 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Laws for Data-Efficient Visual Transfer Learning
Apr 17, 2025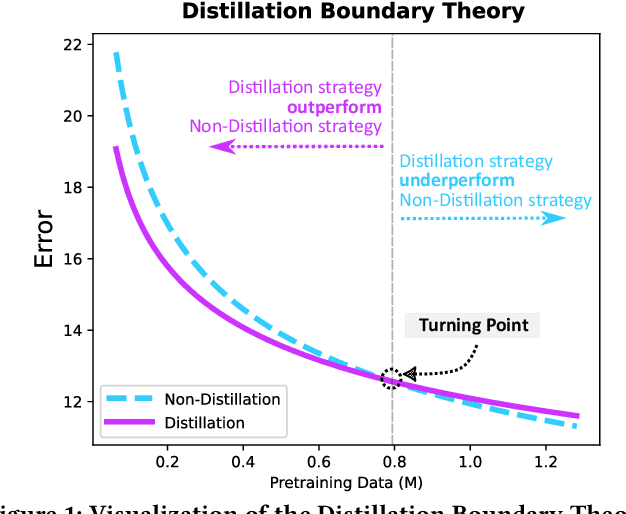
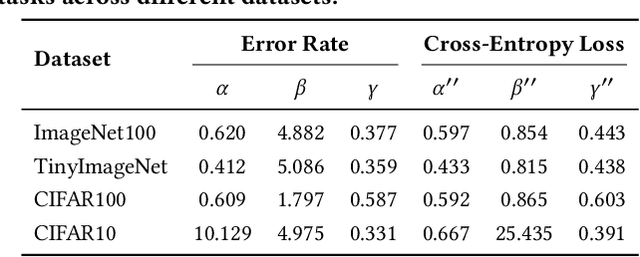
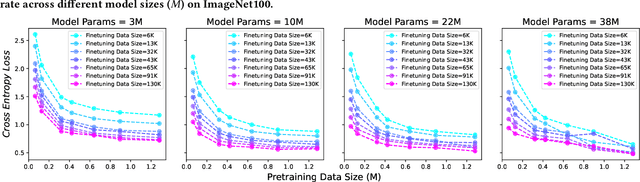
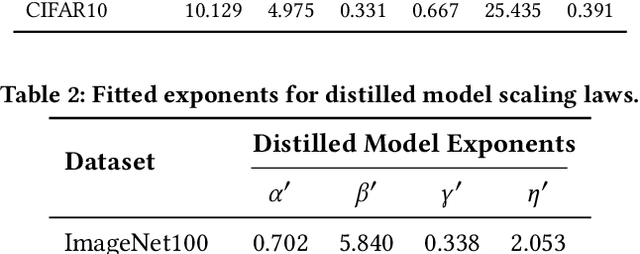
Current scaling laws for visual AI models focus predominantly on large-scale pretraining, leaving a critical gap in understanding how performance scales for data-constrained downstream tasks. To address this limitation, this paper establishes the first practical framework for data-efficient scaling laws in visual transfer learning, addressing two fundamental questions: 1) How do scaling behaviors shift when downstream tasks operate with limited data? 2) What governs the efficacy of knowledge distillation under such constraints? Through systematic analysis of vision tasks across data regimes (1K-1M samples), we propose the distillation boundary theory, revealing a critical turning point in distillation efficiency: 1) Distillation superiority: In data-scarce conditions, distilled models significantly outperform their non-distillation counterparts, efficiently leveraging inherited knowledge to compensate for limited training samples. 2) Pre-training dominance: As pre-training data increases beyond a critical threshold, non-distilled models gradually surpass distilled versions, suggesting diminishing returns from knowledge inheritance when sufficient task-specific data becomes available. Empirical validation across various model scales (2.5M to 38M parameters) and data volumes demonstrate these performance inflection points, with error difference curves transitioning from positive to negative values at critical data thresholds, confirming our theoretical predictions. This work redefines scaling laws for data-limited regimes, bridging the knowledge gap between large-scale pretraining and practical downstream adaptation, addressing a critical barrier to understanding vision model scaling behaviors and optimizing computational resource allocation.
Non-Uniform Class-Wise Coreset Selection: Characterizing Category Difficulty for Data-Efficient Transfer Learning
Apr 17, 2025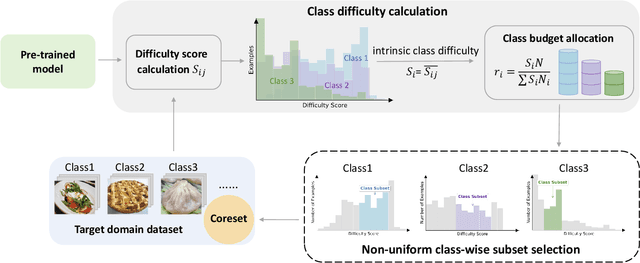
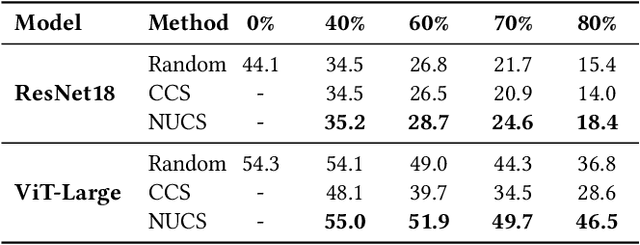
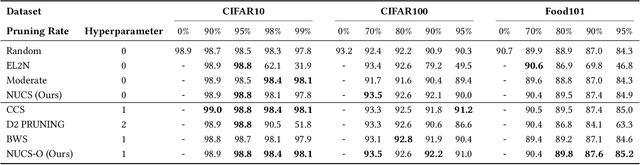
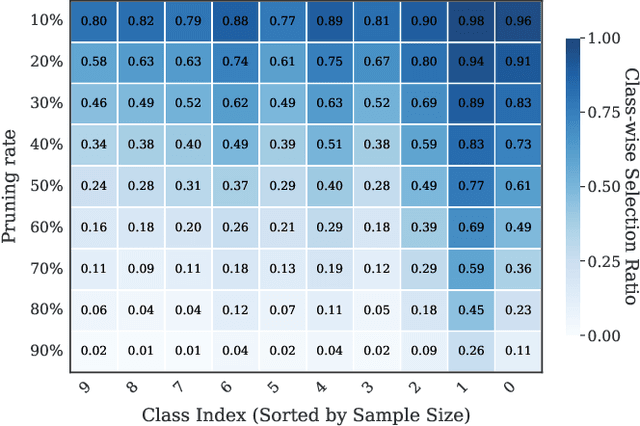
As transfer learning models and datasets grow larger, efficient adaptation and storage optimization have become critical needs. Coreset selection addresses these challenges by identifying and retaining the most informative samples, constructing a compact subset for target domain training. However, current methods primarily rely on instance-level difficulty assessments, overlooking crucial category-level characteristics and consequently under-representing minority classes. To overcome this limitation, we propose Non-Uniform Class-Wise Coreset Selection (NUCS), a novel framework that integrates both class-level and instance-level criteria. NUCS automatically allocates data selection budgets for each class based on intrinsic category difficulty and adaptively selects samples within optimal difficulty ranges. By explicitly incorporating category-specific insights, our approach achieves a more balanced and representative coreset, addressing key shortcomings of prior methods. Comprehensive theoretical analysis validates the rationale behind adaptive budget allocation and sample selection, while extensive experiments across 14 diverse datasets and model architectures demonstrate NUCS's consistent improvements over state-of-the-art methods, achieving superior accuracy and computational efficiency. Notably, on CIFAR100 and Food101, NUCS matches full-data training accuracy while retaining just 30% of samples and reducing computation time by 60%. Our work highlights the importance of characterizing category difficulty in coreset selection, offering a robust and data-efficient solution for transfer learning.
Maximizing V-information for Pre-training Superior Foundation Models
Aug 13, 2024Pre-training foundation models on large-scale datasets demonstrates exceptional performance. However, recent research questions this traditional notion, exploring whether an increase in pre-training data always leads to enhanced model performance. To address this issue, data-effective learning approaches have been introduced. However, current methods in this area lack a clear standard for sample selection. Our experiments reveal that by maximizing V-information, sample selection can be framed as an optimization problem, enabling effective improvement in model performance even with fewer samples. Under this guidance, we develop an optimal data-effective learning method (OptiDEL) to maximize V-information. The OptiDEL method generates hard samples to achieve or even exceed the performance of models trained on the full dataset while using substantially less data. We compare the OptiDEL method with state-of-the-art approaches finding that OptiDEL consistently outperforms existing approaches across different datasets, with foundation models trained on only 5% of the pre-training data surpassing the performance of those trained on the full dataset.
Data-Effective Learning: A Comprehensive Medical Benchmark
Jan 31, 2024



Data-effective learning aims to use data in the most impactful way to train AI models, which involves strategies that focus on data quality rather than quantity, ensuring the data used for training has high informational value. Data-effective learning plays a profound role in accelerating AI training, reducing computational costs, and saving data storage, which is very important as the volume of medical data in recent years has grown beyond many people's expectations. However, due to the lack of standards and comprehensive benchmark, research on medical data-effective learning is poorly studied. To address this gap, our paper introduces a comprehensive benchmark specifically for evaluating data-effective learning in the medical field. This benchmark includes a dataset with millions of data samples from 31 medical centers (DataDEL), a baseline method for comparison (MedDEL), and a new evaluation metric (NormDEL) to objectively measure data-effective learning performance. Our extensive experimental results show the baseline MedDEL can achieve performance comparable to the original large dataset with only 5% of the data. Establishing such an open data-effective learning benchmark is crucial for the medical AI research community because it facilitates efficient data use, promotes collaborative breakthroughs, and fosters the development of cost-effective, scalable, and impactful healthcare solutions. The project can be accessed at https://github.com/shadow2469/Data-Effective-Learning-A-Comprehensive-Medical-Benchmark.git.
SAMScore: A Semantic Structural Similarity Metric for Image Translation Evaluation
May 24, 2023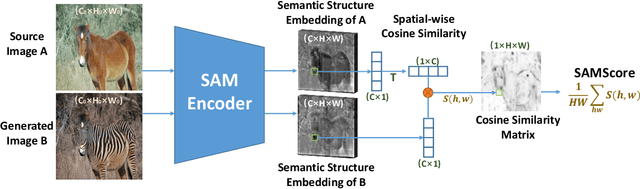


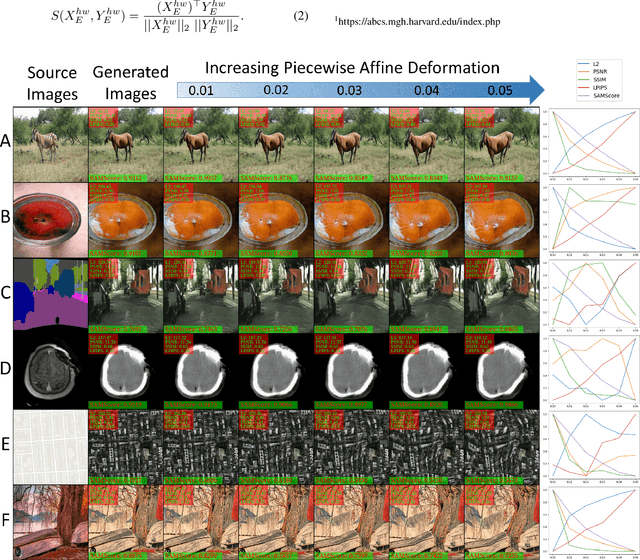
Image translation has wide applications, such as style transfer and modality conversion, usually aiming to generate images having both high degrees of realism and faithfulness. These problems remain difficult, especially when it is important to preserve semantic structures. Traditional image-level similarity metrics are of limited use, since the semantics of an image are high-level, and not strongly governed by pixel-wise faithfulness to an original image. Towards filling this gap, we introduce SAMScore, a generic semantic structural similarity metric for evaluating the faithfulness of image translation models. SAMScore is based on the recent high-performance Segment Anything Model (SAM), which can perform semantic similarity comparisons with standout accuracy. We applied SAMScore on 19 image translation tasks, and found that it is able to outperform all other competitive metrics on all of the tasks. We envision that SAMScore will prove to be a valuable tool that will help to drive the vibrant field of image translation, by allowing for more precise evaluations of new and evolving translation models. The code is available at https://github.com/Kent0n-Li/SAMScore.