 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-Supervised Vision Transformers
Paper and Code
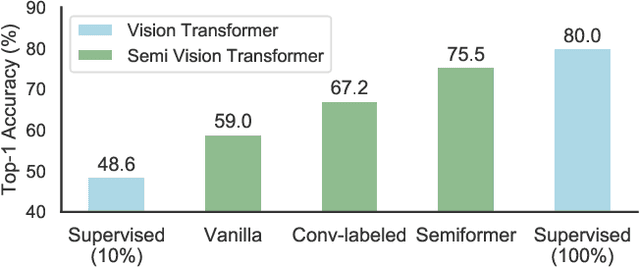

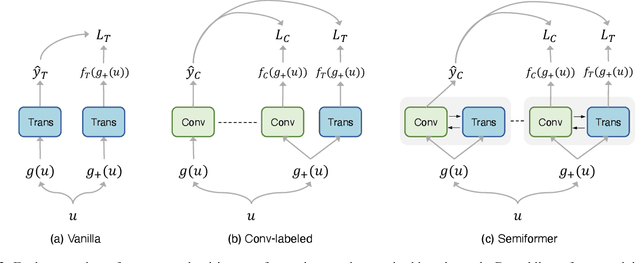

We study the training of Vision Transformers for semi-supervised image classification. Transformers have recently demonstrated impressive performance on a multitude of supervised learning tasks. Surprisingly, we find Vision Transformers perform poorly on a semi-supervised ImageNet setting. In contrast, Convolutional Neural Networks (CNNs) achieve superior results in small labeled data regime. Further investigation reveals that the reason is CNNs have strong spatial inductive bias. Inspired by this observation, we introduce a joint semi-supervised learning framework, Semiformer, which contains a Transformer branch, a Convolutional branch and a carefully designed fusion module for knowledge sharing between the branches. The Convolutional branch is trained on the limited supervised data and generates pseudo labels to supervise the training of the transformer branch on unlabeled data. Extensive experiments on ImageNet demonstrate that Semiformer achieves 75.5\% top-1 accuracy, outperforming the state-of-the-art. In addition, we show Semiformer is a general framework which is compatible with most modern Transformer and Convolutional neural architectures.