 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP-TNseg: A Multi-Modal Hybrid Framework for Thyroid Nodule Segmentation in Ultrasound Images
Dec 07, 2024



Thyroid nodule segmentation in ultrasound images is crucial for accurate diagnosis and treatment planning. However, existing methods face challenges in segmentation accuracy, interpretability, and generalization, which hinder their performance. This letter proposes a novel framework, CLIP-TNseg, to address these issues by integrating a multimodal large model with a neural network architecture. CLIP-TNseg consists of two main branches: the Coarse-grained Branch, which extracts high-level semantic features from a frozen CLIP model, and the Fine-grained Branch, which captures fine-grained features using U-Net style residual blocks. These features are fused and processed by the prediction head to generate precise segmentation maps. CLIP-TNseg leverages the Coarse-grained Branch to enhance semantic understanding through textual and high-level visual features, while the Fine-grained Branch refines spatial details, enabling precise and robust segmentation. Extensive experiments on public and our newly collected datasets demonstrate its competitive performance. Our code and the original dataset are available at https://github.com/jayxjsun/CLIP-TNseg.
Vision-Language Models Assisted Unsupervised Video Anomaly Detection
Sep 26, 2024Video anomaly detection is a subject of great interest across industrial and academic domains due to its crucial role in computer vision applications. However, the inherent unpredictability of anomalies and the scarcity of anomaly samples present significant challenges for unsupervised learning methods. To overcome the limitations of unsupervised learning, which stem from a lack of comprehensive prior knowledge about anomalies, we propose VLAVAD (Video-Language Models Assisted Anomaly Detection). Our method employs a cross-modal pre-trained model that leverages the inferential capabilities of large language models (LLMs) in conjunction with a Selective-Prompt Adapter (SPA) for selecting semantic space. Additionally, we introduce a Sequence State Space Module (S3M) that detects temporal inconsistencies in semantic features. By mapping high-dimensional visual features to low-dimensional semantic ones, our method significantly enhance the interpretability of unsupervised anomaly detection. Our proposed approach effectively tackles the challenge of detecting elusive anomalies that are hard to discern over periods, achieving SOTA on the challenging ShanghaiTech dataset.
An Approach for Multi-Object Tracking with Two-Stage Min-Cost Flow
Nov 05, 2023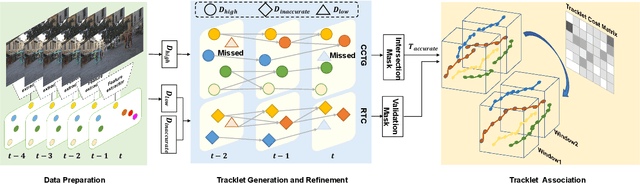
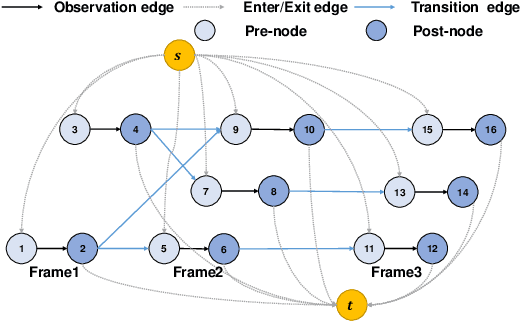
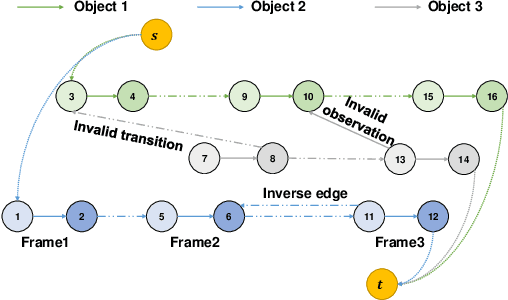

The minimum network flow algorithm is widely used in multi-target tracking. However, the majority of the present methods concentrate exclusively on minimizing cost functions whose values may not indicate accurate solutions under occlusions. In this paper, by exploiting the properties of tracklets intersections and low-confidence detections, we develop a two-stage tracking pipeline with an intersection mask that can accurately locate inaccurate tracklets which are corrected in the second stage. Specifically, we employ the minimum network flow algorithm with high-confidence detections as input in the first stage to obtain the candidate tracklets that need correction. Then we leverage the intersection mask to accurately locate the inaccurate parts of candidate tracklets. The second stage utilizes low-confidence detections that may be attributed to occlusions for correcting inaccurate tracklets. This process constructs a graph of nodes in inaccurate tracklets and low-confidence nodes and uses it for the second round of minimum network flow calculation. We perform sufficient experiments on popular MOT benchmark datasets and achieve 78.4 MOTA on the test set of MOT16, 79.2 on MOT17, and 76.4 on MOT20, which shows that the proposed method is effective.
Reasonable Anomaly Detection in Long Sequences
Sep 06, 2023Video anomaly detection is a challenging task due to the lack in approaches for representing samples. The visual representations of most existing approaches are limited by short-term sequences of observations which cannot provide enough clues for achieving reasonable detections. In this paper, we propose to completely represent the motion patterns of objects by learning from long-term sequences. Firstly, a Stacked State Machine (SSM) model is proposed to represent the temporal dependencies which are consistent across long-range observations. Then SSM model functions in predicting future states based on past ones, the divergence between the predictions with inherent normal patterns and observed ones determines anomalies which violate normal motion patterns. Extensive experiments are carried out to evaluate the proposed approach on the dataset and existing ones. Improvements over state-of-the-art methods can be observed. Our code is available at https://github.com/AllenYLJiang/Anomaly-Detection-in-Sequences.
Video Pose Track with Graph-Guided Sparse Motion Estimation
Mar 04, 2023In this paper, we propose a novel framework for multi-person pose estimation and tracking under occlusions and motion blurs. Specifically, the consistency in graph structures from consecutive frames is improved by concentrating on visible body joints and estimating the motion vectors of sparse key-points surrounding visible joints. The proposed framework involves three components: (i) A Sparse Key-point Flow Estimating Module (SKFEM) for sampling key-points from around body joints and estimating the motion vectors of key-points which contribute to the refinement of body joint locations and fine-tuning of pose estimators; (ii) A Hierarchical Graph Distance Minimizing Module (HGMM) for evaluating the visibility scores of nodes from hierarchical graphs with the visibility score of a node determining the number of samples around that node; and (iii) The combination of multiple historical frames for matching identities. Graph matching with HGMM facilitates more accurate tracking even under partial occlusions. The proposed approach not only achieves state-of-the-art performance on the PoseTrack dataset but also contributes to significant improvements in human-related anomaly detection. Besides a higher accuracy, the proposed SKFEM also shows a much higher efficiency than dense optical flow estimation.
Towards Accurate Binary Neural Networks via Modeling Contextual Dependencies
Sep 03, 2022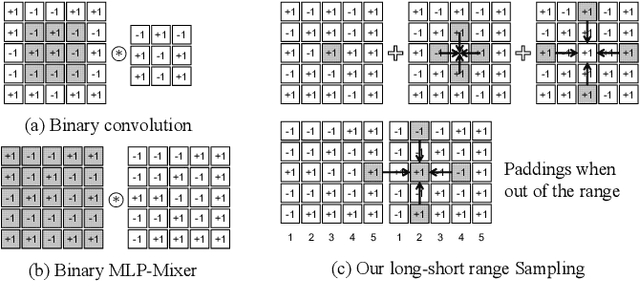
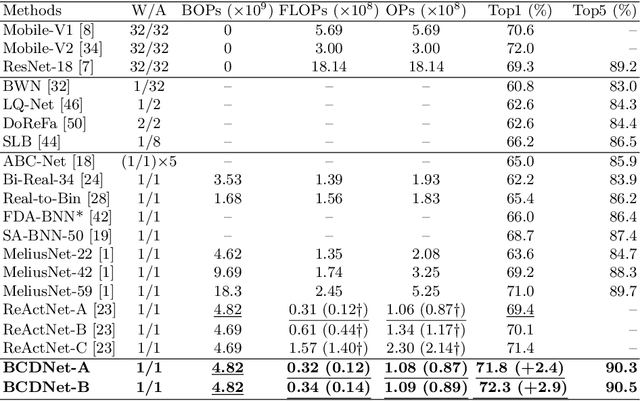
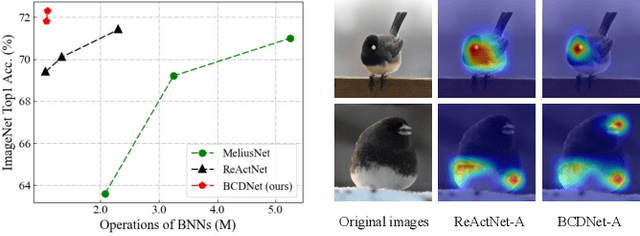
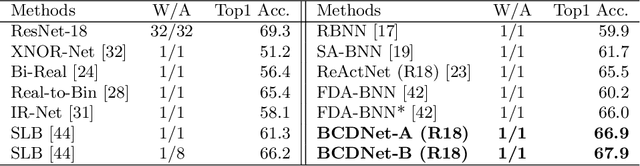
Existing Binary Neural Networks (BNNs) mainly operate on local convolutions with binarization function. However, such simple bit operations lack the ability of modeling contextual dependencies, which is critical for learning discriminative deep representations in vision models. In this work, we tackle this issue by presenting new designs of binary neural modules, which enables BNNs to learn effective contextual dependencies. First, we propose a binary multi-layer perceptron (MLP) block as an alternative to binary convolution blocks to directly model contextual dependencies. Both short-range and long-range feature dependencies are modeled by binary MLPs, where the former provides local inductive bias and the latter breaks limited receptive field in binary convolutions. Second, to improve the robustness of binary models with contextual dependencies, we compute the contextual dynamic embeddings to determine the binarization thresholds in general binary convolutional blocks. Armed with our binary MLP blocks and improved binary convolution, we build the BNNs with explicit Contextual Dependency modeling, termed as BCDNet. On the standard ImageNet-1K classification benchmark, the BCDNet achieves 72.3% Top-1 accuracy and outperforms leading binary methods by a large margin. In particular, the proposed BCDNet exceeds the state-of-the-art ReActNet-A by 2.9% Top-1 accuracy with similar operations. Our code is available at https://github.com/Sense-GVT/BCDN
A Hierarchical Spatio-Temporal Graph Convolutional Neural Network for Anomaly Detection in Videos
Dec 10, 2021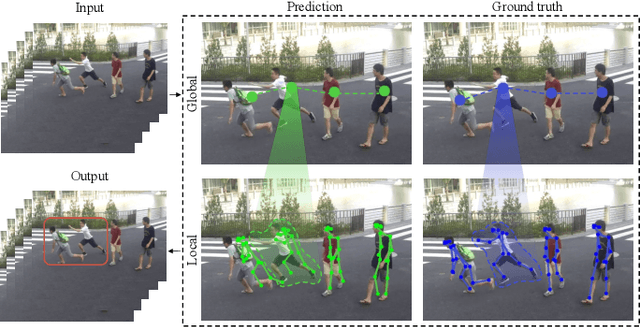
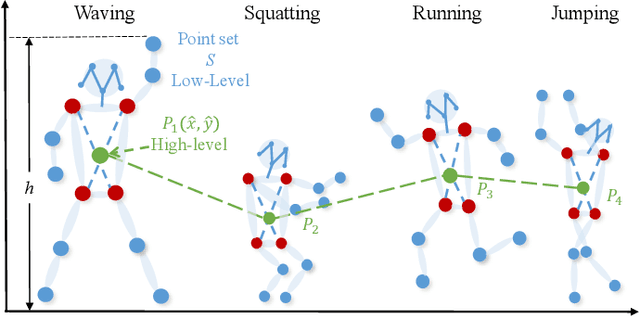

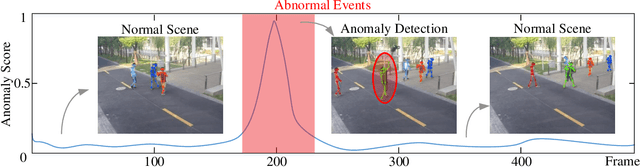
Deep learning models have been widely used for anomaly detection in surveillance videos. Typical models are equipped with the capability to reconstruct normal videos and evaluate the reconstruction errors on anomalous videos to indicate the extent of abnormalities. However, existing approaches suffer from two disadvantages. Firstly, they can only encode the movements of each identity independently, without considering the interactions among identities which may also indicate anomalies. Secondly, they leverage inflexible models whose structures are fixed under different scenes, this configuration disables the understanding of scenes. In this paper, we propose a Hierarchical Spatio-Temporal Graph Convolutional Neural Network (HSTGCNN) to address these problems, the HSTGCNN is composed of multiple branches that correspond to different levels of graph representations. High-level graph representations encode the trajectories of people and the interactions among multiple identities while low-level graph representations encode the local body postures of each person. Furthermore, we propose to weightedly combine multiple branches that are better at different scenes. An improvement over single-level graph representations is achieved in this way. An understanding of scenes is achieved and serves anomaly detection. High-level graph representations are assigned higher weights to encode moving speed and directions of people in low-resolution videos while low-level graph representations are assigned higher weights to encode human skeletons in high-resolution videos. Experimental results show that the proposed HSTGCNN significantly outperforms current state-of-the-art models on four benchmark datasets (UCSD Pedestrian, ShanghaiTech, CUHK Avenue and IITB-Corridor) by using much less learnable parameters.