 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Structure Refinement with Energy-based Contrastive Learning
Dec 20, 2024



Graph Neural Networks (GNNs) have recently gained widespread attention as a successful tool for analyzing graph-structured data. However, imperfect graph structure with noisy links lacks enough robustness and may damage graph representations, therefore limiting the GNNs' performance in practical tasks. Moreover, existing generative architectures fail to fit discriminative graph-related tasks. To tackle these issues, we introduce an unsupervised method based on a joint of generative training and discriminative training to learn graph structure and representation, aiming to improve the discriminative performance of generative models. We propose an Energy-based Contrastive Learning (ECL) guided Graph Structure Refinement (GSR) framework, denoted as ECL-GSR. To our knowledge, this is the first work to combine energy-based models with contrastive learning for GSR. Specifically, we leverage ECL to approximate the joint distribution of sample pairs, which increases the similarity between representations of positive pairs while reducing the similarity between negative ones. Refined structure is produced by augmenting and removing edges according to the similarity metrics among node representations. Extensive experiments demonstrate that ECL-GSR outperforms \textit{the state-of-the-art on eight benchmark datasets} in node classification. ECL-GSR achieves \textit{faster training with fewer samples and memories} against the leading baseline, highlighting its simplicity and efficiency in downstream tasks.
BiPFT: Binary Pre-trained Foundation Transformer with Low-rank Estimation of Binarization Residual Polynomials
Dec 14, 2023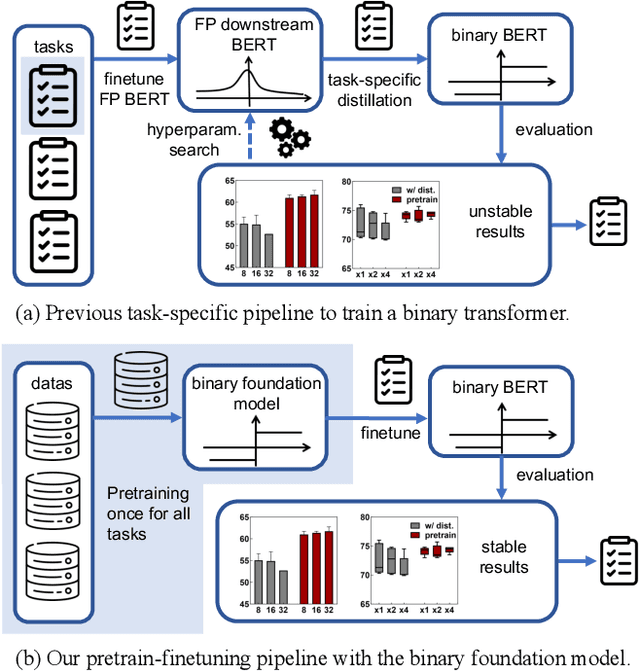
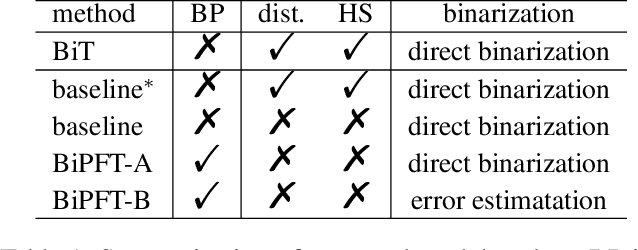
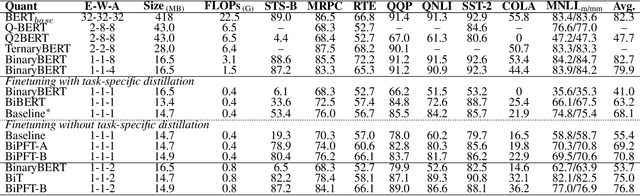
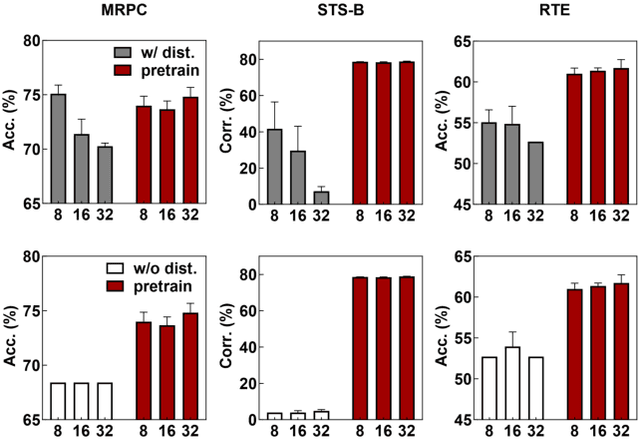
Pretrained foundation models offer substantial benefits for a wide range of downstream tasks, which can be one of the most potential techniques to access artificial general intelligence. However, scaling up foundation transformers for maximal task-agnostic knowledge has brought about computational challenges, especially on resource-limited devices such as mobiles. This work proposes the first Binary Pretrained Foundation Transformer (BiPFT) for natural language understanding (NLU) tasks, which remarkably saves 56 times operations and 28 times memory. In contrast to previous task-specific binary transformers, BiPFT exhibits a substantial enhancement in the learning capabilities of binary neural networks (BNNs), promoting BNNs into the era of pre-training. Benefiting from extensive pretraining data, we further propose a data-driven binarization method. Specifically, we first analyze the binarization error in self-attention operations and derive the polynomials of binarization error. To simulate full-precision self-attention, we define binarization error as binarization residual polynomials, and then introduce low-rank estimators to model these polynomials. Extensive experiments validate the effectiveness of BiPFTs, surpassing task-specific baseline by 15.4% average performance on the GLUE benchmark. BiPFT also demonstrates improved robustness to hyperparameter changes, improved optimization efficiency, and reduced reliance on downstream distillation, which consequently generalize on various NLU tasks and simplify the downstream pipeline of BNNs. Our code and pretrained models are publicly available at https://github.com/Xingrun-Xing/BiPFT.
An Approach for Multi-Object Tracking with Two-Stage Min-Cost Flow
Nov 05, 2023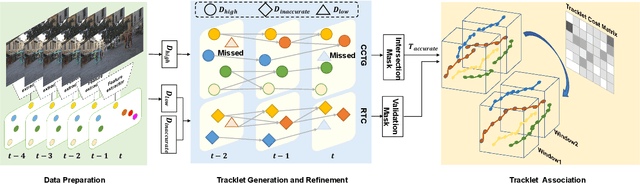
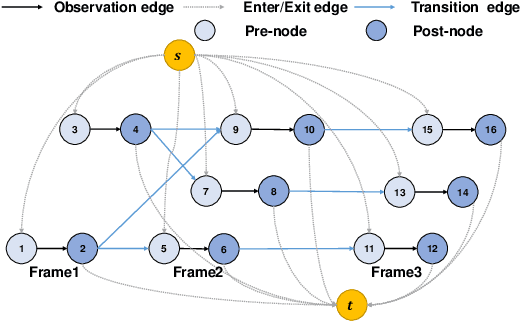
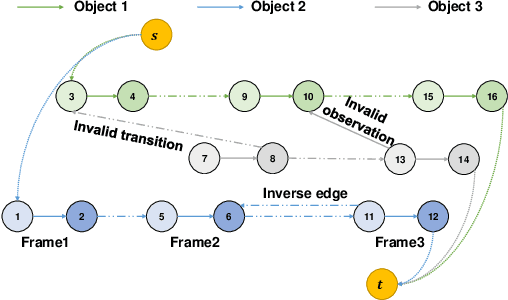

The minimum network flow algorithm is widely used in multi-target tracking. However, the majority of the present methods concentrate exclusively on minimizing cost functions whose values may not indicate accurate solutions under occlusions. In this paper, by exploiting the properties of tracklets intersections and low-confidence detections, we develop a two-stage tracking pipeline with an intersection mask that can accurately locate inaccurate tracklets which are corrected in the second stage. Specifically, we employ the minimum network flow algorithm with high-confidence detections as input in the first stage to obtain the candidate tracklets that need correction. Then we leverage the intersection mask to accurately locate the inaccurate parts of candidate tracklets. The second stage utilizes low-confidence detections that may be attributed to occlusions for correcting inaccurate tracklets. This process constructs a graph of nodes in inaccurate tracklets and low-confidence nodes and uses it for the second round of minimum network flow calculation. We perform sufficient experiments on popular MOT benchmark datasets and achieve 78.4 MOTA on the test set of MOT16, 79.2 on MOT17, and 76.4 on MOT20, which shows that the proposed method is effective.
A Hierarchical Spatio-Temporal Graph Convolutional Neural Network for Anomaly Detection in Videos
Dec 10, 2021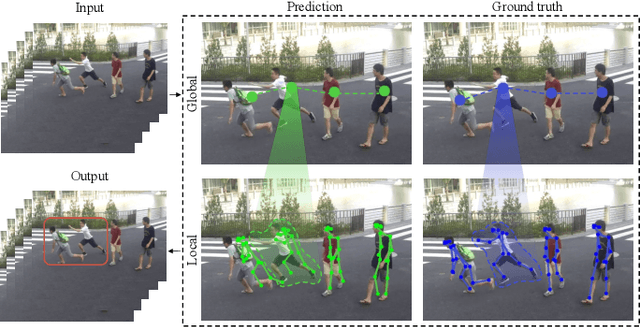
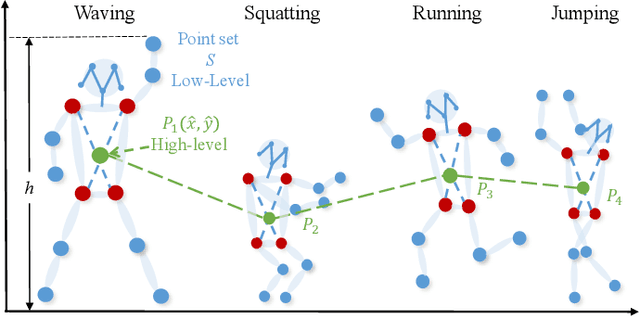

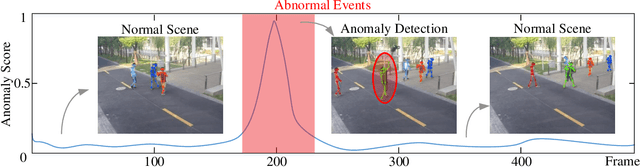
Deep learning models have been widely used for anomaly detection in surveillance videos. Typical models are equipped with the capability to reconstruct normal videos and evaluate the reconstruction errors on anomalous videos to indicate the extent of abnormalities. However, existing approaches suffer from two disadvantages. Firstly, they can only encode the movements of each identity independently, without considering the interactions among identities which may also indicate anomalies. Secondly, they leverage inflexible models whose structures are fixed under different scenes, this configuration disables the understanding of scenes. In this paper, we propose a Hierarchical Spatio-Temporal Graph Convolutional Neural Network (HSTGCNN) to address these problems, the HSTGCNN is composed of multiple branches that correspond to different levels of graph representations. High-level graph representations encode the trajectories of people and the interactions among multiple identities while low-level graph representations encode the local body postures of each person. Furthermore, we propose to weightedly combine multiple branches that are better at different scenes. An improvement over single-level graph representations is achieved in this way. An understanding of scenes is achieved and serves anomaly detection. High-level graph representations are assigned higher weights to encode moving speed and directions of people in low-resolution videos while low-level graph representations are assigned higher weights to encode human skeletons in high-resolution videos. Experimental results show that the proposed HSTGCNN significantly outperforms current state-of-the-art models on four benchmark datasets (UCSD Pedestrian, ShanghaiTech, CUHK Avenue and IITB-Corridor) by using much less learnable parameters.
Distributed stochastic proximal algorithm with random reshuffling for non-smooth finite-sum optimization
Nov 06, 2021
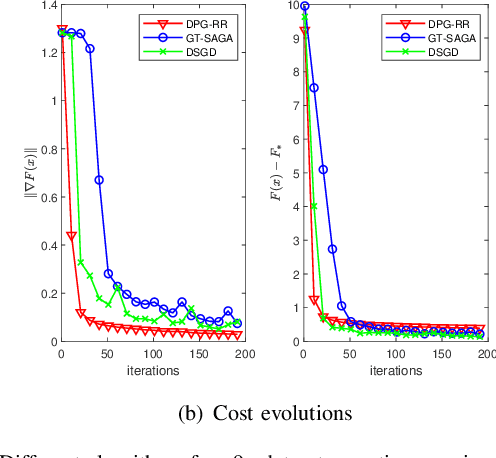
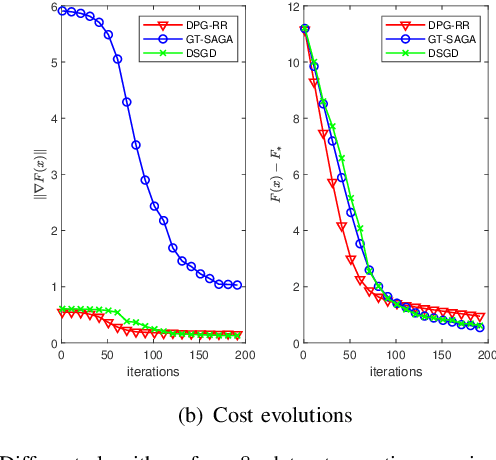
The non-smooth finite-sum minimization is a fundamental problem in machine learning. This paper develops a distributed stochastic proximal-gradient algorithm with random reshuffling to solve the finite-sum minimization over time-varying multi-agent networks. The objective function is a sum of differentiable convex functions and non-smooth regularization. Each agent in the network updates local variables with a constant step-size by local information and cooperates to seek an optimal solution. We prove that local variable estimates generated by the proposed algorithm achieve consensus and are attracted to a neighborhood of the optimal solution in expectation with an $\mathcal{O}(\frac{1}{T}+\frac{1}{\sqrt{T}})$ convergence rate. In addition, this paper shows that the steady-state error of the objective function can be arbitrarily small by choosing small enough step-sizes. Finally, some comparative simulations are provided to verify the convergence performance of the proposed algorithm.