 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoveation-based Deep Video Compression without Motion Search
Mar 30, 2022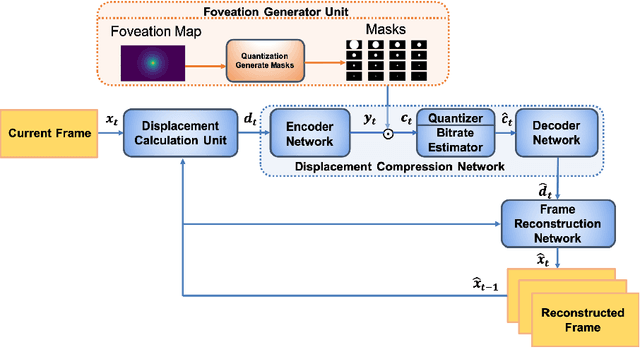

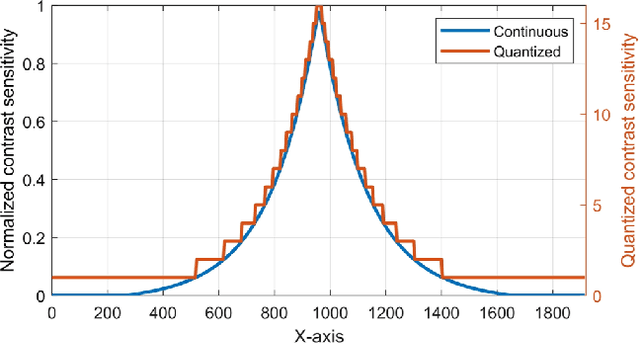
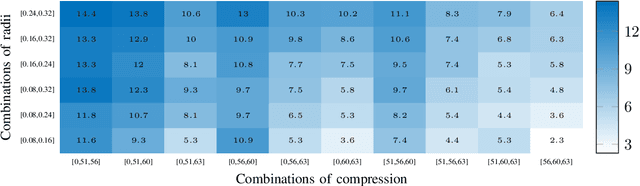
The requirements of much larger file sizes, different storage formats, and immersive viewing conditions of VR pose significant challenges to the goals of acquiring, transmitting, compressing, and displaying high-quality VR content. At the same time, the great potential of deep learning to advance progress on the video compression problem has driven a significant research effort. Because of the high bandwidth requirements of VR, there has also been significant interest in the use of space-variant, foveated compression protocols. We have integrated these techniques to create an end-to-end deep learning video compression framework. A feature of our new compression model is that it dispenses with the need for expensive search-based motion prediction computations. This is accomplished by exploiting statistical regularities inherent in video motion expressed by displaced frame differences. Foveation protocols are desirable since only a small portion of a video viewed in VR may be visible as a user gazes in any given direction. Moreover, even within a current field of view (FOV), the resolution of retinal neurons rapidly decreases with distance (eccentricity) from the projected point of gaze. In our learning based approach, we implement foveation by introducing a Foveation Generator Unit (FGU) that generates foveation masks which direct the allocation of bits, significantly increasing compression efficiency while making it possible to retain an impression of little to no additional visual loss given an appropriate viewing geometry. Our experiment results reveal that our new compression model, which we call the Foveated MOtionless VIdeo Codec (Foveated MOVI-Codec), is able to efficiently compress videos without computing motion, while outperforming foveated version of both H.264 and H.265 on the widely used UVG dataset and on the HEVC Standard Class B Test Sequences.
FOVQA: Blind Foveated Video Quality Assessment
Jun 24, 2021

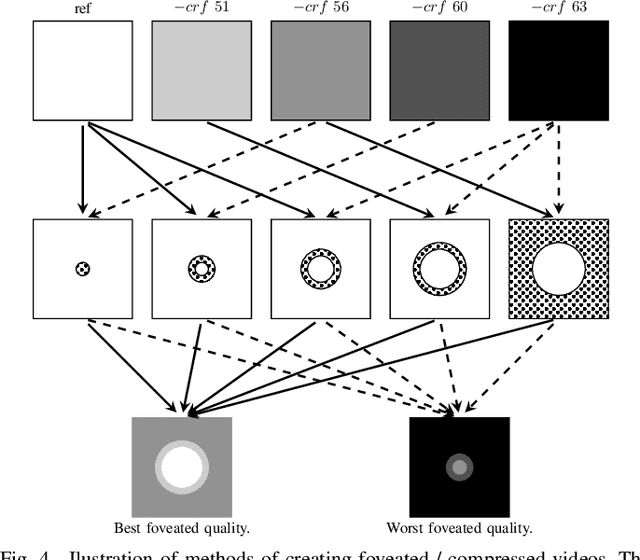
Previous blind or No Reference (NR) video quality assessment (VQA) models largely rely on features drawn from natural scene statistics (NSS), but under the assumption that the image statistics are stationary in the spatial domain. Several of these models are quite successful on standard pictures. However, in Virtual Reality (VR) applications, foveated video compression is regaining attention, and the concept of space-variant quality assessment is of interest, given the availability of increasingly high spatial and temporal resolution contents and practical ways of measuring gaze direction. Distortions from foveated video compression increase with increased eccentricity, implying that the natural scene statistics are space-variant. Towards advancing the development of foveated compression / streaming algorithms, we have devised a no-reference (NR) foveated video quality assessment model, called FOVQA, which is based on new models of space-variant natural scene statistics (NSS) and natural video statistics (NVS). Specifically, we deploy a space-variant generalized Gaussian distribution (SV-GGD) model and a space-variant asynchronous generalized Gaussian distribution (SV-AGGD) model of mean subtracted contrast normalized (MSCN) coefficients and products of neighboring MSCN coefficients, respectively. We devise a foveated video quality predictor that extracts radial basis features, and other features that capture perceptually annoying rapid quality fall-offs. We find that FOVQA achieves state-of-the-art (SOTA) performance on the new 2D LIVE-FBT-FCVR database, as compared with other leading FIQA / VQA models. we have made our implementation of FOVQA available at: http://live.ece.utexas.edu/research/Quality/FOVQA.zip.