 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Overexposed Pixels Hallucination in Videos with Adaptive Reference Frame Selection
Aug 29, 2023Low dynamic range (LDR) cameras cannot deal with wide dynamic range inputs, frequently leading to local overexposure issues. We present a learning-based system to reduce these artifacts without resorting to complex acquisition mechanisms like alternating exposures or costly processing that are typical of high dynamic range (HDR) imaging. We propose a transformer-based deep neural network (DNN) to infer the missing HDR details. In an ablation study, we show the importance of using a multiscale DNN and train it with the proper cost function to achieve state-of-the-art quality. To aid the reconstruction of the overexposed areas, our DNN takes a reference frame from the past as an additional input. This leverages the commonly occurring temporal instabilities of autoexposure to our advantage: since well-exposed details in the current frame may be overexposed in the future, we use reinforcement learning to train a reference frame selection DNN that decides whether to adopt the current frame as a future reference. Without resorting to alternating exposures, we obtain therefore a causal, HDR hallucination algorithm with potential application in common video acquisition settings. Our demo video can be found at https://drive.google.com/file/d/1-r12BKImLOYCLUoPzdebnMyNjJ4Rk360/view
FOVQA: Blind Foveated Video Quality Assessment
Jun 24, 2021

Previous blind or No Reference (NR) video quality assessment (VQA) models largely rely on features drawn from natural scene statistics (NSS), but under the assumption that the image statistics are stationary in the spatial domain. Several of these models are quite successful on standard pictures. However, in Virtual Reality (VR) applications, foveated video compression is regaining attention, and the concept of space-variant quality assessment is of interest, given the availability of increasingly high spatial and temporal resolution contents and practical ways of measuring gaze direction. Distortions from foveated video compression increase with increased eccentricity, implying that the natural scene statistics are space-variant. Towards advancing the development of foveated compression / streaming algorithms, we have devised a no-reference (NR) foveated video quality assessment model, called FOVQA, which is based on new models of space-variant natural scene statistics (NSS) and natural video statistics (NVS). Specifically, we deploy a space-variant generalized Gaussian distribution (SV-GGD) model and a space-variant asynchronous generalized Gaussian distribution (SV-AGGD) model of mean subtracted contrast normalized (MSCN) coefficients and products of neighboring MSCN coefficients, respectively. We devise a foveated video quality predictor that extracts radial basis features, and other features that capture perceptually annoying rapid quality fall-offs. We find that FOVQA achieves state-of-the-art (SOTA) performance on the new 2D LIVE-FBT-FCVR database, as compared with other leading FIQA / VQA models. we have made our implementation of FOVQA available at: http://live.ece.utexas.edu/research/Quality/FOVQA.zip.
Evaluating Foveated Video Quality Using Entropic Differencing
Jun 12, 2021
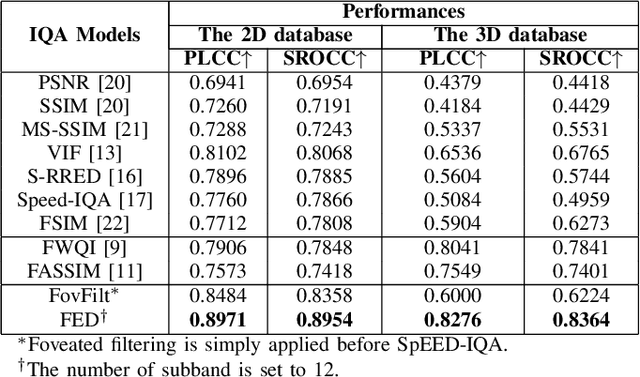
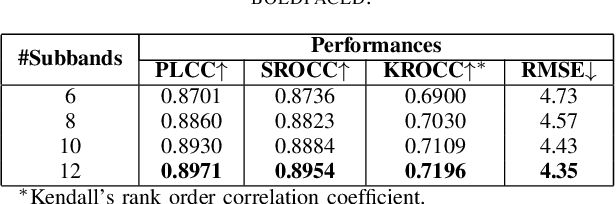

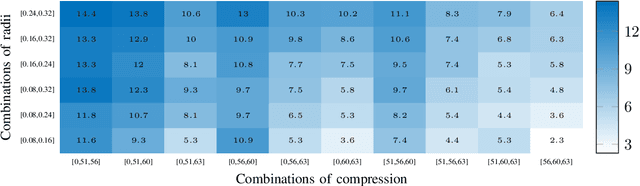
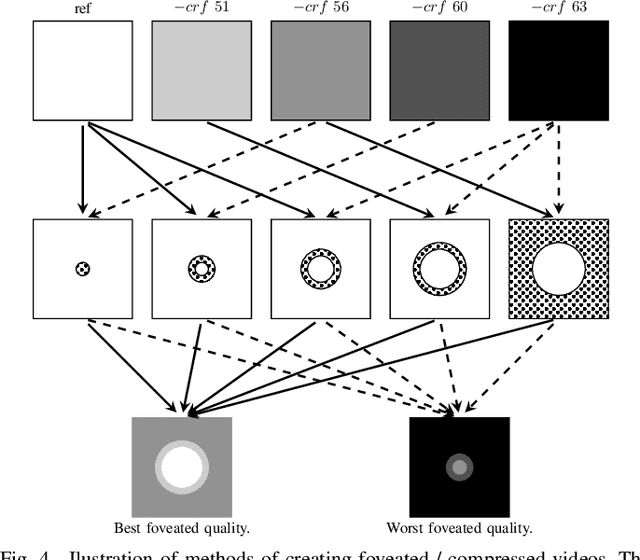
Virtual Reality is regaining attention due to recent advancements in hardware technology. Immersive images / videos are becoming widely adopted to carry omnidirectional visual information. However, due to the requirements for higher spatial and temporal resolution of real video data, immersive videos require significantly larger bandwidth consumption. To reduce stresses on bandwidth, foveated video compression is regaining popularity, whereby the space-variant spatial resolution of the retina is exploited. Towards advancing the progress of foveated video compression, we propose a full reference (FR) foveated image quality assessment algorithm, which we call foveated entropic differencing (FED), which employs the natural scene statistics of bandpass responses by applying differences of local entropies weighted by a foveation-based error sensitivity function. We evaluate the proposed algorithm by measuring the correlations of the predictions that FED makes against human judgements on the newly created 2D and 3D LIVE-FBT-FCVR databases for Virtual Reality (VR). The performance of the proposed algorithm yields state-of-the-art as compared with other existing full reference algorithms. Software for FED has been made available at: http://live.ece.utexas.edu/research/Quality/FED.zip
Learning to Compress Videos without Computing Motion
Sep 29, 2020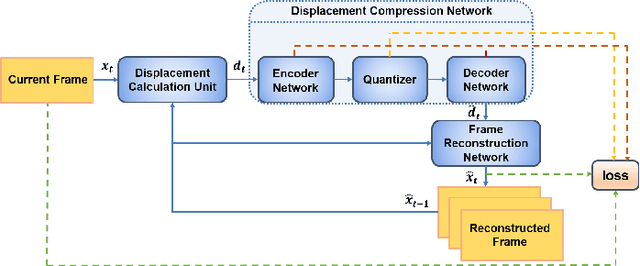

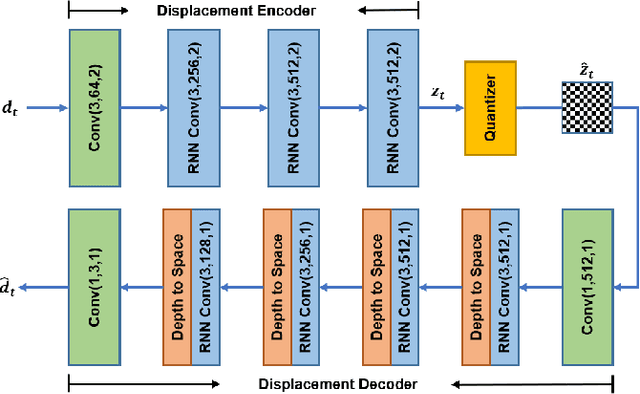
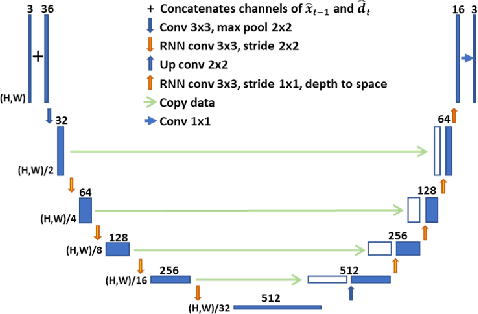
With the development of higher resolution contents and displays, its significant volume poses significant challenges to the goals of acquiring, transmitting, compressing and displaying high quality video content. In this paper, we propose a new deep learning video compression architecture that does not require motion estimation, which is the most expensive element of modern hybrid video compression codecs like H.264 and HEVC. Our framework exploits the regularities inherent to video motion, which we capture by using displaced frame differences as video representations to train the neural network. In addition, we propose a new space-time reconstruction network based on both an LSTM model and a UNet model, which we call LSTM-UNet. The combined network is able to efficiently capture both temporal and spatial video information, making it highly amenable for our purposes. The new video compression framework has three components: a Displacement Calculation Unit (DCU), a Displacement Compression Network (DCN), and a Frame Reconstruction Network (FRN), all of which are jointly optimized against a single perceptual loss function. The DCU obviates the need for motion estimation as in hybrid codecs, and is less expensive. In the DCN, an RNN-based network is utilized to conduct variable bit-rate encoding based on a single round of training. The LSTM-UNet is used in the FRN to learn space time differential representations of videos. Our experimental results show that our compression model, which we call the MOtionless VIdeo Codec (MOVI-Codec), learns how to efficiently compress videos without computing motion. Our experiments show that MOVI-Codec outperforms the video coding standard H.264, and is highly competitive with, and sometimes exceeds the performance of the modern global standard HEVC codec, as measured by MS-SSIM.
Semi-Supervised StyleGAN for Disentanglement Learning
Mar 06, 2020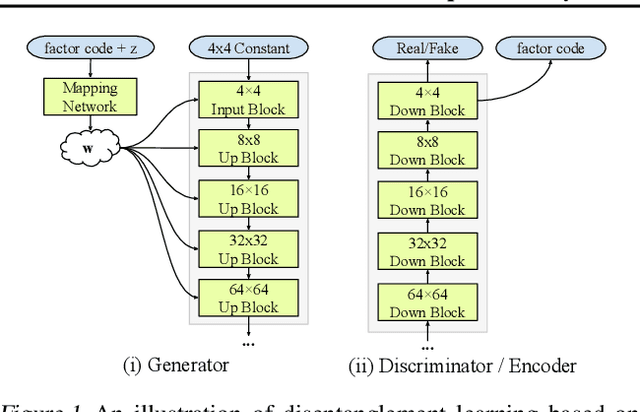


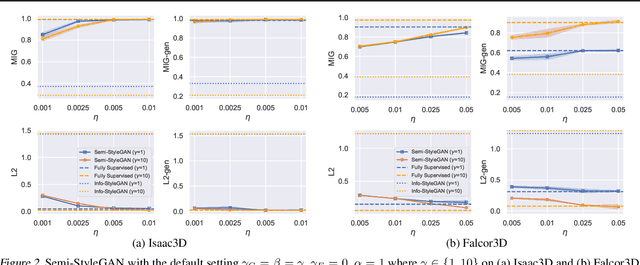
Disentanglement learning is crucial for obtaining disentangled representations and controllable generation. Current disentanglement methods face several inherent limitations: difficulty with high-resolution images, primarily on learning disentangled representations, and non-identifiability due to the unsupervised setting. To alleviate these limitations, we design new architectures and loss functions based on StyleGAN (Karras et al., 2019), for semi-supervised high-resolution disentanglement learning. We create two complex high-resolution synthetic datasets for systematic testing. We investigate the impact of limited supervision and find that using only 0.25%~2.5% of labeled data is sufficient for good disentanglement on both synthetic and real datasets. We propose new metrics to quantify generator controllability, and observe there may exist a crucial trade-off between disentangled representation learning and controllable generation. We also consider semantic fine-grained image editing to achieve better generalization to unseen images.