 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSAVBench: Towards Comprehensive and Reliable Evaluation of Multi-Shot Audio-Video Generation
May 19, 2026Video generation is rapidly evolving from single-shot synthesis to complex multi-shot audio-video (MSAV) narratives to meet real-world demands. However, evaluating such frontier models remains a fundamental challenge. Existing benchmarks are limited in scope and data diversity, and rely on rigid evaluation pipelines, preventing systematic and reliable assessment of modern MSAV models. To bridge these gaps, we introduce MSAVBench, the first comprehensive benchmark and adaptive hybrid evaluation framework for multi-shot audio-video generation. Our benchmark spans four key dimensions, video, audio, shot, and reference, covering diverse task settings, varying shot counts of up to 15, and challenging non-realistic scenarios. Our evaluation framework improves robustness through an adaptive self-correction mechanism for shot segmentation, instance-wise rubrics for subjective metrics, and tool-grounded evidence extraction for complex judgments. Furthermore, MSAVBench achieves high alignment with human judgments, reaching a Spearman rank correlation of 91.5%. Our systematic evaluation of 19 state-of-the-art closed- and open-source models shows that current systems still struggle with director-level control and fine-grained audio-visual synchronization, while modular or agentic generation pipelines offer a promising path toward narrowing the gap between open- and closed-source models. We will release the benchmark data and evaluation code to facilitate future research.
DiffusionOPD: A Unified Perspective of On-Policy Distillation in Diffusion Models
May 14, 2026Reinforcement learning has emerged as a powerful tool for improving diffusion-based text-to-image models, but existing methods are largely limited to single-task optimization. Extending RL to multiple tasks is challenging: joint optimization suffers from cross-task interference and imbalance, while cascade RL is cumbersome and prone to catastrophic forgetting. We propose DiffusionOPD, a new multi-task training paradigm for diffusion models based on Online Policy Distillation (OPD). DiffusionOPD first trains task-specific teachers independently, then distills their capabilities into a unified student along the student own rollout trajectories. This decouples single-task exploration from multi-task integration and avoids the optimization burden of solving all tasks jointly from scratch. Theoretically, we lift the OPD framework from discrete tokens to continuous-state Markov processes, deriving a closed-form per-step KL objective that unifies both stochastic SDE and deterministic ODE refinement via mean-matching. We formally and empirically demonstrate that this analytic gradient provides lower variance and better generality compared to conventional PPO-style policy gradients. Extensive experiments show that DiffusionOPD consistently surpasses both multi-reward RL and cascade RL baselines in training efficiency and final performance, while achieving state-of-the-art results on all evaluated benchmarks.
AVGen-Bench: A Task-Driven Benchmark for Multi-Granular Evaluation of Text-to-Audio-Video Generation
Apr 09, 2026Text-to-Audio-Video (T2AV) generation is rapidly becoming a core interface for media creation, yet its evaluation remains fragmented. Existing benchmarks largely assess audio and video in isolation or rely on coarse embedding similarity, failing to capture the fine-grained joint correctness required by realistic prompts. We introduce AVGen-Bench, a task-driven benchmark for T2AV generation featuring high-quality prompts across 11 real-world categories. To support comprehensive assessment, we propose a multi-granular evaluation framework that combines lightweight specialist models with Multimodal Large Language Models (MLLMs), enabling evaluation from perceptual quality to fine-grained semantic controllability. Our evaluation reveals a pronounced gap between strong audio-visual aesthetics and weak semantic reliability, including persistent failures in text rendering, speech coherence, physical reasoning, and a universal breakdown in musical pitch control. Code and benchmark resources are available at http://aka.ms/avgenbench.
AIBench: Evaluating Visual-Logical Consistency in Academic Illustration Generation
Mar 31, 2026Although image generation has boosted various applications via its rapid evolution, whether the state-of-the-art models are able to produce ready-to-use academic illustrations for papers is still largely unexplored. Directly comparing or evaluating the illustration with VLM is native but requires oracle multi-modal understanding ability, which is unreliable for long and complex texts and illustrations. To address this, we propose AIBench, the first benchmark using VQA for evaluating logic correctness of the academic illustrations and VLMs for assessing aesthetics. In detail, we designed four levels of questions proposed from a logic diagram summarized from the method part of the paper, which query whether the generated illustration aligns with the paper on different scales. Our VQA-based approach raises more accurate and detailed evaluations on visual-logical consistency while relying less on the ability of the judger VLM. With our high-quality AIBench, we conduct extensive experiments and conclude that the performance gap between models on this task is significantly larger than general ones, reflecting their various complex reasoning and high-density generation ability. Further, the logic and aesthetics are hard to optimize simultaneously as in handcrafted illustrations. Additional experiments further state that test-time scaling on both abilities significantly boosts the performance on this task.
FlashMotion: Few-Step Controllable Video Generation with Trajectory Guidance
Mar 12, 2026Recent advances in trajectory-controllable video generation have achieved remarkable progress. Previous methods mainly use adapter-based architectures for precise motion control along predefined trajectories. However, all these methods rely on a multi-step denoising process, leading to substantial time redundancy and computational overhead. While existing video distillation methods successfully distill multi-step generators into few-step, directly applying these approaches to trajectory-controllable video generation results in noticeable degradation in both video quality and trajectory accuracy. To bridge this gap, we introduce FlashMotion, a novel training framework designed for few-step trajectory-controllable video generation. We first train a trajectory adapter on a multi-step video generator for precise trajectory control. Then, we distill the generator into a few-step version to accelerate video generation. Finally, we finetune the adapter using a hybrid strategy that combines diffusion and adversarial objectives, aligning it with the few-step generator to produce high-quality, trajectory-accurate videos. For evaluation, we introduce FlashBench, a benchmark for long-sequence trajectory-controllable video generation that measures both video quality and trajectory accuracy across varying numbers of foreground objects. Experiments on two adapter architectures show that FlashMotion surpasses existing video distillation methods and previous multi-step models in both visual quality and trajectory consistency.
Tabular Incremental Inference
Jan 27, 2026Tabular data is a fundamental form of data structure. The evolution of table analysis tools reflects humanity's continuous progress in data acquisition, management, and processing. The dynamic changes in table columns arise from technological advancements, changing needs, data integration, etc. However, the standard process of training AI models on tables with fixed columns and then performing inference is not suitable for handling dynamically changed tables. Therefore, new methods are needed for efficiently handling such tables in an unsupervised manner. In this paper, we introduce a new task, Tabular Incremental Inference (TabII), which aims to enable trained models to incorporate new columns during the inference stage, enhancing the practicality of AI models in scenarios where tables are dynamically changed. Furthermore, we demonstrate that this new task can be framed as an optimization problem based on the information bottleneck theory, which emphasizes that the key to an ideal tabular incremental inference approach lies in minimizing mutual information between tabular data and representation while maximizing between representation and task labels. Under this guidance, we design a TabII method with Large Language Model placeholders and Pretrained TabAdapter to provide external knowledge and Incremental Sample Condensation blocks to condense the task-relevant information given by incremental column attributes. Experimental results across eight public datasets show that TabII effectively utilizes incremental attributes, achieving state-of-the-art performance.
FlashPortrait: 6x Faster Infinite Portrait Animation with Adaptive Latent Prediction
Dec 18, 2025Current diffusion-based acceleration methods for long-portrait animation struggle to ensure identity (ID) consistency. This paper presents FlashPortrait, an end-to-end video diffusion transformer capable of synthesizing ID-preserving, infinite-length videos while achieving up to 6x acceleration in inference speed. In particular, FlashPortrait begins by computing the identity-agnostic facial expression features with an off-the-shelf extractor. It then introduces a Normalized Facial Expression Block to align facial features with diffusion latents by normalizing them with their respective means and variances, thereby improving identity stability in facial modeling. During inference, FlashPortrait adopts a dynamic sliding-window scheme with weighted blending in overlapping areas, ensuring smooth transitions and ID consistency in long animations. In each context window, based on the latent variation rate at particular timesteps and the derivative magnitude ratio among diffusion layers, FlashPortrait utilizes higher-order latent derivatives at the current timestep to directly predict latents at future timesteps, thereby skipping several denoising steps and achieving 6x speed acceleration. Experiments on benchmarks show the effectiveness of FlashPortrait both qualitatively and quantitatively.
StableAvatar: Infinite-Length Audio-Driven Avatar Video Generation
Aug 11, 2025Current diffusion models for audio-driven avatar video generation struggle to synthesize long videos with natural audio synchronization and identity consistency. This paper presents StableAvatar, the first end-to-end video diffusion transformer that synthesizes infinite-length high-quality videos without post-processing. Conditioned on a reference image and audio, StableAvatar integrates tailored training and inference modules to enable infinite-length video generation. We observe that the main reason preventing existing models from generating long videos lies in their audio modeling. They typically rely on third-party off-the-shelf extractors to obtain audio embeddings, which are then directly injected into the diffusion model via cross-attention. Since current diffusion backbones lack any audio-related priors, this approach causes severe latent distribution error accumulation across video clips, leading the latent distribution of subsequent segments to drift away from the optimal distribution gradually. To address this, StableAvatar introduces a novel Time-step-aware Audio Adapter that prevents error accumulation via time-step-aware modulation. During inference, we propose a novel Audio Native Guidance Mechanism to further enhance the audio synchronization by leveraging the diffusion's own evolving joint audio-latent prediction as a dynamic guidance signal. To enhance the smoothness of the infinite-length videos, we introduce a Dynamic Weighted Sliding-window Strategy that fuses latent over time. Experiments on benchmarks show the effectiveness of StableAvatar both qualitatively and quantitatively.
Non-Uniform Class-Wise Coreset Selection: Characterizing Category Difficulty for Data-Efficient Transfer Learning
Apr 17, 2025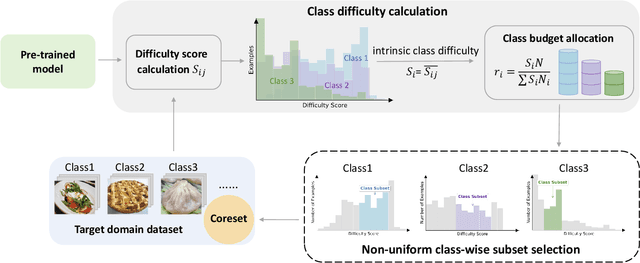
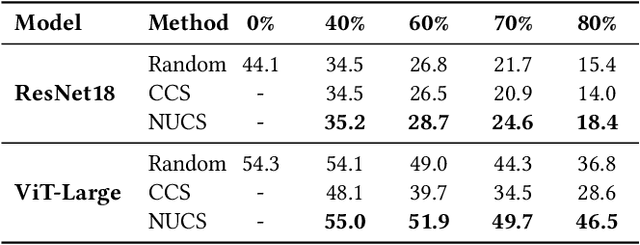
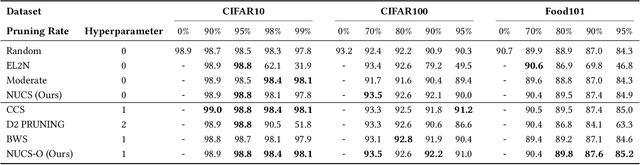
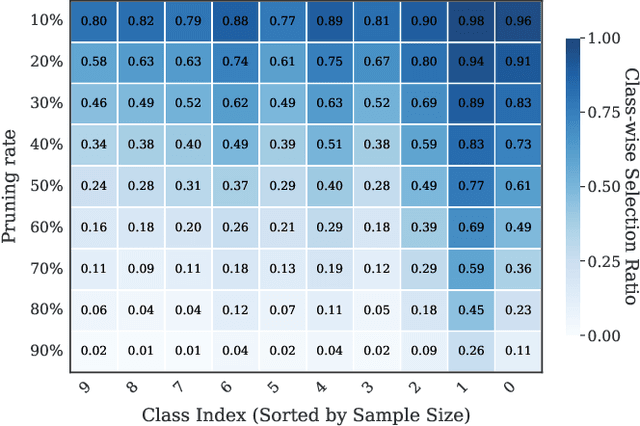
As transfer learning models and datasets grow larger, efficient adaptation and storage optimization have become critical needs. Coreset selection addresses these challenges by identifying and retaining the most informative samples, constructing a compact subset for target domain training. However, current methods primarily rely on instance-level difficulty assessments, overlooking crucial category-level characteristics and consequently under-representing minority classes. To overcome this limitation, we propose Non-Uniform Class-Wise Coreset Selection (NUCS), a novel framework that integrates both class-level and instance-level criteria. NUCS automatically allocates data selection budgets for each class based on intrinsic category difficulty and adaptively selects samples within optimal difficulty ranges. By explicitly incorporating category-specific insights, our approach achieves a more balanced and representative coreset, addressing key shortcomings of prior methods. Comprehensive theoretical analysis validates the rationale behind adaptive budget allocation and sample selection, while extensive experiments across 14 diverse datasets and model architectures demonstrate NUCS's consistent improvements over state-of-the-art methods, achieving superior accuracy and computational efficiency. Notably, on CIFAR100 and Food101, NUCS matches full-data training accuracy while retaining just 30% of samples and reducing computation time by 60%. Our work highlights the importance of characterizing category difficulty in coreset selection, offering a robust and data-efficient solution for transfer learning.
MagicMotion: Controllable Video Generation with Dense-to-Sparse Trajectory Guidance
Mar 20, 2025Recent advances in video generation have led to remarkable improvements in visual quality and temporal coherence. Upon this, trajectory-controllable video generation has emerged to enable precise object motion control through explicitly defined spatial paths. However, existing methods struggle with complex object movements and multi-object motion control, resulting in imprecise trajectory adherence, poor object consistency, and compromised visual quality. Furthermore, these methods only support trajectory control in a single format, limiting their applicability in diverse scenarios. Additionally, there is no publicly available dataset or benchmark specifically tailored for trajectory-controllable video generation, hindering robust training and systematic evaluation. To address these challenges, we introduce MagicMotion, a novel image-to-video generation framework that enables trajectory control through three levels of conditions from dense to sparse: masks, bounding boxes, and sparse boxes. Given an input image and trajectories, MagicMotion seamlessly animates objects along defined trajectories while maintaining object consistency and visual quality. Furthermore, we present MagicData, a large-scale trajectory-controlled video dataset, along with an automated pipeline for annotation and filtering. We also introduce MagicBench, a comprehensive benchmark that assesses both video quality and trajectory control accuracy across different numbers of objects. Extensive experiments demonstrate that MagicMotion outperforms previous methods across various metrics. Our project page are publicly available at https://quanhaol.github.io/magicmotion-site.