 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition-Aware Depth Decay Decoding ($D^3$): Boosting Large Language Model Inference Efficiency
Mar 11, 2025



Due to the large number of parameters, the inference phase of Large Language Models (LLMs) is resource-intensive. Unlike traditional model compression, which needs retraining, recent dynamic computation methods show that not all components are required for inference, enabling a training-free pipeline. In this paper, we focus on the dynamic depth of LLM generation. A token-position aware layer skipping framework is proposed to save 1.5x times operations efficiently while maintaining performance. We first observed that tokens predicted later have lower perplexity and thus require less computation. Then, we propose a training-free algorithm called Position-Aware Depth Decay Decoding ($D^3$), which leverages a power-law decay function, $\left\lfloor L \times (\alpha^i) \right\rfloor$, to determine the number of layers to retain when generating token $T_i$. Remarkably, without any retraining, the $D^3$ achieves success across a wide range of generation tasks for the first time. Experiments on large language models (\ie the Llama) with $7 \sim 70$ billion parameters show that $D^3$ can achieve an average 1.5x speedup compared with the full-inference pipeline while maintaining comparable performance with nearly no performance drop ($<1\%$) on the GSM8K and BBH benchmarks.
EfficientLLM: Scalable Pruning-Aware Pretraining for Architecture-Agnostic Edge Language Models
Feb 10, 2025Modern large language models (LLMs) driven by scaling laws, achieve intelligence emergency in large model sizes. Recently, the increasing concerns about cloud costs, latency, and privacy make it an urgent requirement to develop compact edge language models. Distinguished from direct pretraining that bounded by the scaling law, this work proposes the pruning-aware pretraining, focusing on retaining performance of much larger optimized models. It features following characteristics: 1) Data-scalable: we introduce minimal parameter groups in LLM and continuously optimize structural pruning, extending post-training pruning methods like LLM-Pruner and SparseGPT into the pretraining phase. 2) Architecture-agnostic: the LLM architecture is auto-designed using saliency-driven pruning, which is the first time to exceed SoTA human-designed LLMs in modern pretraining. We reveal that it achieves top-quality edge language models, termed EfficientLLM, by scaling up LLM compression and extending its boundary. EfficientLLM significantly outperforms SoTA baselines with $100M \sim 1B$ parameters, such as MobileLLM, SmolLM, Qwen2.5-0.5B, OLMo-1B, Llama3.2-1B in common sense benchmarks. As the first attempt, EfficientLLM bridges the performance gap between traditional LLM compression and direct pretraining methods, and we will fully open source at https://github.com/Xingrun-Xing2/EfficientLLM.
Enhancing Generalization via Sharpness-Aware Trajectory Matching for Dataset Condensation
Feb 03, 2025



Dataset condensation aims to synthesize datasets with a few representative samples that can effectively represent the original datasets. This enables efficient training and produces models with performance close to those trained on the original sets. Most existing dataset condensation methods conduct dataset learning under the bilevel (inner- and outer-loop) based optimization. However, the preceding methods perform with limited dataset generalization due to the notoriously complicated loss landscape and expensive time-space complexity of the inner-loop unrolling of bilevel optimization. These issues deteriorate when the datasets are learned via matching the trajectories of networks trained on the real and synthetic datasets with a long horizon inner-loop. To address these issues, we introduce Sharpness-Aware Trajectory Matching (SATM), which enhances the generalization capability of learned synthetic datasets by optimising the sharpness of the loss landscape and objective simultaneously. Moreover, our approach is coupled with an efficient hypergradient approximation that is mathematically well-supported and straightforward to implement along with controllable computational overhead. Empirical evaluations of SATM demonstrate its effectiveness across various applications, including in-domain benchmarks and out-of-domain settings. Moreover, its easy-to-implement properties afford flexibility, allowing it to integrate with other advanced sharpness-aware minimizers. Our code will be released.
From Pixels to Tokens: Byte-Pair Encoding on Quantized Visual Modalities
Oct 03, 2024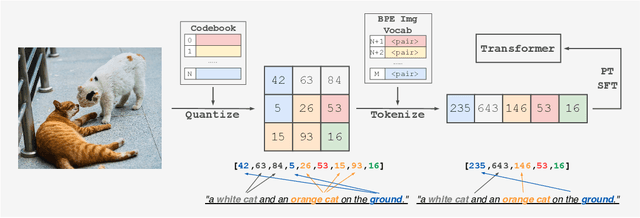
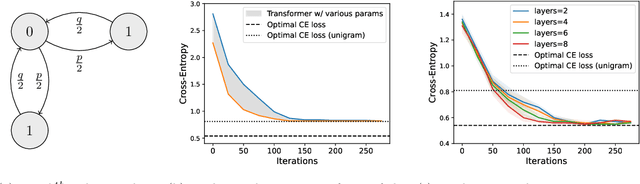
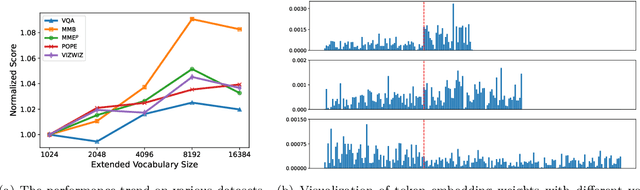
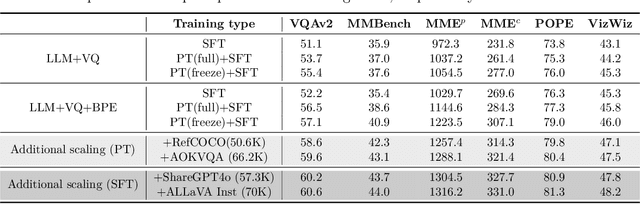
Multimodal Large Language Models have made significant strides in integrating visual and textual information, yet they often struggle with effectively aligning these modalities. We introduce a novel image tokenizer that bridges this gap by applying the principle of Byte-Pair Encoding (BPE) to visual data. Unlike conventional approaches that rely on separate visual encoders, our method directly incorporates structural prior information into image tokens, mirroring the successful tokenization strategies used in text-only Large Language Models. This innovative approach enables Transformer models to more effectively learn and reason across modalities. Through theoretical analysis and extensive experiments, we demonstrate that our BPE Image Tokenizer significantly enhances MLLMs' multimodal understanding capabilities, even with limited training data. Our method not only improves performance across various benchmarks but also shows promising scalability, potentially paving the way for more efficient and capable multimodal foundation models.
OmniGen: Unified Image Generation
Sep 17, 2024
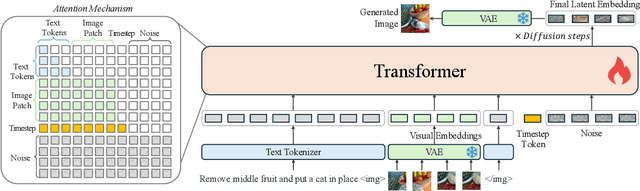
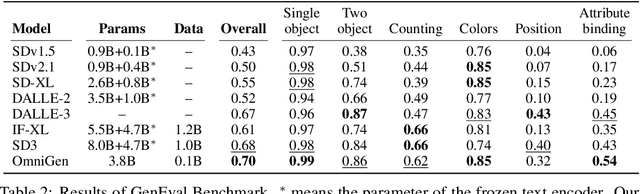

In this work, we introduce OmniGen, a new diffusion model for unified image generation. Unlike popular diffusion models (e.g., Stable Diffusion), OmniGen no longer requires additional modules such as ControlNet or IP-Adapter to process diverse control conditions. OmniGenis characterized by the following features: 1) Unification: OmniGen not only demonstrates text-to-image generation capabilities but also inherently supports other downstream tasks, such as image editing, subject-driven generation, and visual-conditional generation. Additionally, OmniGen can handle classical computer vision tasks by transforming them into image generation tasks, such as edge detection and human pose recognition. 2) Simplicity: The architecture of OmniGen is highly simplified, eliminating the need for additional text encoders. Moreover, it is more user-friendly compared to existing diffusion models, enabling complex tasks to be accomplished through instructions without the need for extra preprocessing steps (e.g., human pose estimation), thereby significantly simplifying the workflow of image generation. 3) Knowledge Transfer: Through learning in a unified format, OmniGen effectively transfers knowledge across different tasks, manages unseen tasks and domains, and exhibits novel capabilities. We also explore the model's reasoning capabilities and potential applications of chain-of-thought mechanism. This work represents the first attempt at a general-purpose image generation model, and there remain several unresolved issues. We will open-source the related resources at https://github.com/VectorSpaceLab/OmniGen to foster advancements in this field.
SpikeLLM: Scaling up Spiking Neural Network to Large Language Models via Saliency-based Spiking
Jul 05, 2024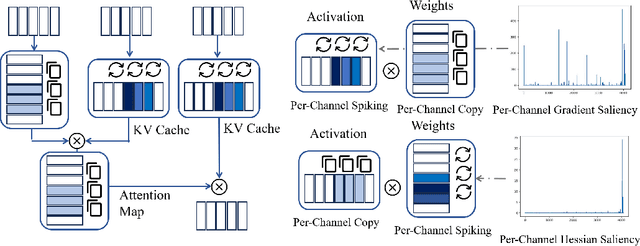
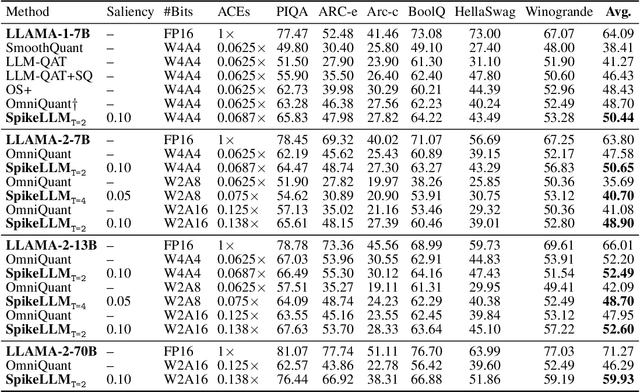

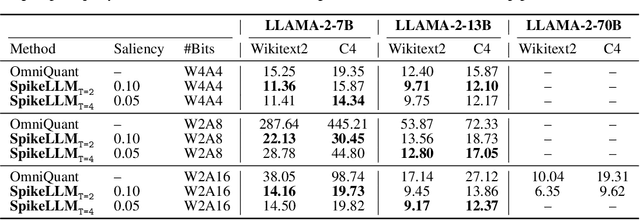
The recent advancements in large language models (LLMs) with billions of parameters have significantly boosted their performance across various real-world applications. However, the inference processes for these models require substantial energy and computational resources, presenting considerable deployment challenges. In contrast, human brains, which contain approximately 86 billion biological neurons, exhibit significantly greater energy efficiency compared to LLMs with a similar number of parameters. Inspired by this, we redesign 7 to 70 billion parameter LLMs using bio-plausible spiking mechanisms, emulating the efficient behavior of the human brain. We propose the first spiking large language model as recent LLMs termed SpikeLLM. Coupled with the proposed model, a novel spike-driven quantization framework named Optimal Brain Spiking is introduced to reduce the energy cost and accelerate inference speed via two essential approaches: first (second)-order differentiation-based salient channel detection, and per-channel salient outlier expansion with Generalized Integrate-and-Fire neurons. Our proposed spike-driven quantization can plug in main streams of quantization training methods. In the OmniQuant pipeline, SpikeLLM significantly reduces 25.51% WikiText2 perplexity and improves 3.08% average accuracy of 6 zero-shot datasets on a LLAMA2-7B 4A4W model. In the GPTQ pipeline, SpikeLLM realizes a sparse ternary quantization, which achieves additive in all linear layers. Compared with PB-LLM with similar operations, SpikeLLM also exceeds significantly. We will release our code on GitHub.
SpikeLM: Towards General Spike-Driven Language Modeling via Elastic Bi-Spiking Mechanisms
Jun 05, 2024
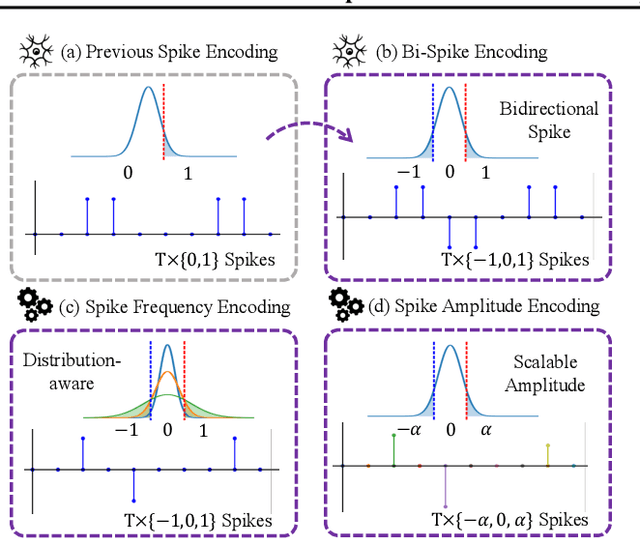
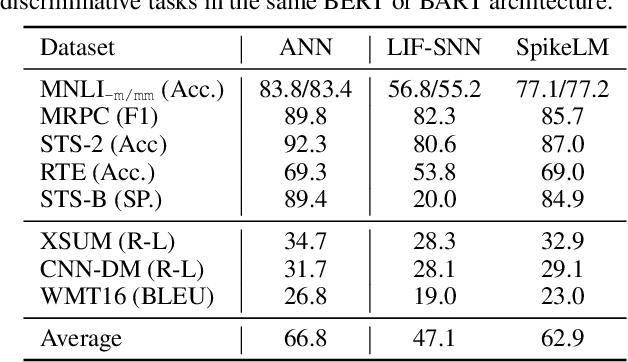
Towards energy-efficient artificial intelligence similar to the human brain, the bio-inspired spiking neural networks (SNNs) have advantages of biological plausibility, event-driven sparsity, and binary activation. Recently, large-scale language models exhibit promising generalization capability, making it a valuable issue to explore more general spike-driven models. However, the binary spikes in existing SNNs fail to encode adequate semantic information, placing technological challenges for generalization. This work proposes the first fully spiking mechanism for general language tasks, including both discriminative and generative ones. Different from previous spikes with {0,1} levels, we propose a more general spike formulation with bi-directional, elastic amplitude, and elastic frequency encoding, while still maintaining the addition nature of SNNs. In a single time step, the spike is enhanced by direction and amplitude information; in spike frequency, a strategy to control spike firing rate is well designed. We plug this elastic bi-spiking mechanism in language modeling, named SpikeLM. It is the first time to handle general language tasks with fully spike-driven models, which achieve much higher accuracy than previously possible. SpikeLM also greatly bridges the performance gap between SNNs and ANNs in language modeling. Our code is available at https://github.com/Xingrun-Xing/SpikeLM.
BiPFT: Binary Pre-trained Foundation Transformer with Low-rank Estimation of Binarization Residual Polynomials
Dec 14, 2023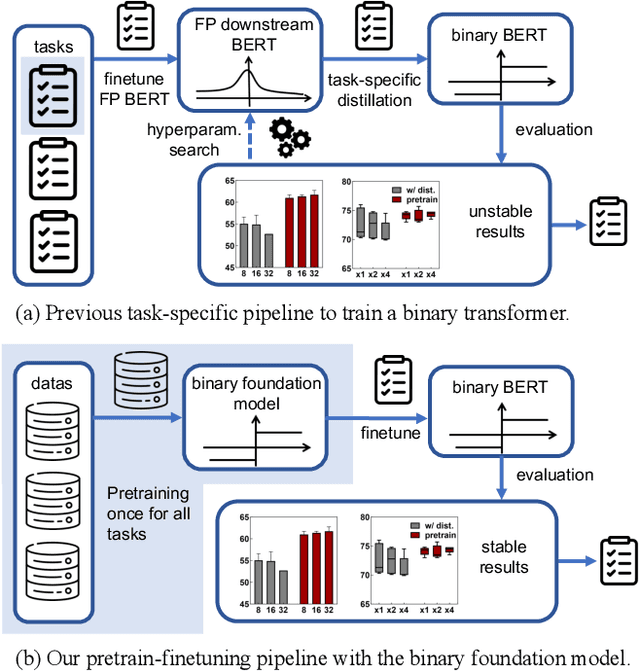
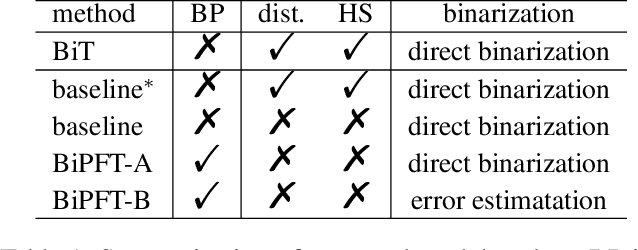
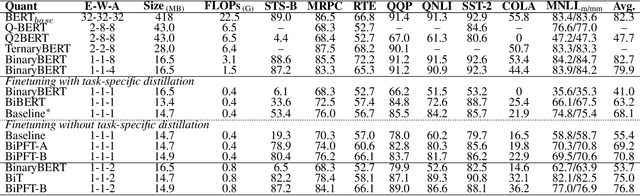
Pretrained foundation models offer substantial benefits for a wide range of downstream tasks, which can be one of the most potential techniques to access artificial general intelligence. However, scaling up foundation transformers for maximal task-agnostic knowledge has brought about computational challenges, especially on resource-limited devices such as mobiles. This work proposes the first Binary Pretrained Foundation Transformer (BiPFT) for natural language understanding (NLU) tasks, which remarkably saves 56 times operations and 28 times memory. In contrast to previous task-specific binary transformers, BiPFT exhibits a substantial enhancement in the learning capabilities of binary neural networks (BNNs), promoting BNNs into the era of pre-training. Benefiting from extensive pretraining data, we further propose a data-driven binarization method. Specifically, we first analyze the binarization error in self-attention operations and derive the polynomials of binarization error. To simulate full-precision self-attention, we define binarization error as binarization residual polynomials, and then introduce low-rank estimators to model these polynomials. Extensive experiments validate the effectiveness of BiPFTs, surpassing task-specific baseline by 15.4% average performance on the GLUE benchmark. BiPFT also demonstrates improved robustness to hyperparameter changes, improved optimization efficiency, and reduced reliance on downstream distillation, which consequently generalize on various NLU tasks and simplify the downstream pipeline of BNNs. Our code and pretrained models are publicly available at https://github.com/Xingrun-Xing/BiPFT.
LM-Cocktail: Resilient Tuning of Language Models via Model Merging
Dec 08, 2023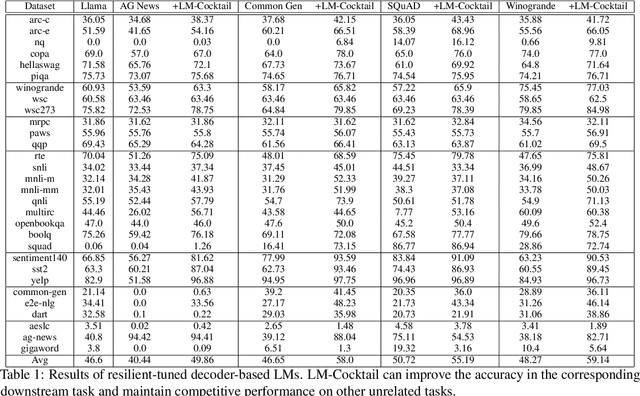
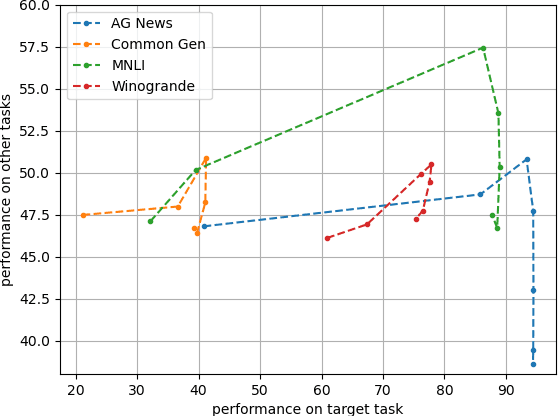
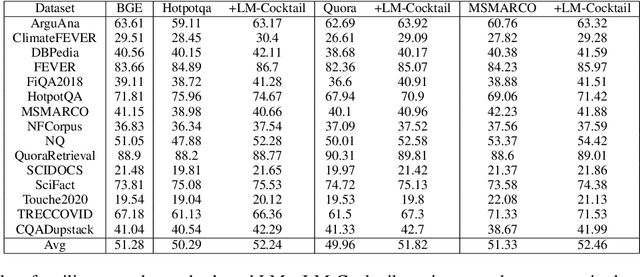
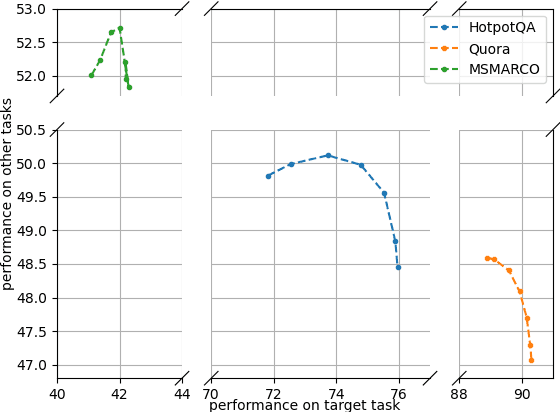
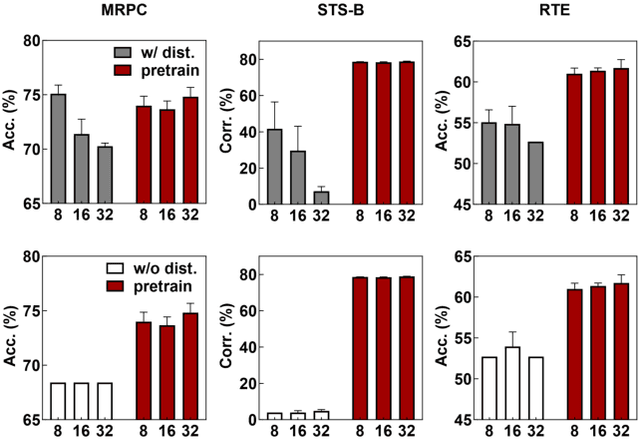
The pre-trained language models are continually fine-tuned to better support downstream applications. However, this operation may result in significant performance degeneration on general tasks beyond the targeted domain. To overcome this problem, we propose LM-Cocktail which enables the fine-tuned model to stay resilient in general perspectives. Our method is conducted in the form of model merging, where the fine-tuned language model is merged with the pre-trained base model or the peer models from other domains through weighted average. Despite simplicity, LM-Cocktail is surprisingly effective: the resulted model is able to achieve a strong empirical performance in the whole scope of general tasks while preserving a superior capacity in its targeted domain. We conduct comprehensive experiments with LLama and BGE model on popular benchmarks, including FLAN, MMLU, MTEB, whose results validate the efficacy of our proposed method. The code and checkpoints are available at https://github.com/FlagOpen/FlagEmbedding/tree/master/LM_Cocktail.
Quantifying and Attributing the Hallucination of Large Language Models via Association Analysis
Sep 11, 2023



Although demonstrating superb performance on various NLP tasks, large language models (LLMs) still suffer from the hallucination problem, which threatens the reliability of LLMs. To measure the level of hallucination of LLMs, previous works first categorize the hallucination according to the phenomenon similarity, then quantify the proportion that model outputs contain hallucinatory contents. However, such hallucination rates could easily be distorted by confounders. Moreover, such hallucination rates could not reflect the reasons for the hallucination, as similar hallucinatory phenomena may originate from different sources. To address these issues, we propose to combine the hallucination level quantification and hallucination reason investigation through an association analysis, which builds the relationship between the hallucination rate of LLMs with a set of risk factors. In this way, we are able to observe the hallucination level under each value of each risk factor, examining the contribution and statistical significance of each risk factor, meanwhile excluding the confounding effect of other factors. Additionally, by recognizing the risk factors according to a taxonomy of model capability, we reveal a set of potential deficiencies in commonsense memorization, relational reasoning, and instruction following, which may further provide guidance for the pretraining and supervised fine-tuning process of LLMs to mitigate the hallucination.