 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe VIP Gallery for Video Processing Education
Dec 29, 2020



Digital video pervades daily life. Mobile video, digital TV, and digital cinema are now ubiquitous, and as such, the field of Digital Video Processing (DVP) has experienced tremendous growth. Digital video systems also permeate scientific and engineering disciplines including but not limited to astronomy, communications, surveillance, entertainment, video coding, computer vision, and vision research. As a consequence, educational tools for DVP must cater to a large and diverse base of students. Towards enhancing DVP education we have created a carefully constructed gallery of educational tools that is designed to complement a comprehensive corpus of online lectures by providing examples of DVP on real-world content, along with a user-friendly interface that organizes numerous key DVP topics ranging from analog video, to human visual processing, to modern video codecs, etc. This demonstration gallery is currently being used effectively in the graduate class ``Digital Video'' at the University of Texas at Austin. Students receive enhanced access to concepts through both learning theory from highly visual lectures and watching concrete examples from the gallery, which captures the beauty of the underlying principles of modern video processing. To better understand the educational value of these tools, we conducted a pair of questionaire-based surveys to assess student background, expectations, and outcomes. The survey results support the teaching efficacy of this new didactic video toolset.
Learning to Compress Videos without Computing Motion
Sep 29, 2020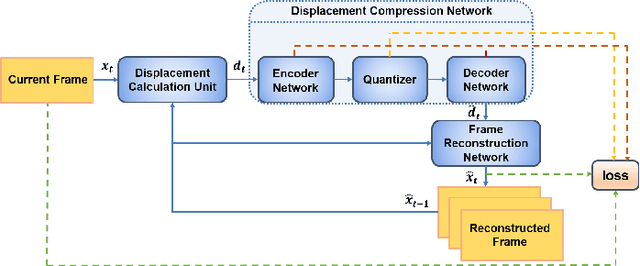

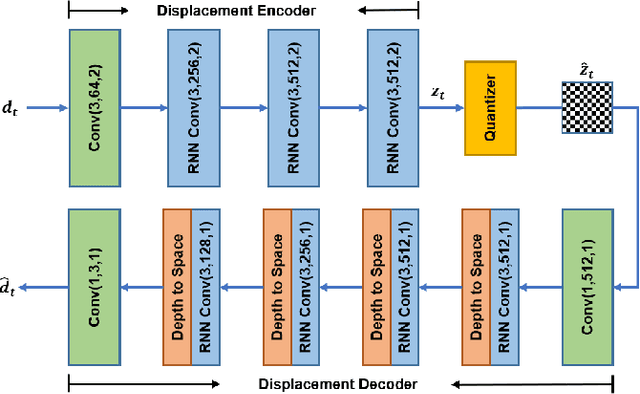
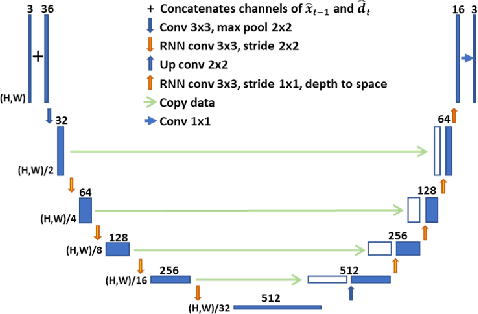
With the development of higher resolution contents and displays, its significant volume poses significant challenges to the goals of acquiring, transmitting, compressing and displaying high quality video content. In this paper, we propose a new deep learning video compression architecture that does not require motion estimation, which is the most expensive element of modern hybrid video compression codecs like H.264 and HEVC. Our framework exploits the regularities inherent to video motion, which we capture by using displaced frame differences as video representations to train the neural network. In addition, we propose a new space-time reconstruction network based on both an LSTM model and a UNet model, which we call LSTM-UNet. The combined network is able to efficiently capture both temporal and spatial video information, making it highly amenable for our purposes. The new video compression framework has three components: a Displacement Calculation Unit (DCU), a Displacement Compression Network (DCN), and a Frame Reconstruction Network (FRN), all of which are jointly optimized against a single perceptual loss function. The DCU obviates the need for motion estimation as in hybrid codecs, and is less expensive. In the DCN, an RNN-based network is utilized to conduct variable bit-rate encoding based on a single round of training. The LSTM-UNet is used in the FRN to learn space time differential representations of videos. Our experimental results show that our compression model, which we call the MOtionless VIdeo Codec (MOVI-Codec), learns how to efficiently compress videos without computing motion. Our experiments show that MOVI-Codec outperforms the video coding standard H.264, and is highly competitive with, and sometimes exceeds the performance of the modern global standard HEVC codec, as measured by MS-SSIM.