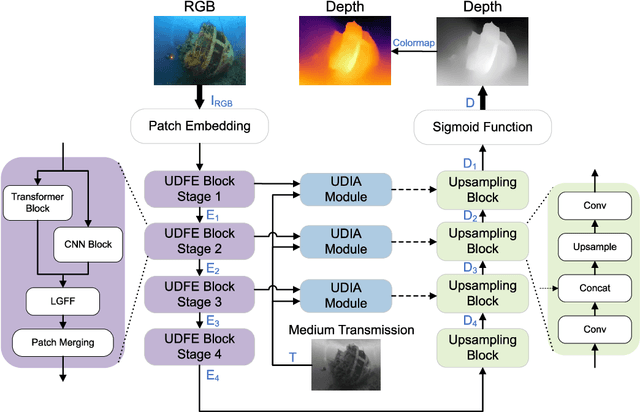

Underwater monocular depth estimation serves as the foundation for tasks such as 3D reconstruction of underwater scenes. However, due to the influence of light and medium, the underwater environment undergoes a distinctive imaging process, which presents challenges in accurately estimating depth from a single image. The existing methods fail to consider the unique characteristics of underwater environments, leading to inadequate estimation results and limited generalization performance. Furthermore, underwater depth estimation requires extracting and fusing both local and global features, which is not fully explored in existing methods. In this paper, an end-to-end learning framework for underwater monocular depth estimation called UMono is presented, which incorporates underwater image formation model characteristics into network architecture, and effectively utilize both local and global features of underwater image. Experimental results demonstrate that the proposed method is effective for underwater monocular depth estimation and outperforms the existing methods in both quantitative and qualitative analyses.
MA-LMM: Memory-Augmented Large Multimodal Model for Long-Term Video Understanding
Apr 08, 2024



With the success of large language models (LLMs), integrating the vision model into LLMs to build vision-language foundation models has gained much more interest recently. However, existing LLM-based large multimodal models (e.g., Video-LLaMA, VideoChat) can only take in a limited number of frames for short video understanding. In this study, we mainly focus on designing an efficient and effective model for long-term video understanding. Instead of trying to process more frames simultaneously like most existing work, we propose to process videos in an online manner and store past video information in a memory bank. This allows our model to reference historical video content for long-term analysis without exceeding LLMs' context length constraints or GPU memory limits. Our memory bank can be seamlessly integrated into current multimodal LLMs in an off-the-shelf manner. We conduct extensive experiments on various video understanding tasks, such as long-video understanding, video question answering, and video captioning, and our model can achieve state-of-the-art performances across multiple datasets. Code available at https://boheumd.github.io/MA-LMM/.
OmniVid: A Generative Framework for Universal Video Understanding
Mar 26, 2024



The core of video understanding tasks, such as recognition, captioning, and tracking, is to automatically detect objects or actions in a video and analyze their temporal evolution. Despite sharing a common goal, different tasks often rely on distinct model architectures and annotation formats. In contrast, natural language processing benefits from a unified output space, i.e., text sequences, which simplifies the training of powerful foundational language models, such as GPT-3, with extensive training corpora. Inspired by this, we seek to unify the output space of video understanding tasks by using languages as labels and additionally introducing time and box tokens. In this way, a variety of video tasks could be formulated as video-grounded token generation. This enables us to address various types of video tasks, including classification (such as action recognition), captioning (covering clip captioning, video question answering, and dense video captioning), and localization tasks (such as visual object tracking) within a fully shared encoder-decoder architecture, following a generative framework. Through comprehensive experiments, we demonstrate such a simple and straightforward idea is quite effective and can achieve state-of-the-art or competitive results on seven video benchmarks, providing a novel perspective for more universal video understanding. Code is available at https://github.com/wangjk666/OmniVid.
To See is to Believe: Prompting GPT-4V for Better Visual Instruction Tuning
Nov 29, 2023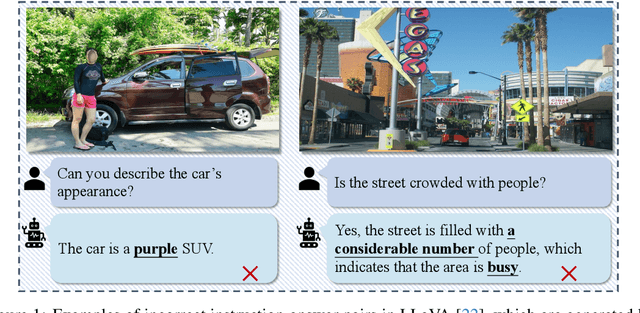
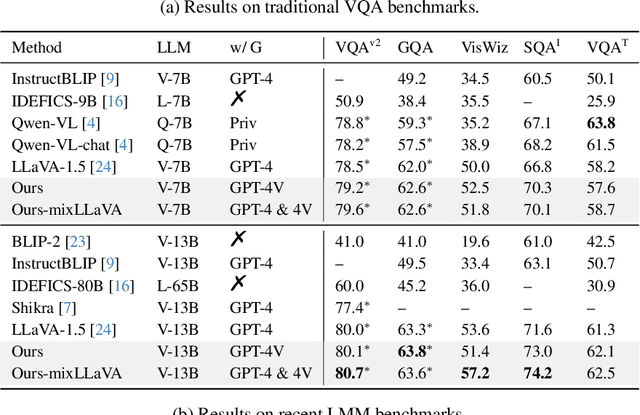
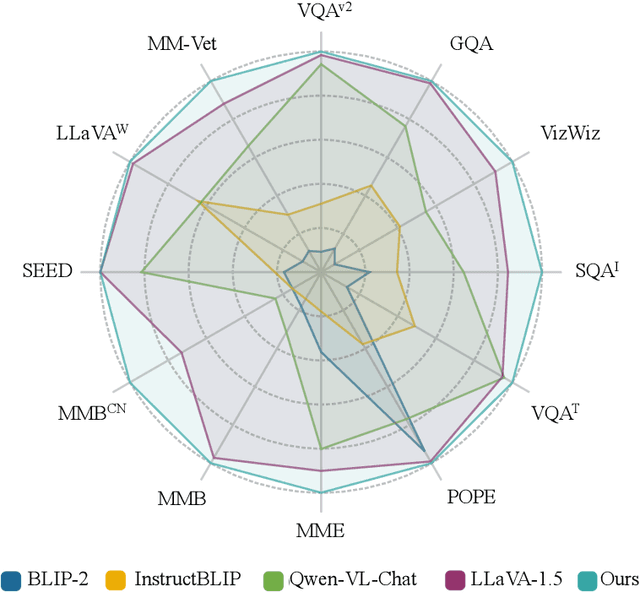
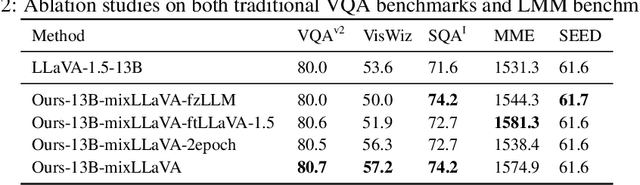
Existing visual instruction tuning methods typically prompt large language models with textual descriptions to generate instruction-following data. Despite the promising performance achieved, these descriptions are derived from image annotations, which are oftentimes coarse-grained. Furthermore, the instructions might even contradict the visual content without observing the entire visual context. To address this challenge, we introduce a fine-grained visual instruction dataset, LVIS-Instruct4V, which contains 220K visually aligned and context-aware instructions produced by prompting the powerful GPT-4V with images from LVIS. Through experimental validation and case studies, we demonstrate that high-quality visual instructional data could improve the performance of LLaVA-1.5, a state-of-the-art large multimodal model, across a wide spectrum of benchmarks by clear margins. Notably, by simply replacing the LLaVA-Instruct with our LVIS-Instruct4V, we achieve better results than LLaVA on most challenging LMM benchmarks, e.g., LLaVA$^w$ (76.7 vs. 70.7) and MM-Vet (40.2 vs. 35.4). We release our data and model at https://github.com/X2FD/LVIS-INSTRUCT4V.
Chop & Learn: Recognizing and Generating Object-State Compositions
Sep 25, 2023



Recognizing and generating object-state compositions has been a challenging task, especially when generalizing to unseen compositions. In this paper, we study the task of cutting objects in different styles and the resulting object state changes. We propose a new benchmark suite Chop & Learn, to accommodate the needs of learning objects and different cut styles using multiple viewpoints. We also propose a new task of Compositional Image Generation, which can transfer learned cut styles to different objects, by generating novel object-state images. Moreover, we also use the videos for Compositional Action Recognition, and show valuable uses of this dataset for multiple video tasks. Project website: https://chopnlearn.github.io.