 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
Feb 11, 2026We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
STEP3-VL-10B Technical Report
Jan 15, 2026We present STEP3-VL-10B, a lightweight open-source foundation model designed to redefine the trade-off between compact efficiency and frontier-level multimodal intelligence. STEP3-VL-10B is realized through two strategic shifts: first, a unified, fully unfrozen pre-training strategy on 1.2T multimodal tokens that integrates a language-aligned Perception Encoder with a Qwen3-8B decoder to establish intrinsic vision-language synergy; and second, a scaled post-training pipeline featuring over 1k iterations of reinforcement learning. Crucially, we implement Parallel Coordinated Reasoning (PaCoRe) to scale test-time compute, allocating resources to scalable perceptual reasoning that explores and synthesizes diverse visual hypotheses. Consequently, despite its compact 10B footprint, STEP3-VL-10B rivals or surpasses models 10$\times$-20$\times$ larger (e.g., GLM-4.6V-106B, Qwen3-VL-235B) and top-tier proprietary flagships like Gemini 2.5 Pro and Seed-1.5-VL. Delivering best-in-class performance, it records 92.2% on MMBench and 80.11% on MMMU, while excelling in complex reasoning with 94.43% on AIME2025 and 75.95% on MathVision. We release the full model suite to provide the community with a powerful, efficient, and reproducible baseline.
Step-GUI Technical Report
Dec 19, 2025



Recent advances in multimodal large language models unlock unprecedented opportunities for GUI automation. However, a fundamental challenge remains: how to efficiently acquire high-quality training data while maintaining annotation reliability? We introduce a self-evolving training pipeline powered by the Calibrated Step Reward System, which converts model-generated trajectories into reliable training signals through trajectory-level calibration, achieving >90% annotation accuracy with 10-100x lower cost. Leveraging this pipeline, we introduce Step-GUI, a family of models (4B/8B) that achieves state-of-the-art GUI performance (8B: 80.2% AndroidWorld, 48.5% OSWorld, 62.6% ScreenShot-Pro) while maintaining robust general capabilities. As GUI agent capabilities improve, practical deployment demands standardized interfaces across heterogeneous devices while protecting user privacy. To this end, we propose GUI-MCP, the first Model Context Protocol for GUI automation with hierarchical architecture that combines low-level atomic operations and high-level task delegation to local specialist models, enabling high-privacy execution where sensitive data stays on-device. Finally, to assess whether agents can handle authentic everyday usage, we introduce AndroidDaily, a benchmark grounded in real-world mobile usage patterns with 3146 static actions and 235 end-to-end tasks across high-frequency daily scenarios (8B: static 89.91%, end-to-end 52.50%). Our work advances the development of practical GUI agents and demonstrates strong potential for real-world deployment in everyday digital interactions.
Human2Robot: Learning Robot Actions from Paired Human-Robot Videos
Feb 23, 2025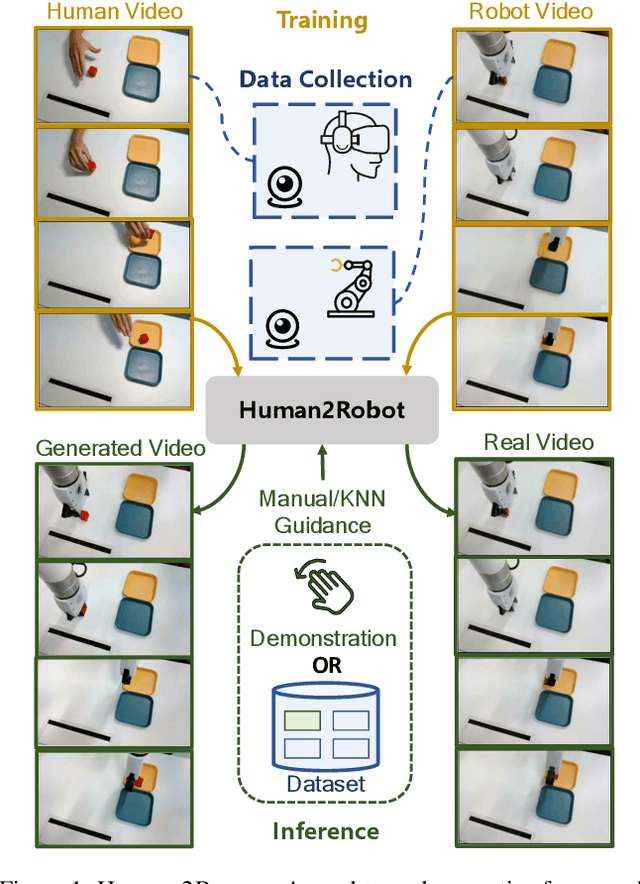
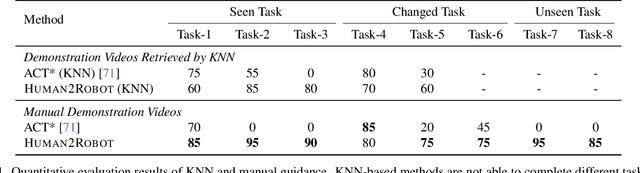

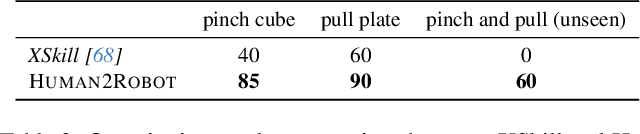
Distilling knowledge from human demonstrations is a promising way for robots to learn and act. Existing work often overlooks the differences between humans and robots, producing unsatisfactory results. In this paper, we study how perfectly aligned human-robot pairs benefit robot learning. Capitalizing on VR-based teleportation, we introduce H\&R, a third-person dataset with 2,600 episodes, each of which captures the fine-grained correspondence between human hands and robot gripper. Inspired by the recent success of diffusion models, we introduce Human2Robot, an end-to-end diffusion framework that formulates learning from human demonstrates as a generative task. Human2Robot fully explores temporal dynamics in human videos to generate robot videos and predict actions at the same time. Through comprehensive evaluations of 8 seen, changed and unseen tasks in real-world settings, we demonstrate that Human2Robot can not only generate high-quality robot videos but also excel in seen tasks and generalize to unseen objects, backgrounds and even new tasks effortlessly.
GenRec: Unifying Video Generation and Recognition with Diffusion Models
Aug 27, 2024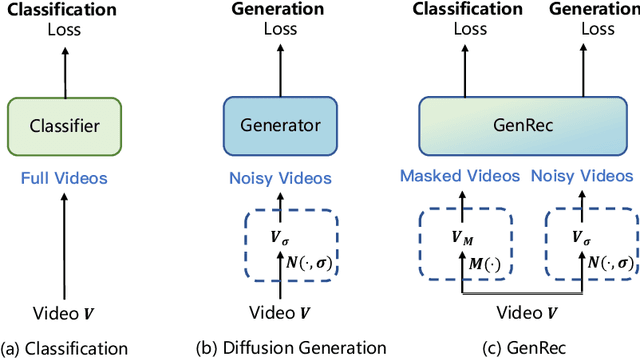
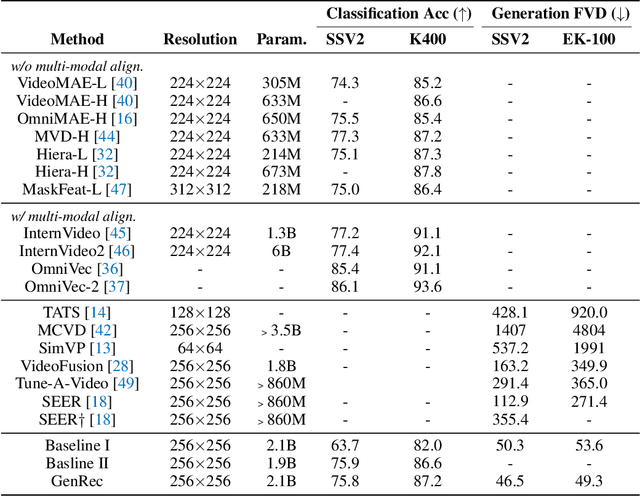
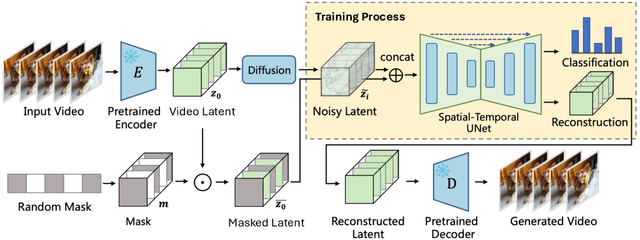
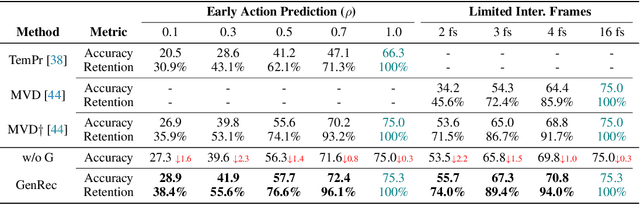
Video diffusion models are able to generate high-quality videos by learning strong spatial-temporal priors on large-scale datasets. In this paper, we aim to investigate whether such priors derived from a generative process are suitable for video recognition, and eventually joint optimization of generation and recognition. Building upon Stable Video Diffusion, we introduce GenRec, the first unified framework trained with a random-frame conditioning process so as to learn generalized spatial-temporal representations. The resulting framework can naturally supports generation and recognition, and more importantly is robust even when visual inputs contain limited information. Extensive experiments demonstrate the efficacy of GenRec for both recognition and generation. In particular, GenRec achieves competitive recognition performance, offering 75.8% and 87.2% accuracy on SSV2 and K400, respectively. GenRec also performs the best class-conditioned image-to-video generation results, achieving 46.5 and 49.3 FVD scores on SSV2 and EK-100 datasets. Furthermore, GenRec demonstrates extraordinary robustness in scenarios that only limited frames can be observed.
AID: Adapting Image2Video Diffusion Models for Instruction-guided Video Prediction
Jun 10, 2024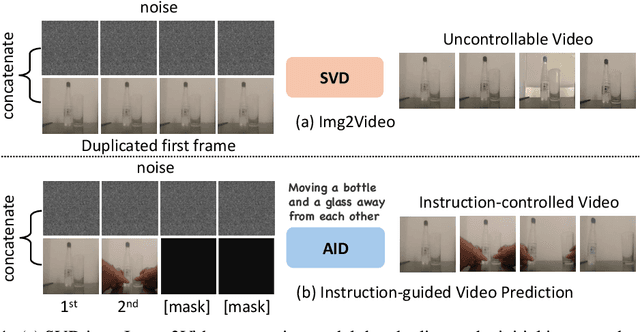
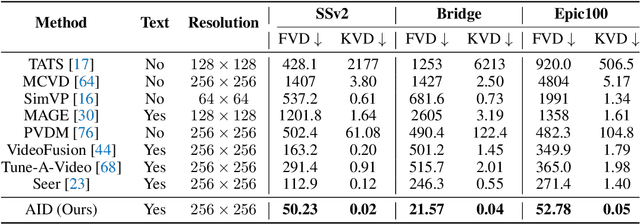
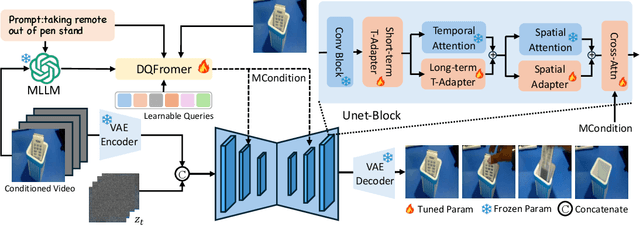

Text-guided video prediction (TVP) involves predicting the motion of future frames from the initial frame according to an instruction, which has wide applications in virtual reality, robotics, and content creation. Previous TVP methods make significant breakthroughs by adapting Stable Diffusion for this task. However, they struggle with frame consistency and temporal stability primarily due to the limited scale of video datasets. We observe that pretrained Image2Video diffusion models possess good priors for video dynamics but they lack textual control. Hence, transferring Image2Video models to leverage their video dynamic priors while injecting instruction control to generate controllable videos is both a meaningful and challenging task. To achieve this, we introduce the Multi-Modal Large Language Model (MLLM) to predict future video states based on initial frames and text instructions. More specifically, we design a dual query transformer (DQFormer) architecture, which integrates the instructions and frames into the conditional embeddings for future frame prediction. Additionally, we develop Long-Short Term Temporal Adapters and Spatial Adapters that can quickly transfer general video diffusion models to specific scenarios with minimal training costs. Experimental results show that our method significantly outperforms state-of-the-art techniques on four datasets: Something Something V2, Epic Kitchen-100, Bridge Data, and UCF-101. Notably, AID achieves 91.2% and 55.5% FVD improvements on Bridge and SSv2 respectively, demonstrating its effectiveness in various domains. More examples can be found at our website https://chenhsing.github.io/AID.
To See is to Believe: Prompting GPT-4V for Better Visual Instruction Tuning
Nov 29, 2023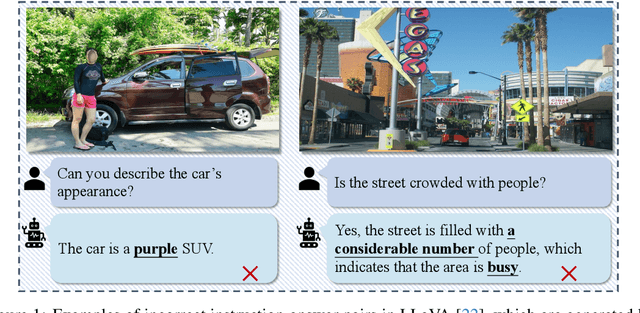
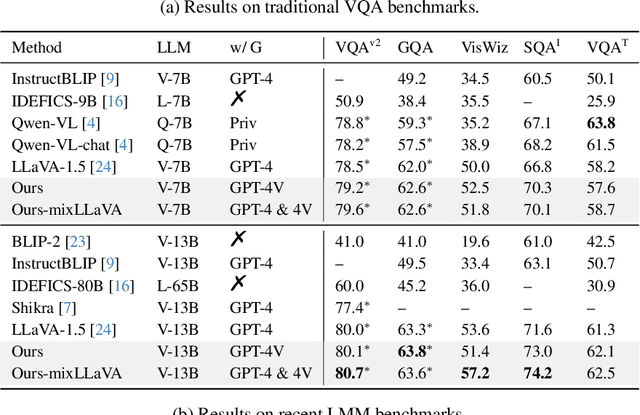
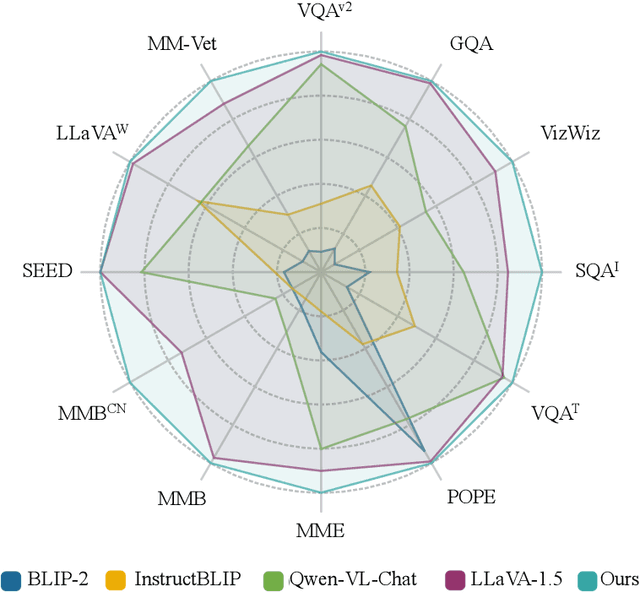
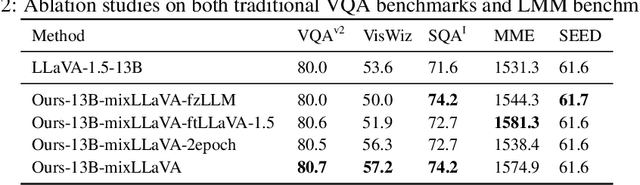
Existing visual instruction tuning methods typically prompt large language models with textual descriptions to generate instruction-following data. Despite the promising performance achieved, these descriptions are derived from image annotations, which are oftentimes coarse-grained. Furthermore, the instructions might even contradict the visual content without observing the entire visual context. To address this challenge, we introduce a fine-grained visual instruction dataset, LVIS-Instruct4V, which contains 220K visually aligned and context-aware instructions produced by prompting the powerful GPT-4V with images from LVIS. Through experimental validation and case studies, we demonstrate that high-quality visual instructional data could improve the performance of LLaVA-1.5, a state-of-the-art large multimodal model, across a wide spectrum of benchmarks by clear margins. Notably, by simply replacing the LLaVA-Instruct with our LVIS-Instruct4V, we achieve better results than LLaVA on most challenging LMM benchmarks, e.g., LLaVA$^w$ (76.7 vs. 70.7) and MM-Vet (40.2 vs. 35.4). We release our data and model at https://github.com/X2FD/LVIS-INSTRUCT4V.
Building an Open-Vocabulary Video CLIP Model with Better Architectures, Optimization and Data
Oct 08, 2023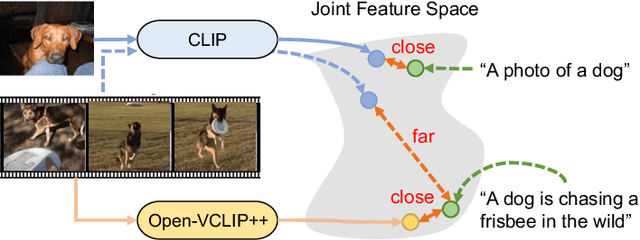
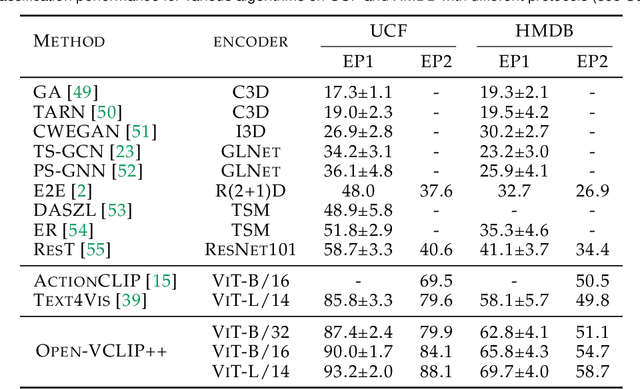

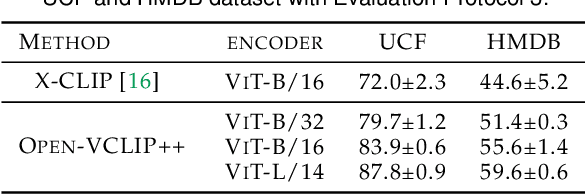
Despite significant results achieved by Contrastive Language-Image Pretraining (CLIP) in zero-shot image recognition, limited effort has been made exploring its potential for zero-shot video recognition. This paper presents Open-VCLIP++, a simple yet effective framework that adapts CLIP to a strong zero-shot video classifier, capable of identifying novel actions and events during testing. Open-VCLIP++ minimally modifies CLIP to capture spatial-temporal relationships in videos, thereby creating a specialized video classifier while striving for generalization. We formally demonstrate that training Open-VCLIP++ is tantamount to continual learning with zero historical data. To address this problem, we introduce Interpolated Weight Optimization, a technique that leverages the advantages of weight interpolation during both training and testing. Furthermore, we build upon large language models to produce fine-grained video descriptions. These detailed descriptions are further aligned with video features, facilitating a better transfer of CLIP to the video domain. Our approach is evaluated on three widely used action recognition datasets, following a variety of zero-shot evaluation protocols. The results demonstrate that our method surpasses existing state-of-the-art techniques by significant margins. Specifically, we achieve zero-shot accuracy scores of 88.1%, 58.7%, and 81.2% on UCF, HMDB, and Kinetics-600 datasets respectively, outpacing the best-performing alternative methods by 8.5%, 8.2%, and 12.3%. We also evaluate our approach on the MSR-VTT video-text retrieval dataset, where it delivers competitive video-to-text and text-to-video retrieval performance, while utilizing substantially less fine-tuning data compared to other methods. Code is released at https://github.com/wengzejia1/Open-VCLIP.
BMB: Balanced Memory Bank for Imbalanced Semi-supervised Learning
May 22, 2023Exploring a substantial amount of unlabeled data, semi-supervised learning (SSL) boosts the recognition performance when only a limited number of labels are provided. However, traditional methods assume that the data distribution is class-balanced, which is difficult to achieve in reality due to the long-tailed nature of real-world data. While the data imbalance problem has been extensively studied in supervised learning (SL) paradigms, directly transferring existing approaches to SSL is nontrivial, as prior knowledge about data distribution remains unknown in SSL. In light of this, we propose Balanced Memory Bank (BMB), a semi-supervised framework for long-tailed recognition. The core of BMB is an online-updated memory bank that caches historical features with their corresponding pseudo labels, and the memory is also carefully maintained to ensure the data therein are class-rebalanced. Additionally, an adaptive weighting module is introduced to work jointly with the memory bank so as to further re-calibrate the biased training process. We conduct experiments on multiple datasets and demonstrate, among other things, that BMB surpasses state-of-the-art approaches by clear margins, for example 8.2$\%$ on the 1$\%$ labeled subset of ImageNet127 (with a resolution of 64$\times$64) and 4.3$\%$ on the 50$\%$ labeled subset of ImageNet-LT.
Transforming CLIP to an Open-vocabulary Video Model via Interpolated Weight Optimization
Feb 01, 2023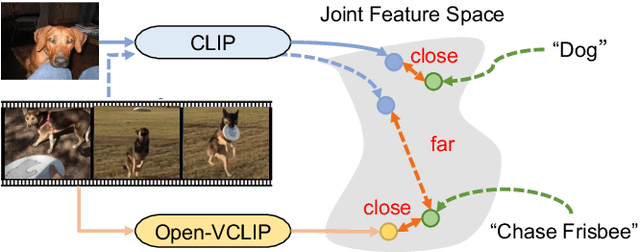
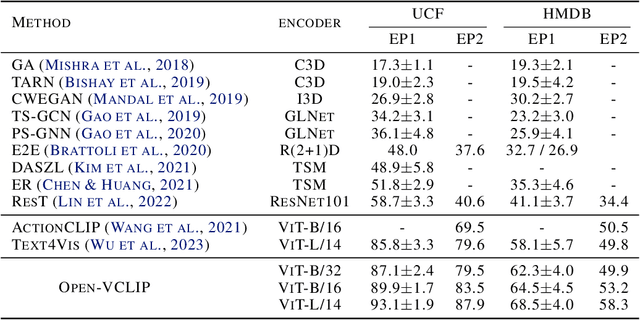
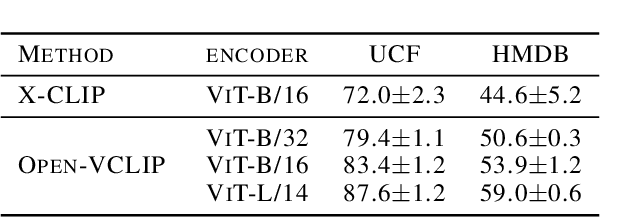
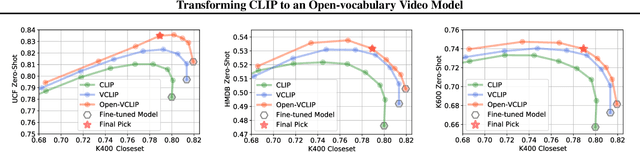
Contrastive Language-Image Pretraining (CLIP) has demonstrated impressive zero-shot learning abilities for image understanding, yet limited effort has been made to investigate CLIP for zero-shot video recognition. We introduce Open-VCLIP, a simple yet effective approach that transforms CLIP into strong zero-shot video classifiers that can recognize unseen actions and events at test time. Our framework extends CLIP with minimal modifications to model spatial-temporal relationships in videos, making it a specialized video classifier, while striving for generalization. We formally show that training an Open-VCLIP is equivalent to continual learning with zero historical data. To address this problem, we propose Interpolated Weight Optimization, which utilizes the benefit of weight interpolation in both training and test time. We evaluate our method on three popular and challenging action recognition datasets following various zero-shot evaluation protocols and we demonstrate our approach outperforms state-of-the-art methods by clear margins. In particular, we achieve 87.9%, 58.3%, 81.1% zero-shot accuracy on UCF, HMDB and Kinetics-600 respectively, outperforming state-of-the-art methods by 8.3%, 7.8% and 12.2%.