 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWebGraphEval: Multi-Turn Trajectory Evaluation for Web Agents using Graph Representation
Oct 22, 2025Current evaluation of web agents largely reduces to binary success metrics or conformity to a single reference trajectory, ignoring the structural diversity present in benchmark datasets. We present WebGraphEval, a framework that abstracts trajectories from multiple agents into a unified, weighted action graph. This representation is directly compatible with benchmarks such as WebArena, leveraging leaderboard runs and newly collected trajectories without modifying environments. The framework canonically encodes actions, merges recurring behaviors, and applies structural analyses including reward propagation and success-weighted edge statistics. Evaluations across thousands of trajectories from six web agents show that the graph abstraction captures cross-model regularities, highlights redundancy and inefficiency, and identifies critical decision points overlooked by outcome-based metrics. By framing web interaction as graph-structured data, WebGraphEval establishes a general methodology for multi-path, cross-agent, and efficiency-aware evaluation of web agents.
A multimodal ensemble approach for clear cell renal cell carcinoma treatment outcome prediction
Dec 10, 2024

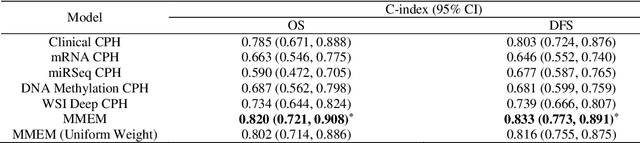
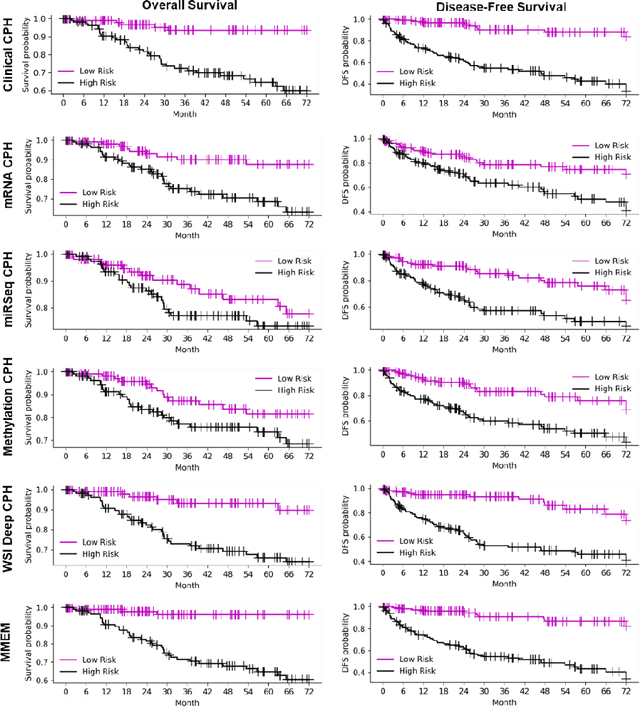
Purpose: A reliable cancer prognosis model for clear cell renal cell carcinoma (ccRCC) can enhance personalized treatment. We developed a multi-modal ensemble model (MMEM) that integrates pretreatment clinical data, multi-omics data, and histopathology whole slide image (WSI) data to predict overall survival (OS) and disease-free survival (DFS) for ccRCC patients. Methods: We analyzed 226 patients from The Cancer Genome Atlas Kidney Renal Clear Cell Carcinoma (TCGA-KIRC) dataset, which includes OS, DFS follow-up data, and five data modalities: clinical data, WSIs, and three multi-omics datasets (mRNA, miRNA, and DNA methylation). Separate survival models were built for OS and DFS. Cox-proportional hazards (CPH) model with forward feature selection is used for clinical and multi-omics data. Features from WSIs were extracted using ResNet and three general-purpose foundation models. A deep learning-based CPH model predicted survival using encoded WSI features. Risk scores from all models were combined based on training performance. Results: Performance was assessed using concordance index (C-index) and AUROC. The clinical feature-based CPH model received the highest weight for both OS and DFS tasks. Among WSI-based models, the general-purpose foundation model (UNI) achieved the best performance. The final MMEM model surpassed single-modality models, achieving C-indices of 0.820 (OS) and 0.833 (DFS), and AUROC values of 0.831 (3-year patient death) and 0.862 (cancer recurrence). Using predicted risk medians to stratify high- and low-risk groups, log-rank tests showed improved performance in both OS and DFS compared to single-modality models. Conclusion: MMEM is the first multi-modal model for ccRCC patients, integrating five data modalities. It outperformed single-modality models in prognostic ability and has the potential to assist in ccRCC patient management if independently validated.
Advancing Head and Neck Cancer Survival Prediction via Multi-Label Learning and Deep Model Interpretation
May 09, 2024A comprehensive and reliable survival prediction model is of great importance to assist in the personalized management of Head and Neck Cancer (HNC) patients treated with curative Radiation Therapy (RT). In this work, we propose IMLSP, an Interpretable Multi-Label multi-modal deep Survival Prediction framework for predicting multiple HNC survival outcomes simultaneously and provide time-event specific visual explanation of the deep prediction process. We adopt Multi-Task Logistic Regression (MTLR) layers to convert survival prediction from a regression problem to a multi-time point classification task, and to enable predicting of multiple relevant survival outcomes at the same time. We also present Grad-TEAM, a Gradient-weighted Time-Event Activation Mapping approach specifically developed for deep survival model visual explanation, to generate patient-specific time-to-event activation maps. We evaluate our method with the publicly available RADCURE HNC dataset, where it outperforms the corresponding single-modal models and single-label models on all survival outcomes. The generated activation maps show that the model focuses primarily on the tumor and nodal volumes when making the decision and the volume of interest varies for high- and low-risk patients. We demonstrate that the multi-label learning strategy can improve the learning efficiency and prognostic performance, while the interpretable survival prediction model is promising to help understand the decision-making process of AI and facilitate personalized treatment.
TransAnaNet: Transformer-based Anatomy Change Prediction Network for Head and Neck Cancer Patient Radiotherapy
May 09, 2024



Early identification of head and neck cancer (HNC) patients who would experience significant anatomical change during radiotherapy (RT) is important to optimize patient clinical benefit and treatment resources. This study aims to assess the feasibility of using a vision-transformer (ViT) based neural network to predict RT-induced anatomic change in HNC patients. We retrospectively included 121 HNC patients treated with definitive RT/CRT. We collected the planning CT (pCT), planned dose, CBCTs acquired at the initial treatment (CBCT01) and fraction 21 (CBCT21), and primary tumor volume (GTVp) and involved nodal volume (GTVn) delineated on both pCT and CBCTs for model construction and evaluation. A UNet-style ViT network was designed to learn spatial correspondence and contextual information from embedded CT, dose, CBCT01, GTVp, and GTVn image patches. The model estimated the deformation vector field between CBCT01 and CBCT21 as the prediction of anatomic change, and deformed CBCT01 was used as the prediction of CBCT21. We also generated binary masks of GTVp, GTVn, and patient body for volumetric change evaluation. The predicted image from the proposed method yielded the best similarity to the real image (CBCT21) over pCT, CBCT01, and predicted CBCTs from other comparison models. The average MSE and SSIM between the normalized predicted CBCT to CBCT21 are 0.009 and 0.933, while the average dice coefficient between body mask, GTVp mask, and GTVn mask are 0.972, 0.792, and 0.821 respectively. The proposed method showed promising performance for predicting radiotherapy-induced anatomic change, which has the potential to assist in the decision-making of HNC Adaptive RT.
SAMScore: A Semantic Structural Similarity Metric for Image Translation Evaluation
May 24, 2023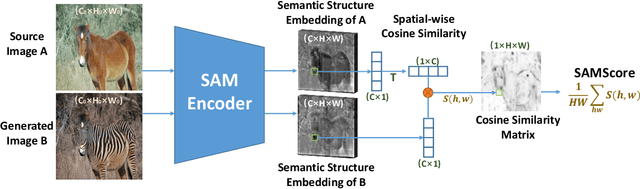


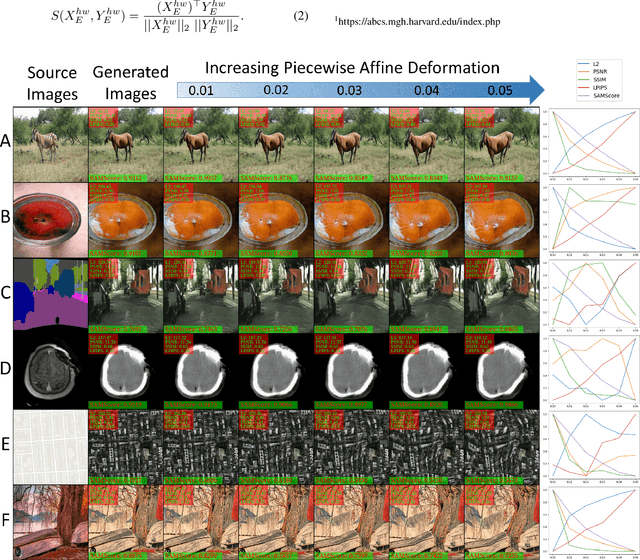
Image translation has wide applications, such as style transfer and modality conversion, usually aiming to generate images having both high degrees of realism and faithfulness. These problems remain difficult, especially when it is important to preserve semantic structures. Traditional image-level similarity metrics are of limited use, since the semantics of an image are high-level, and not strongly governed by pixel-wise faithfulness to an original image. Towards filling this gap, we introduce SAMScore, a generic semantic structural similarity metric for evaluating the faithfulness of image translation models. SAMScore is based on the recent high-performance Segment Anything Model (SAM), which can perform semantic similarity comparisons with standout accuracy. We applied SAMScore on 19 image translation tasks, and found that it is able to outperform all other competitive metrics on all of the tasks. We envision that SAMScore will prove to be a valuable tool that will help to drive the vibrant field of image translation, by allowing for more precise evaluations of new and evolving translation models. The code is available at https://github.com/Kent0n-Li/SAMScore.
Foveation-based Deep Video Compression without Motion Search
Mar 30, 2022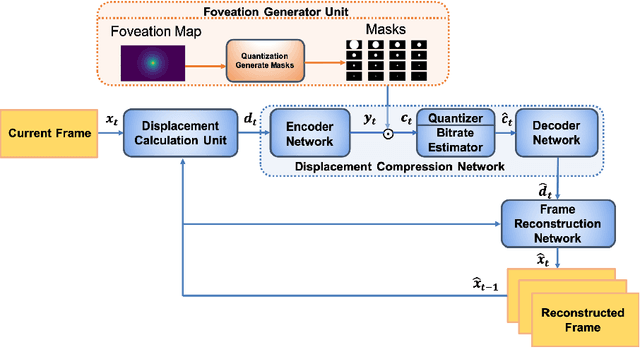
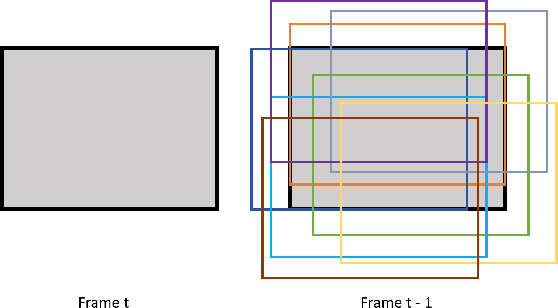

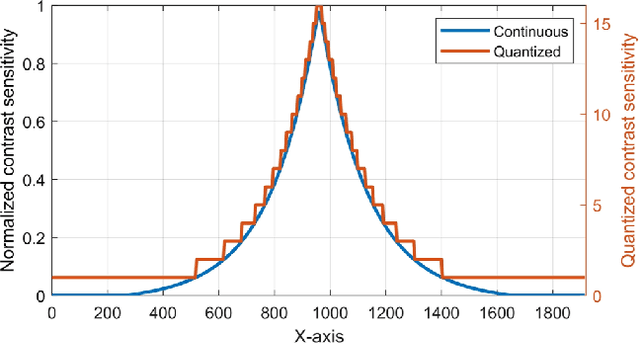
The requirements of much larger file sizes, different storage formats, and immersive viewing conditions of VR pose significant challenges to the goals of acquiring, transmitting, compressing, and displaying high-quality VR content. At the same time, the great potential of deep learning to advance progress on the video compression problem has driven a significant research effort. Because of the high bandwidth requirements of VR, there has also been significant interest in the use of space-variant, foveated compression protocols. We have integrated these techniques to create an end-to-end deep learning video compression framework. A feature of our new compression model is that it dispenses with the need for expensive search-based motion prediction computations. This is accomplished by exploiting statistical regularities inherent in video motion expressed by displaced frame differences. Foveation protocols are desirable since only a small portion of a video viewed in VR may be visible as a user gazes in any given direction. Moreover, even within a current field of view (FOV), the resolution of retinal neurons rapidly decreases with distance (eccentricity) from the projected point of gaze. In our learning based approach, we implement foveation by introducing a Foveation Generator Unit (FGU) that generates foveation masks which direct the allocation of bits, significantly increasing compression efficiency while making it possible to retain an impression of little to no additional visual loss given an appropriate viewing geometry. Our experiment results reveal that our new compression model, which we call the Foveated MOtionless VIdeo Codec (Foveated MOVI-Codec), is able to efficiently compress videos without computing motion, while outperforming foveated version of both H.264 and H.265 on the widely used UVG dataset and on the HEVC Standard Class B Test Sequences.
Learning to Compress Videos without Computing Motion
Sep 29, 2020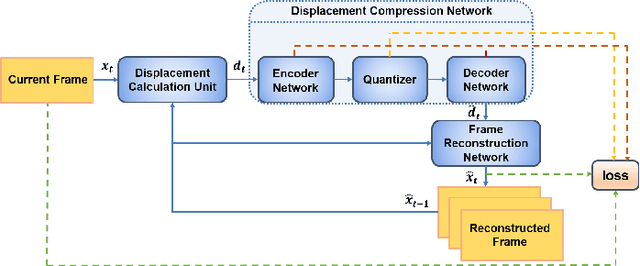

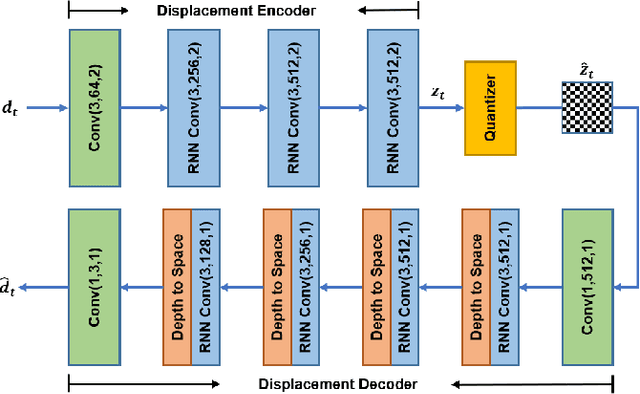
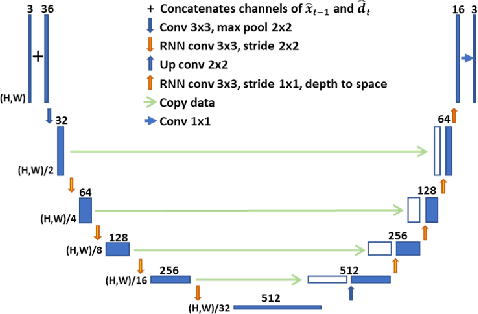
With the development of higher resolution contents and displays, its significant volume poses significant challenges to the goals of acquiring, transmitting, compressing and displaying high quality video content. In this paper, we propose a new deep learning video compression architecture that does not require motion estimation, which is the most expensive element of modern hybrid video compression codecs like H.264 and HEVC. Our framework exploits the regularities inherent to video motion, which we capture by using displaced frame differences as video representations to train the neural network. In addition, we propose a new space-time reconstruction network based on both an LSTM model and a UNet model, which we call LSTM-UNet. The combined network is able to efficiently capture both temporal and spatial video information, making it highly amenable for our purposes. The new video compression framework has three components: a Displacement Calculation Unit (DCU), a Displacement Compression Network (DCN), and a Frame Reconstruction Network (FRN), all of which are jointly optimized against a single perceptual loss function. The DCU obviates the need for motion estimation as in hybrid codecs, and is less expensive. In the DCN, an RNN-based network is utilized to conduct variable bit-rate encoding based on a single round of training. The LSTM-UNet is used in the FRN to learn space time differential representations of videos. Our experimental results show that our compression model, which we call the MOtionless VIdeo Codec (MOVI-Codec), learns how to efficiently compress videos without computing motion. Our experiments show that MOVI-Codec outperforms the video coding standard H.264, and is highly competitive with, and sometimes exceeds the performance of the modern global standard HEVC codec, as measured by MS-SSIM.