 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Compress Videos without Computing Motion
Paper and Code
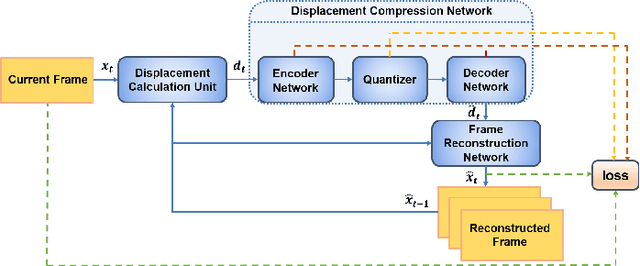

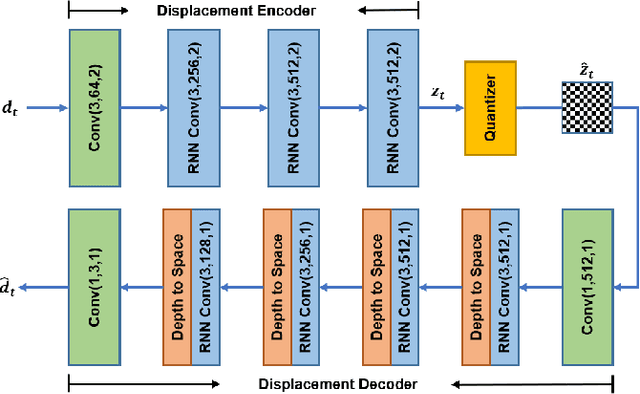
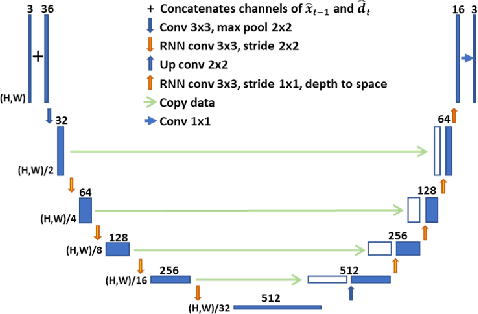
With the development of higher resolution contents and displays, its significant volume poses significant challenges to the goals of acquiring, transmitting, compressing and displaying high quality video content. In this paper, we propose a new deep learning video compression architecture that does not require motion estimation, which is the most expensive element of modern hybrid video compression codecs like H.264 and HEVC. Our framework exploits the regularities inherent to video motion, which we capture by using displaced frame differences as video representations to train the neural network. In addition, we propose a new space-time reconstruction network based on both an LSTM model and a UNet model, which we call LSTM-UNet. The combined network is able to efficiently capture both temporal and spatial video information, making it highly amenable for our purposes. The new video compression framework has three components: a Displacement Calculation Unit (DCU), a Displacement Compression Network (DCN), and a Frame Reconstruction Network (FRN), all of which are jointly optimized against a single perceptual loss function. The DCU obviates the need for motion estimation as in hybrid codecs, and is less expensive. In the DCN, an RNN-based network is utilized to conduct variable bit-rate encoding based on a single round of training. The LSTM-UNet is used in the FRN to learn space time differential representations of videos. Our experimental results show that our compression model, which we call the MOtionless VIdeo Codec (MOVI-Codec), learns how to efficiently compress videos without computing motion. Our experiments show that MOVI-Codec outperforms the video coding standard H.264, and is highly competitive with, and sometimes exceeds the performance of the modern global standard HEVC codec, as measured by MS-SSIM.