 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDMESR: Dual-view MLLM-based Enhancing Framework for Multimodal Sequential Recommendation
Feb 14, 2026Sequential Recommender Systems (SRS) aim to predict users' next interaction based on their historical behaviors, while still facing the challenge of data sparsity. With the rapid advancement of Multimodal Large Language Models (MLLMs), leveraging their multimodal understanding capabilities to enrich item semantic representation has emerged as an effective enhancement strategy for SRS. However, existing MLLM-enhanced recommendation methods still suffer from two key limitations. First, they struggle to effectively align multimodal representations, leading to suboptimal utilization of semantic information across modalities. Second, they often overly rely on MLLM-generated content while overlooking the fine-grained semantic cues contained in the original textual data of items. To address these issues, we propose a Dual-view MLLM-based Enhancing framework for multimodal Sequential Recommendation (DMESR). For the misalignment issue, we employ a contrastive learning mechanism to align the cross-modal semantic representations generated by MLLMs. For the loss of fine-grained semantics, we introduce a cross-attention fusion module that integrates the coarse-grained semantic knowledge obtained from MLLMs with the fine-grained original textual semantics. Finally, these two fused representations can be seamlessly integrated into the downstream sequential recommendation models. Extensive experiments conducted on three real-world datasets and three popular sequential recommendation architectures demonstrate the superior effectiveness and generalizability of our proposed approach.
Data-Centric Interpretability for LLM-based Multi-Agent Reinforcement Learning
Feb 05, 2026Large language models (LLMs) are increasingly trained in complex Reinforcement Learning, multi-agent environments, making it difficult to understand how behavior changes over training. Sparse Autoencoders (SAEs) have recently shown to be useful for data-centric interpretability. In this work, we analyze large-scale reinforcement learning training runs from the sophisticated environment of Full-Press Diplomacy by applying pretrained SAEs, alongside LLM-summarizer methods. We introduce Meta-Autointerp, a method for grouping SAE features into interpretable hypotheses about training dynamics. We discover fine-grained behaviors including role-playing patterns, degenerate outputs, language switching, alongside high-level strategic behaviors and environment-specific bugs. Through automated evaluation, we validate that 90% of discovered SAE Meta-Features are significant, and find a surprising reward hacking behavior. However, through two user studies, we find that even subjectively interesting and seemingly helpful SAE features may be worse than useless to humans, along with most LLM generated hypotheses. However, a subset of SAE-derived hypotheses are predictively useful for downstream tasks. We further provide validation by augmenting an untrained agent's system prompt, improving the score by +14.2%. Overall, we show that SAEs and LLM-summarizer provide complementary views into agent behavior, and together our framework forms a practical starting point for future data-centric interpretability work on ensuring trustworthy LLM behavior throughout training.
MM-Skin: Enhancing Dermatology Vision-Language Model with an Image-Text Dataset Derived from Textbooks
May 09, 2025Medical vision-language models (VLMs) have shown promise as clinical assistants across various medical fields. However, specialized dermatology VLM capable of delivering professional and detailed diagnostic analysis remains underdeveloped, primarily due to less specialized text descriptions in current dermatology multimodal datasets. To address this issue, we propose MM-Skin, the first large-scale multimodal dermatology dataset that encompasses 3 imaging modalities, including clinical, dermoscopic, and pathological and nearly 10k high-quality image-text pairs collected from professional textbooks. In addition, we generate over 27k diverse, instruction-following vision question answering (VQA) samples (9 times the size of current largest dermatology VQA dataset). Leveraging public datasets and MM-Skin, we developed SkinVL, a dermatology-specific VLM designed for precise and nuanced skin disease interpretation. Comprehensive benchmark evaluations of SkinVL on VQA, supervised fine-tuning (SFT) and zero-shot classification tasks across 8 datasets, reveal its exceptional performance for skin diseases in comparison to both general and medical VLM models. The introduction of MM-Skin and SkinVL offers a meaningful contribution to advancing the development of clinical dermatology VLM assistants. MM-Skin is available at https://github.com/ZwQ803/MM-Skin
LLMSeR: Enhancing Sequential Recommendation via LLM-based Data Augmentation
Mar 16, 2025Sequential Recommender Systems (SRS) have become a cornerstone of online platforms, leveraging users' historical interaction data to forecast their next potential engagement. Despite their widespread adoption, SRS often grapple with the long-tail user dilemma, resulting in less effective recommendations for individuals with limited interaction records. The advent of Large Language Models (LLMs), with their profound capability to discern semantic relationships among items, has opened new avenues for enhancing SRS through data augmentation. Nonetheless, current methodologies encounter obstacles, including the absence of collaborative signals and the prevalence of hallucination phenomena.In this work, we present LLMSeR, an innovative framework that utilizes Large Language Models (LLMs) to generate pseudo-prior items, thereby improving the efficacy of Sequential Recommender Systems (SRS). To alleviate the challenge of insufficient collaborative signals, we introduce the Semantic Interaction Augmentor (SIA), a method that integrates both semantic and collaborative information to comprehensively augment user interaction data. Moreover, to weaken the adverse effects of hallucination in SRS, we develop the Adaptive Reliability Validation (ARV), a validation technique designed to assess the reliability of the generated pseudo items. Complementing these advancements, we also devise a Dual-Channel Training strategy, ensuring seamless integration of data augmentation into the SRS training process.Extensive experiments conducted with three widely-used SRS models demonstrate the generalizability and efficacy of LLMSeR.
Graph Structure Refinement with Energy-based Contrastive Learning
Dec 20, 2024



Graph Neural Networks (GNNs) have recently gained widespread attention as a successful tool for analyzing graph-structured data. However, imperfect graph structure with noisy links lacks enough robustness and may damage graph representations, therefore limiting the GNNs' performance in practical tasks. Moreover, existing generative architectures fail to fit discriminative graph-related tasks. To tackle these issues, we introduce an unsupervised method based on a joint of generative training and discriminative training to learn graph structure and representation, aiming to improve the discriminative performance of generative models. We propose an Energy-based Contrastive Learning (ECL) guided Graph Structure Refinement (GSR) framework, denoted as ECL-GSR. To our knowledge, this is the first work to combine energy-based models with contrastive learning for GSR. Specifically, we leverage ECL to approximate the joint distribution of sample pairs, which increases the similarity between representations of positive pairs while reducing the similarity between negative ones. Refined structure is produced by augmenting and removing edges according to the similarity metrics among node representations. Extensive experiments demonstrate that ECL-GSR outperforms \textit{the state-of-the-art on eight benchmark datasets} in node classification. ECL-GSR achieves \textit{faster training with fewer samples and memories} against the leading baseline, highlighting its simplicity and efficiency in downstream tasks.
Large Language Model Enhanced Recommender Systems: Taxonomy, Trend, Application and Future
Dec 18, 2024



Large Language Model (LLM) has transformative potential in various domains, including recommender systems (RS). There have been a handful of research that focuses on empowering the RS by LLM. However, previous efforts mainly focus on LLM as RS, which may face the challenge of intolerant inference costs by LLM. Recently, the integration of LLM into RS, known as LLM-Enhanced Recommender Systems (LLMERS), has garnered significant interest due to its potential to address latency and memory constraints in real-world applications. This paper presents a comprehensive survey of the latest research efforts aimed at leveraging LLM to enhance RS capabilities. We identify a critical shift in the field with the move towards incorporating LLM into the online system, notably by avoiding their use during inference. Our survey categorizes the existing LLMERS approaches into three primary types based on the component of the RS model being augmented: Knowledge Enhancement, Interaction Enhancement, and Model Enhancement. We provide an in-depth analysis of each category, discussing the methodologies, challenges, and contributions of recent studies. Furthermore, we highlight several promising research directions that could further advance the field of LLMERS.
Data-Effective Learning: A Comprehensive Medical Benchmark
Jan 31, 2024



Data-effective learning aims to use data in the most impactful way to train AI models, which involves strategies that focus on data quality rather than quantity, ensuring the data used for training has high informational value. Data-effective learning plays a profound role in accelerating AI training, reducing computational costs, and saving data storage, which is very important as the volume of medical data in recent years has grown beyond many people's expectations. However, due to the lack of standards and comprehensive benchmark, research on medical data-effective learning is poorly studied. To address this gap, our paper introduces a comprehensive benchmark specifically for evaluating data-effective learning in the medical field. This benchmark includes a dataset with millions of data samples from 31 medical centers (DataDEL), a baseline method for comparison (MedDEL), and a new evaluation metric (NormDEL) to objectively measure data-effective learning performance. Our extensive experimental results show the baseline MedDEL can achieve performance comparable to the original large dataset with only 5% of the data. Establishing such an open data-effective learning benchmark is crucial for the medical AI research community because it facilitates efficient data use, promotes collaborative breakthroughs, and fosters the development of cost-effective, scalable, and impactful healthcare solutions. The project can be accessed at https://github.com/shadow2469/Data-Effective-Learning-A-Comprehensive-Medical-Benchmark.git.
Low-latency Space-time Supersampling for Real-time Rendering
Dec 18, 2023With the rise of real-time rendering and the evolution of display devices, there is a growing demand for post-processing methods that offer high-resolution content in a high frame rate. Existing techniques often suffer from quality and latency issues due to the disjointed treatment of frame supersampling and extrapolation. In this paper, we recognize the shared context and mechanisms between frame supersampling and extrapolation, and present a novel framework, Space-time Supersampling (STSS). By integrating them into a unified framework, STSS can improve the overall quality with lower latency. To implement an efficient architecture, we treat the aliasing and warping holes unified as reshading regions and put forth two key components to compensate the regions, namely Random Reshading Masking (RRM) and Efficient Reshading Module (ERM). Extensive experiments demonstrate that our approach achieves superior visual fidelity compared to state-of-the-art (SOTA) methods. Notably, the performance is achieved within only 4ms, saving up to 75\% of time against the conventional two-stage pipeline that necessitates 17ms.
Instruct-NeuralTalker: Editing Audio-Driven Talking Radiance Fields with Instructions
Jun 19, 2023Recent neural talking radiance field methods have shown great success in photorealistic audio-driven talking face synthesis. In this paper, we propose a novel interactive framework that utilizes human instructions to edit such implicit neural representations to achieve real-time personalized talking face generation. Given a short speech video, we first build an efficient talking radiance field, and then apply the latest conditional diffusion model for image editing based on the given instructions and guiding implicit representation optimization towards the editing target. To ensure audio-lip synchronization during the editing process, we propose an iterative dataset updating strategy and utilize a lip-edge loss to constrain changes in the lip region. We also introduce a lightweight refinement network for complementing image details and achieving controllable detail generation in the final rendered image. Our method also enables real-time rendering at up to 30FPS on consumer hardware. Multiple metrics and user verification show that our approach provides a significant improvement in rendering quality compared to state-of-the-art methods.
Geometry-Aware Reference Synthesis for Multi-View Image Super-Resolution
Jul 21, 2022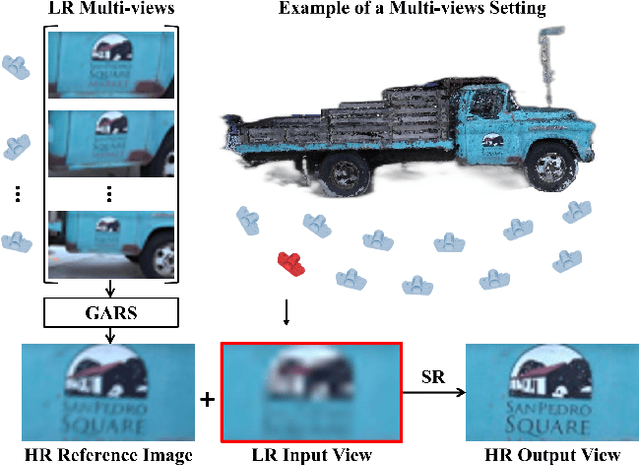
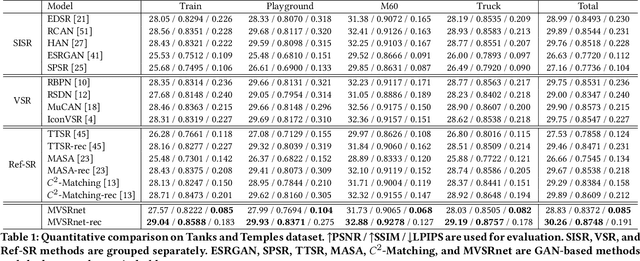

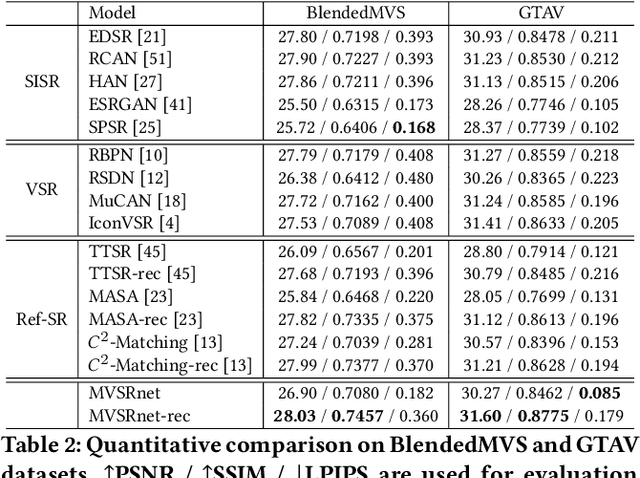
Recent multi-view multimedia applications struggle between high-resolution (HR) visual experience and storage or bandwidth constraints. Therefore, this paper proposes a Multi-View Image Super-Resolution (MVISR) task. It aims to increase the resolution of multi-view images captured from the same scene. One solution is to apply image or video super-resolution (SR) methods to reconstruct HR results from the low-resolution (LR) input view. However, these methods cannot handle large-angle transformations between views and leverage information in all multi-view images. To address these problems, we propose the MVSRnet, which uses geometry information to extract sharp details from all LR multi-view to support the SR of the LR input view. Specifically, the proposed Geometry-Aware Reference Synthesis module in MVSRnet uses geometry information and all multi-view LR images to synthesize pixel-aligned HR reference images. Then, the proposed Dynamic High-Frequency Search network fully exploits the high-frequency textural details in reference images for SR. Extensive experiments on several benchmarks show that our method significantly improves over the state-of-the-art approaches.