 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreference Score Distillation: Leveraging 2D Rewards to Align Text-to-3D Generation with Human Preference
Mar 02, 2026Human preference alignment presents a critical yet underexplored challenge for diffusion models in text-to-3D generation. Existing solutions typically require task-specific fine-tuning, posing significant hurdles in data-scarce 3D domains. To address this, we propose Preference Score Distillation (PSD), an optimization-based framework that leverages pretrained 2D reward models for human-aligned text-to-3D synthesis without 3D training data. Our key insight stems from the incompatibility of pixel-level gradients: due to the absence of noisy samples during reward model training, direct application of 2D reward gradients disturbs the denoising process. Noticing that similar issue occurs in the naive classifier guidance in conditioned diffusion models, we fundamentally rethink preference alignment as a classifier-free guidance (CFG)-style mechanism through our implicit reward model. Furthermore, recognizing that frozen pretrained diffusion models constrain performance, we introduce an adaptive strategy to co-optimize preference scores and negative text embeddings. By incorporating CFG during optimization, online refinement of negative text embeddings dynamically enhances alignment. To our knowledge, we are the first to bridge human preference alignment with CFG theory under score distillation framework. Experiments demonstrate the superiority of PSD in aesthetic metrics, seamless integration with diverse pipelines, and strong extensibility.
Ask-to-Clarify: Resolving Instruction Ambiguity through Multi-turn Dialogue
Sep 18, 2025The ultimate goal of embodied agents is to create collaborators that can interact with humans, not mere executors that passively follow instructions. This requires agents to communicate, coordinate, and adapt their actions based on human feedback. Recently, advances in VLAs have offered a path toward this goal. However, most current VLA-based embodied agents operate in a one-way mode: they receive an instruction and execute it without feedback. This approach fails in real-world scenarios where instructions are often ambiguous. In this paper, we address this problem with the Ask-to-Clarify framework. Our framework first resolves ambiguous instructions by asking questions in a multi-turn dialogue. Then it generates low-level actions end-to-end. Specifically, the Ask-to-Clarify framework consists of two components, one VLM for collaboration and one diffusion for action. We also introduce a connection module that generates conditions for the diffusion based on the output of the VLM. This module adjusts the observation by instructions to create reliable conditions. We train our framework with a two-stage knowledge-insulation strategy. First, we fine-tune the collaboration component using ambiguity-solving dialogue data to handle ambiguity. Then, we integrate the action component while freezing the collaboration one. This preserves the interaction abilities while fine-tuning the diffusion to generate actions. The training strategy guarantees our framework can first ask questions, then generate actions. During inference, a signal detector functions as a router that helps our framework switch between asking questions and taking actions. We evaluate the Ask-to-Clarify framework in 8 real-world tasks, where it outperforms existing state-of-the-art VLAs. The results suggest that our proposed framework, along with the training strategy, provides a path toward collaborative embodied agents.
Human2Robot: Learning Robot Actions from Paired Human-Robot Videos
Feb 23, 2025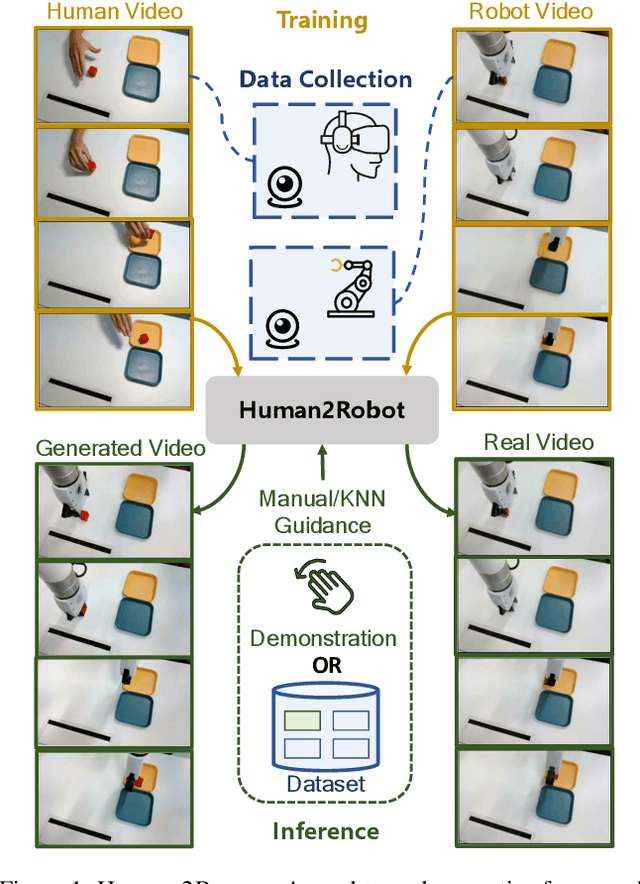
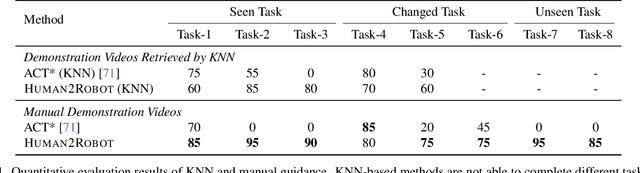

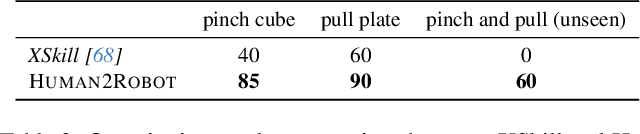
Distilling knowledge from human demonstrations is a promising way for robots to learn and act. Existing work often overlooks the differences between humans and robots, producing unsatisfactory results. In this paper, we study how perfectly aligned human-robot pairs benefit robot learning. Capitalizing on VR-based teleportation, we introduce H\&R, a third-person dataset with 2,600 episodes, each of which captures the fine-grained correspondence between human hands and robot gripper. Inspired by the recent success of diffusion models, we introduce Human2Robot, an end-to-end diffusion framework that formulates learning from human demonstrates as a generative task. Human2Robot fully explores temporal dynamics in human videos to generate robot videos and predict actions at the same time. Through comprehensive evaluations of 8 seen, changed and unseen tasks in real-world settings, we demonstrate that Human2Robot can not only generate high-quality robot videos but also excel in seen tasks and generalize to unseen objects, backgrounds and even new tasks effortlessly.
MotionFollower: Editing Video Motion via Lightweight Score-Guided Diffusion
May 30, 2024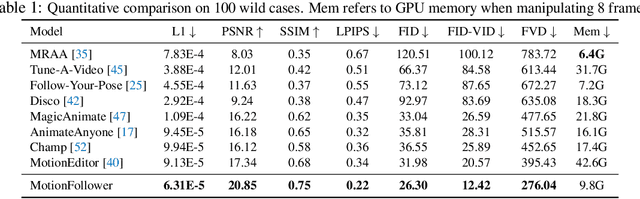
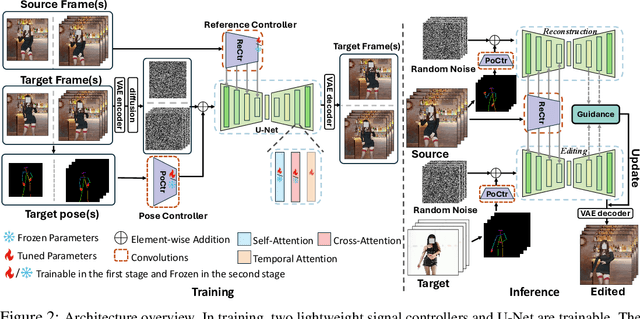
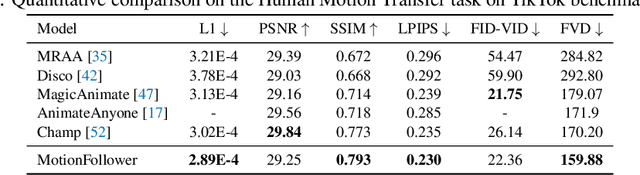

Despite impressive advancements in diffusion-based video editing models in altering video attributes, there has been limited exploration into modifying motion information while preserving the original protagonist's appearance and background. In this paper, we propose MotionFollower, a lightweight score-guided diffusion model for video motion editing. To introduce conditional controls to the denoising process, MotionFollower leverages two of our proposed lightweight signal controllers, one for poses and the other for appearances, both of which consist of convolution blocks without involving heavy attention calculations. Further, we design a score guidance principle based on a two-branch architecture, including the reconstruction and editing branches, which significantly enhance the modeling capability of texture details and complicated backgrounds. Concretely, we enforce several consistency regularizers and losses during the score estimation. The resulting gradients thus inject appropriate guidance to the intermediate latents, forcing the model to preserve the original background details and protagonists' appearances without interfering with the motion modification. Experiments demonstrate the competitive motion editing ability of MotionFollower qualitatively and quantitatively. Compared with MotionEditor, the most advanced motion editing model, MotionFollower achieves an approximately 80% reduction in GPU memory while delivering superior motion editing performance and exclusively supporting large camera movements and actions.
Synthesize, Diagnose, and Optimize: Towards Fine-Grained Vision-Language Understanding
Nov 30, 2023



Vision language models (VLM) have demonstrated remarkable performance across various downstream tasks. However, understanding fine-grained visual-linguistic concepts, such as attributes and inter-object relationships, remains a significant challenge. While several benchmarks aim to evaluate VLMs in finer granularity, their primary focus remains on the linguistic aspect, neglecting the visual dimension. Here, we highlight the importance of evaluating VLMs from both a textual and visual perspective. We introduce a progressive pipeline to synthesize images that vary in a specific attribute while ensuring consistency in all other aspects. Utilizing this data engine, we carefully design a benchmark, SPEC, to diagnose the comprehension of object size, position, existence, and count. Subsequently, we conduct a thorough evaluation of four leading VLMs on SPEC. Surprisingly, their performance is close to random guess, revealing significant limitations. With this in mind, we propose a simply yet effective approach to optimize VLMs in fine-grained understanding, achieving significant improvements on SPEC without compromising the zero-shot performance. Results on two additional fine-grained benchmarks also show consistent improvements, further validating the transferability of our approach.